基于IPFS和区块链的联邦学习模型去中心化学习方法
本发明涉及模型训练,具体涉及一种基于ipfs和区块链的联邦学习模型去中心化学习方法。
背景技术:
1、联邦学习是一个机器学习框架,能有效帮助多个机构在满足用户隐私保护、数据安全和法规的要求下,进行数据使用和机器学习建模。
2、现有的联邦学习算法需要将数据传入中心化服务器进行计算,仍然有数据泄漏的风险,目前,有研究提出了使用区块链技术进行联邦学习以达到去中心化的目的,但是,该方案需要在区块链中存储联邦学习模型的参数,限制了当前联邦学习系统的可扩展性。
技术实现思路
1、有鉴于此,本发明提供了一种基于ipfs和区块链的联邦学习模型去中心化学习方法,以解决当前基于区块链的联邦学习的可扩展性较低的技术问题。
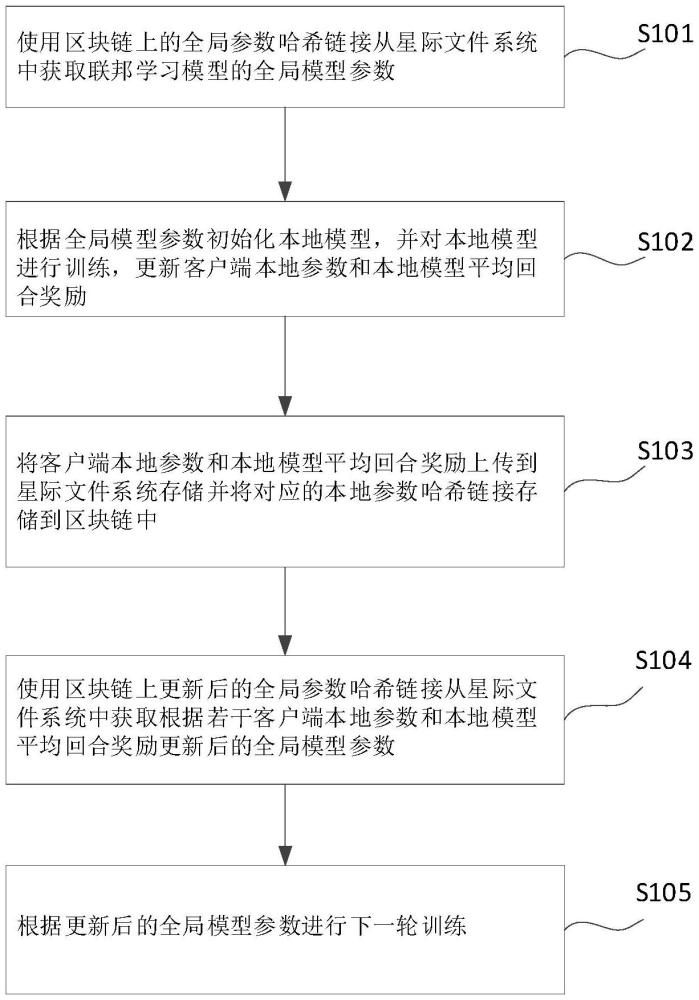
2、第一方面,本发明提供了一种基于ipfs和区块链的联邦学习模型去中心化学习方法,包括:使用区块链上的全局参数哈希链接从星际文件系统中获取联邦学习模型的全局模型参数;根据所述全局模型参数初始化本地模型,并对本地模型进行训练,更新客户端本地参数和本地模型平均回合奖励;将客户端本地参数和本地模型平均回合奖励上传到星际文件系统存储并将对应的本地参数哈希链接存储到区块链中;使用区块链上更新后的全局参数哈希链接从星际文件系统中获取根据若干客户端本地参数和本地模型平均回合奖励更新后的全局模型参数;根据更新后的全局模型参数进行下一轮训练。
3、本发明实施例的基于ipfs和区块链的联邦学习模型去中心化学习方法,通过使用区块链上的全局参数哈希链接从星际文件系统中获取联邦学习模型的全局模型参数,根据所述全局模型参数初始化本地模型,并对本地模型进行训练,更新客户端本地参数和本地模型平均回合奖励,将客户端本地参数和本地模型平均回合奖励上传到星际文件系统存储并将对应的本地参数哈希链接存储到区块链中,使用区块链上更新后的全局参数哈希链接从星际文件系统中获取根据若干客户端本地参数和本地模型平均回合奖励更新后的全局模型参数,利用ipfs进行模型参数的去中心化存储,整合区块链技术和星际文件系统以进行联邦学习,提高联邦学习的可扩展性。
4、可选地,对本地模型进行训练,更新客户端本地参数和本地模型平均回合奖励,包括:
5、使用深度强化学习对本地模型进行训练,更新客户端本地参数;
6、计算客户端本地参数对应的本地模型平均回合奖励,计算公式为:
7、
8、式中,mer(w{t,k})表示客户端本地参数获得的本地模型平均回合奖励,n表示总的回合数,w{t,k}表示客户端本地参数,ri(w{t,k})表示在第i回合中针对客户端本地参数w{t,k}所获得的奖励,t表示总的时间步数,γ表示折扣因子,r(st,at;w{t,k})表示在时间步t针对客户端本地参数所获得的即时奖励。
9、在该方式中,深度强化学习能够更有效地优化本地模型,提高模型性能,通过平均回合奖励的计算,可以量化评估客户端本地参数的贡献。
10、可选地,根据若干客户端本地参数和本地模型平均回合奖励更新全局模型参数的步骤包括:根据本地参数哈希链接从星际文件系统中获取若干更新后的客户端本地参数和本地模型平均回合奖励;判断本地模型平均回合奖励是否等于或大于全局模型平均回合奖励的比例阈值,若等于或大于全局模型平均回合奖励的比例阈值,则本地模型平均回合奖励对应的客户端本地参数为有效参数;根据上传有效参数的区块链节点上传的本地模型平均回合奖励计算各个对应客户端本地参数的聚合权重;根据所述聚合权重以及全局模型参数和客户端本地参数的差值对全局模型参数进行更新。
