基于CEEMDAN-SP-CNN的海上风电机组故障诊断方法
本发明涉及海上风电机组故障诊断的,尤其是指一种基于ceemdan-sp-cnn的海上风电机组故障诊断方法。
背景技术:
1、近年来,海上风电迎来了爆炸式发展,随着海上风电装机容量稳步上升,风电机组的运行和维护问题也逐渐突出。海上风电场离岸距离远,工作环境恶劣,风电机组在运行过程中会受到复杂的波浪载荷、大风、盐雾侵蚀,导致齿轮箱、轴承等核心部件易发生损坏,故障率远高于陆上风电机组。其次,由于可及性差,且需要专门的运维船只才能出海运维,因此维修成本高,维修时间长,不但影响风电机组的发电效率,同时也会增加风电场的运维成本,降低风电场的经济效益。因此,对风电机组进行故障监测与智能诊断对提升海上风电机组的可靠性和利用率具有重要作用。
2、当前的风电场大多配置了scada和cms系统来实时监测风电机组的运行状态,为风电机组的故障诊断提供了数据基础。同时,随着人工智能技术的发展,利用机器学习和深度学习来实现智能故障诊断,准确率高,泛化能力强,具有广泛的应用前景。但是传统的单一特征量的方法仅仅挖掘单个特征量与故障之间的关联关系,忽略了风电机组多种监测量和多种特征内在之间的关联特性和时间序列特性,使得一些有效信息未能被充分挖掘。因此,基于多源多特征融合的故障诊断成为重要的研究方向。该方法需要对监测量和特征量进行筛选,选择合适的监测量及其特征,目前该方法往往依靠人为经验选择,具有较大的主观性,而且风电机组监测量多且数据量大的特点会增加筛选难度和成本。其次,由于风电机组的运行环境和工况复杂多变,数据存在噪声高、缺失、误差大等问题,数量质量不高,影响特征筛选和故障诊断的准确率。此外,一般情况下风电机组故障样本数量有限且严重不平衡,使得故障诊断模型的性能难以保证。
3、因此,如何提升数据质量降低数据的不平衡度,更加高效准确地筛选特征量,通过多特征融合挖掘故障信息,提高海上风电机组故障诊断的准确率和效率,使其具有较佳的抗干扰能力、自适应性和鲁棒性,优化风电机组的运维计划,提升风电机组的可靠性和利用率,对于提高风电场的智能化水平和海上风电消纳具有重要意义。
技术实现思路
1、本发明的目的在于克服现有技术的不足,提供了一种基于ceemdan-sp-cnn的海上风电机组故障诊断方法,可有效实现对不同类型故障的准确诊断。
2、为实现上述目的,本发明所提供的技术方案为:基于ceemdan-sp-cnn的海上风电机组故障诊断方法,包括以下步骤:
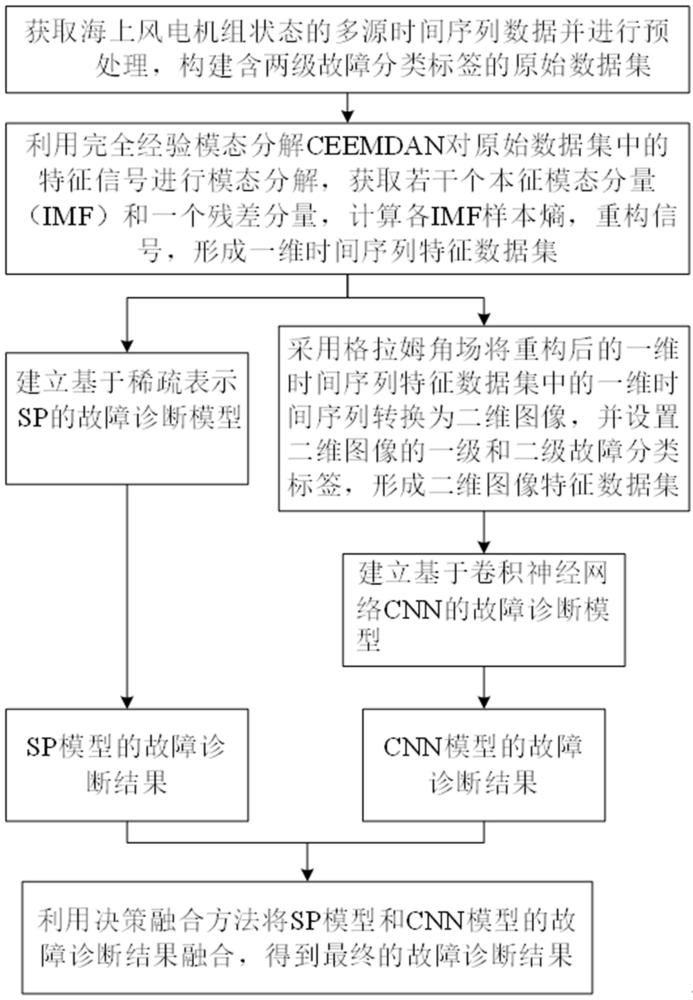
3、s1、获取海上风电机组状态监测的多源时间序列数据并进行预处理,构建含两级故障分类标签的原始数据集,其中一级故障分类标签为不同类型的部件故障,二级故障分类标签为各部件的不同类型故障;
4、s2、采用完全集合经验模态分解ceemdan算法对原始数据集中的特征信号进行模态分解,获取若干个本征模态分量imf和一个残差分量,计算每个imf的样本熵,并重构信号,形成一维时间序列特征数据集;
5、s3、采用格拉姆角场gaf将重构后的一维时间序列特征数据集中的一维时间序列转换为二维图像,并设置二维图像的一级和二级故障分类标签,形成二维图像特征数据集;
