一种多端口数据源提炼优化模型及方法与流程
本发明涉及数据管理,尤其涉及一种多端口数据源提炼优化模型及方法。
背景技术:
1、数据管理技术领域旨在有效地组织、存储、保护、处理和交付数据,支持业务流程和决策制定,包括数据的整合、质量控制、处理、可视化,结合数据安全性和隐私保护,确保数据遵守法律政策并安全地存储和传输,帮助企业和管理人员从庞大和复杂的数据集中提炼关键信息,提升操作效率和决策质量,结合大数据技术和实时数据处理技术对结构化数据和非结构化数据进行处理,为用户提供及时的业务洞察。
2、其中,多端口数据源提炼优化模型旨在改进从多个数据源收集和整合数据的效率和准确性,通过多种算法和自动化技术优化数据提炼流程,减少信息冗余,提高数据的质量和相关性,使企业有效地处理来自多个端口的数据,支持复杂的分析任务,并为决策提供坚实的数据支持,在快速变化的市场环境中保持竞争力。
3、传统数据提炼技术在处理来自多个数据源的信息时面临数据质量和一致性问题,在异常数据的监测和修正方面,缺乏有效的实时分析工具,导致数据异常难以及时挖掘和处理,影响数据集的可靠性和分析结果的准确性,在数据特征的提取和标签匹配过程中,缺乏智能化支持使得数据标注和检索效率低下,减少数据的可用性和企业的决策效率,在面对批量非结构化数据时,数据标注不准确和检索路径冗长,导致资源浪费和错误决策,缺乏对数据特征间依赖关系的分析,降低复杂数据环境中提取关键信息的效率,减少数据分析的深度和广度,影响企业在竞争中的表现。
技术实现思路
1、本发明的目的是解决现有技术中存在的缺点,而提出的一种多端口数据源提炼优化模型及方法。
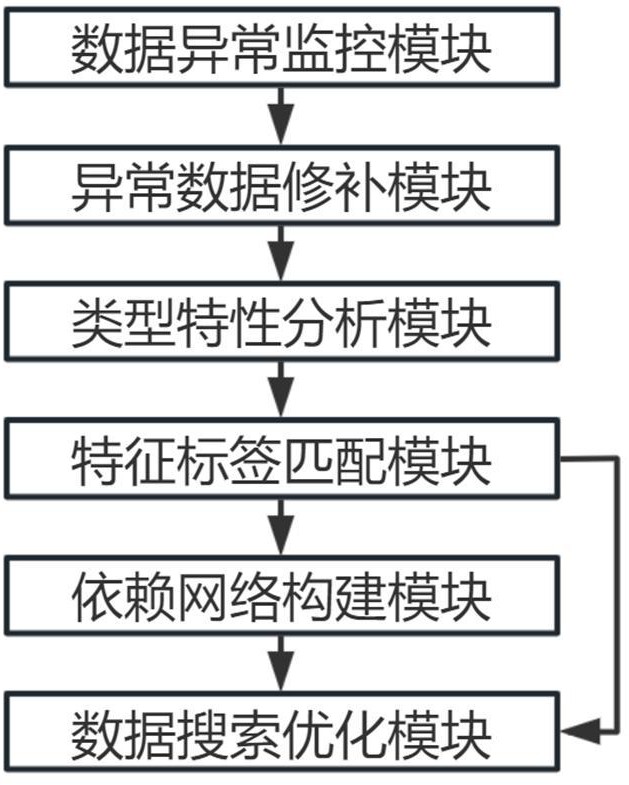
2、为了实现上述目的,本发明采用了如下技术方案,一种多端口数据源提炼优化模型包括:
3、数据异常监控模块基于多端口实时数据集,对数据中的多个数据点进行连续性分析,并与设定的正常波动模式进行对比,生成异常数据识别信息;
4、异常数据修补模块接收所述异常数据识别信息,分析多个异常数据点的时间序列关系,对缺失和错误数据进行插值补充,生成数据插值补充结果;
5、类型特性分析模块基于所述数据插值补充结果,分析多个数据的类型,并提取数据特征,生成数据特征提取信息;
6、特征标签匹配模块根据所述数据特征提取信息,对多个数据进行语义分析,为数据特征分配数据标签,生成描述标签分配结果;
7、依赖网络构建模块利用所述描述标签分配结果,分析多个数据特征间的条件依赖关系,分析多种数据特征间的直接和间接效应,生成特征关联分析结果;
8、数据搜索优化模块采用所述特征关联分析结果和描述标签分配结果,为多个数据标签匹配索引条目,结合数据查询频率和数据访问模式,优化查询路径和数据访问结构,生成数据检索优化模型。
9、作为本发明的进一步方案,所述异常数据识别信息包括异常时间点、异常数据值、异常类型描述信息,所述数据插值补充结果包括数据序列补充结果、修正数据点数量信息、数据连续性改进信息,所述数据特征提取信息包括视觉特征向量、文本关键词频率表、时间序列波动模式描述结果,所述描述标签分配结果包括特征与标签映射表、标签分类信息、标签应用范围信息,所述特征关联分析结果包括条件依赖图、特征间影响力评分数据、数据因果链信息,所述数据检索优化模型包括索引结构更新结果、查询算法优化参数、检索效率统计数据。
10、作为本发明的进一步方案,所述数据异常监控模块包括:
11、数据监测输出子模块基于多端口实时数据集,对数据中的多个数据点进行连续性分析,评估多个数据点与邻近数据点的时间和数值差异,生成数据点分析结果;
12、异常波动分析子模块利用所述数据点分析结果,通过将数据点的波动情况和预设的正常波动模式进行对比,识别异常数据点,生成波动差异记录;
13、数据异常诊断子模块基于所述波动差异记录,分析并记录偏离正常数据波动范围的数据点,生成异常数据识别信息。
14、作为本发明的进一步方案,所述异常数据修补模块包括:
15、连续性分析子模块接收所述异常数据识别信息,分析多个异常数据点间的时间序列关系,评估异常数据点的分布和连续性,生成时间序列分析结果;
16、插值参数分析子模块基于所述时间序列分析结果,根据数据点间的时间间隔和值的连续性,为异常数据和错误数据匹配插值方法,生成数据修补匹配参数;
17、缺失数据处理子模块采用所述数据修补匹配参数,对缺失和错误数据进行插值补充,优化数据完整性和连续性,生成数据插值补充结果。
18、作为本发明的进一步方案,所述类型特性分析模块包括:
19、数据分类识别子模块接收所述数据插值补充结果,对数据集中的多类数据进行分类和标识,为多种数据匹配处理流程,生成数据类型分析结果;
20、多数据提取分析子模块基于所述数据类型分析结果,对多种类型的数据进行特征分析,包括对图像数据提取视觉特征、对文本数据提取语义特征、对时间序列数据提取趋势特征,生成特征分析记录;
21、关联性分析子模块整合所述特征分析记录,对多种数据的特征进行分析,识别多种数据和特征间的相互依赖关系和关联性,生成数据特征提取信息。
22、作为本发明的进一步方案,所述特征标签匹配模块包括:
23、语义解析输出子模块接收所述数据特征提取信息,对特征描述进行语义分析,识别数据特征中的关键词汇和核心概念,生成特征语义分析结果;
24、数据标签构建子模块基于所述特征语义分析结果,结合多种数据特征中的关键元素和概念,为多个关键特征构建数据描述和检索标签,生成关键特征识别信息;
25、索引标签匹配子模块采用所述关键特征识别信息,对多个关键特征匹配数据标签,结合特征间的逻辑和语义联系补充标签,优化数据搜索的效率,生成描述标签分配结果。
26、作为本发明的进一步方案,所述依赖网络构建模块包括:
27、数据关系分析子模块接收所述描述标签分配结果,分析多个数据特征和标签间的依赖关系,识别数据间的关联性,生成依赖关系识别信息;
28、关系影响评估子模块基于所述依赖关系识别信息,计算数据特征间直接和间接的影响效应,评估数据特征间的影响强度,生成影响效应量化结果;
29、数据网络构建子模块采用所述影响效应量化结果,构建多个数据的影响关系网络,利用皮尔逊相关系数方法,分析并记录多个数据间的相互作用,生成特征关联分析结果。
30、作为本发明的进一步方案,所述皮尔逊相关系数方法,按照公式:
31、;
32、计算两个数据间的关联性,其中,为两个变量的相关系数,为数据集中第个观测点对应于变量的值,为数据集中第个观测点对应于变量的值,为变量所有观测值的平均值,为变量所有观测值的平均值,为用于调整变量平均值的因子,为用于调整变量平均值的因子,为用于调整变量标准偏差的因子,为用于调整变量标准偏差的因子,为用于指代数据集中的具体观测点的序号,为一组数据集中的第一个变量,为与平行的第二组数据变量,为变量和间的相关性度量。
33、作为本发明的进一步方案,所述数据搜索优化模块包括:
34、索引条目分析子模块利用所述特征关联分析结果和描述标签分配结果,为多种数据特征和标签匹配索引条目,优化数据访问路径,生成数据索引匹配记录;
35、数据索引优化子模块基于所述数据索引匹配记录,分析多个数据的查询频率和访问模式,对索引条目进行调整,优化数据访问的效率和响应速度,生成查询索引调整结果;
36、查询路径分析子模块采用所述查询索引调整结果,分析当前数据访问路径的效率并识别瓶颈和低效环节,优化数据查询路径和访问结构,生成数据检索优化模型。
37、一种多端口数据源提炼优化方法,所述多端口数据源提炼优化方法基于上述多端口数据源提炼优化模型执行,包括以下步骤:
38、s1:基于多端口实时数据集,对多个数据点进行监测,并与预设的正常波动模式对比,识别偏离常规的数据点,生成异常信息处理列表;
39、s2:接收所述异常信息处理列表,应用时间序列分析技术,对异常数据点进行分析,对缺失和错误数据进行插值补充,生成插值数据处理结果;
40、s3:基于所述插值数据处理结果,对多种数据进行处理,包括图像数据提取视觉特征,文本数据提取语义特征,生成多数据分类信息;
41、s4:基于所述多数据分类信息,使用语义分析技术对提取的特征进行标签化,并分析多个数据间的关联性和相互影响,生成数据关联网络;
42、s5:采用所述数据关联网络,结合数据查询频率和数据访问模式,优化数据库的索引机制和查询路径,生成数据检索优化模型。
43、与现有技术相比,本发明的优点和积极效果在于:
44、本发明中,通过实时监控数据集中的多个数据点,进行连续性分析与正常波动模式的对比,有效识别异常数据,结合对错误和缺失数据的插值补充,增强数据的完整性和准确性,对补充后数据的类型特性进行分析并提取特征,增强数据的可用性和解析性,使数据特征更为明晰,通过对目标数据特征的进行语义分析和数据标签的匹配,增强数据的组织结构和易检索性,并揭示数据特征间的依赖关系,通过优化查询路径和数据访问结构,提高数据检索的速度和效率,确保信息获取的及时性,提高了数据处理的效率和决策的质量,使企业能够在快速变化的市场环境中保持竞争力。
- 还没有人留言评论。精彩留言会获得点赞!