11、在该方式中,对客户端本地参数进行筛选,确保只有提高性能的参数被用于全局模型的更新,通过聚合权重的计算确保了对所有有效参数的公平考虑。
12、可选地,根据本地模型平均回合奖励计算各个对应客户端本地参数的聚合权重,包括:
13、根据以下公式计算聚合权重:
14、
15、式中,aw(wt,k)表示客户端本地参数的聚合权重,τt,k表示客户端k在时间步t的参与频率,pt,k表示被选取的回合数,tct-1,k表示历史贡献值,crst,k表示和本地模型平均回合奖励对应的本地模型平均奖励分数,本地模型平均回合奖励越大则本地模型平均奖励分数越大。
16、在该方式中,聚合权重的计算量化了客户端对全局模型更新的贡献,考虑了参与频率、被选取的回合数和本地模型平均奖励分数等参数计算聚合权重,使聚合权重更加合理。
17、可选地,根据所述聚合权重以及全局模型参数和客户端本地参数的差值对全局模型参数进行更新,包括:
18、根据以下公式更新全局模型参数:
19、
20、式中,wt表示全局模型参数,wt+1表示更新后的全局模型参数,δt,k表示全局模型参数和客户端本地参数的差值,sawt表示聚合权重的总和,dt表示提供的客户端本地参数为有效参数的客户端的集合。
21、在该方式中,根据聚合权重和差值计算更新后的全局模型参数,使全局模型参数能够公平地结合各个客户端上传的客户端本地参数进行更新,解决联邦学习中的偏差和公平性问题,公平考虑所有客户端的贡献,防止任何单一客户端对全局模型产生不成比例的影响。
22、可选地,在对全局模型参数进行更新之后,还包括:将更新后的全局模型参数上传到星际文件系统存储并在区块链上更新全局参数哈希链接;基于共识机制对区块链中若干客户端上传的更新后的全局模型参数进行匹配,将匹配通过的更新后的全局模型参数对全局模型进行更新。
23、基于多数共识的机制对全局模型进行更新,增强对抗恶意行为者的鲁棒性。
24、可选地,在对全局模型进行更新之后,还包括:利用区块链中的智能合约根据全局模型参数更新过程中客户端的聚合贡献为客户端提供激励并符合恶意行为标准的客户端进行惩罚。
25、使用智能合约管理透明奖励分配并进行惩罚过程,确保机会均等、奖励公平,促进安全高效的协作学习。
26、第二方面,本发明提供了一种基于ipfs和区块链的联邦学习模型去中心化学习装置,包括:全局模型参数获取模块,用于使用区块链上的全局参数哈希链接从星际文件系统中获取联邦学习模型的全局模型参数;本地训练模块,用于根据所述全局模型参数初始化本地模型,并对本地模型进行训练,更新客户端本地参数和本地模型平均回合奖励;数据上传模块,用于将客户端本地参数和本地模型平均回合奖励上传到星际文件系统存储并将对应的本地参数哈希链接存储到区块链中;全局模型参数更新模块,用于使用区块链上更新后的全局参数哈希链接从星际文件系统中获取根据若干客户端本地参数和本地模型平均回合奖励更新后的全局模型参数;迭代模块,用于根据更新后的全局模型参数进行下一轮训练。
27、第三方面,本发明提供了一种计算机设备,包括:存储器和处理器,存储器和处理器之间互相通信连接,存储器中存储有计算机指令,处理器通过执行计算机指令,从而执行上述第一方面或其对应的任一实施方式的基于ipfs和区块链的联邦学习模型去中心化学习方法。
28、第四方面,本发明提供了一种计算机可读存储介质,该计算机可读存储介质上存储有计算机指令,计算机指令用于使计算机执行上述第一方面或其对应的任一实施方式的基于ipfs和区块链的联邦学习模型去中心化学习方法。
- 还没有人留言评论。精彩留言会获得点赞!