6、s4、将一维时间序列特征数据集中数据输入已训练好的sp模型中,输出一级和二级故障分类标签,即sp模型的故障诊断结果,其中sp模型为基于稀疏表示的故障诊断模型,用于挖掘多源时间序列数据与故障之间的关联关系;将二维图像特征数据集中数据输入已训练好的cnn模型中,输出一级和二级故障分类标签,即cnn模型的故障诊断结果,其中cnn模型为基于卷积神经网络的故障诊断模型,用于挖掘二维图像与故障类别之间的关联关系;最后,通过决策融合方法将sp模型和cnn模型的故障诊断结果进行融合,得到最终的故障诊断结果。
7、进一步,在步骤s1,从风电场scada监测系统和振荡监测系统获取海上风电机组状态监测的多源时间序列数据,然后执行以下操作:
8、s11、对获取的多源时间序列数据进行预处理,包括采用箱线图四分位法识别数据中的异常值及采用拉格朗日插值法进行替换和插补;
9、s12、根据海上风电机组的故障日志,预处理后的数据设置两级故障分类标签,一级故障分类标签为不同类型的部件故障,称为一级部件故障类别标签,其标签集为:, p为一级部件故障总类别数,为部件类别为 p的故障部件标签;二级故障分类标签为各部件的不同类型故障,称为二级故障类别标签,其标签集为, q为每类一级部件故障包含的总故障类别数,为当前一级部件故障类别标签下二级故障类别为 q的故障标签;
10、s13、采用多种相关系数法相结合来选取对不同一级部件故障影响大的监测量作为特征,形成特征数据集,其中,所述特征数据集中的特征包括风速、风向、转速、温度、电压、电流、输出功率和振动信号;
11、s14、利用最大值-最小值方法对特征数据集进行归一化处理,得到含两级分类标签的原始数据集。
12、进一步,在步骤s11,采用箱线图四分位法识别数据中异常值的过程如下:
13、对海上风电机组的多源时间序列数据由小到大进行排列,排列后计算四分位数,包括下四分位数、中位数和上四分位数,接着分别利用公式(1)和(2)计算上限值和下限值,高于上限值或低于下限值的数据被判定为异常值;
14、 (1);
15、 (2);
16、式中,、、分别表示多源时间序列数据根据数值由小到大进行排列后第25%、50%、75%位的数据;
17、采用的拉格朗日插值法的过程为:
18、设已知的 n+1个数据点,表示自变量与函数值之间的函数关系,在这些数据点上构建一个 n次多项式插值函数,使得第个数据点的函数值,;则的拉格朗日插值公式为:
19、 (3);
20、式中,表示第个数据点的自变量值;表示除的其它数据点的自变量值;表示第个数据点的函数值;公式中的表示对所有的自变量值进行连乘运算。
21、进一步,在步骤s13,采用的多种相关系数法为皮尔逊相关系数法、斯皮尔曼相关系数法和肯德尔相关系数法,具体公式如下:
22、 (4);
23、式中,为pearson相关系数,和分别为两个信号的数据点,、分别为两个信号的平均值,为信号的序号;
24、 (5);
25、式中,为spearman相关系数,和分别为、在序列中的位次,为信号和的维数;
26、 (6);
27、式中,为kendall相关系数, concordant和 discordant分别为具有相同顺序的观察对(,则)和具有相反顺序的观察对(,则),、、、分别表示信号、信号的第、个数据观察度,为成对观察的总数。
28、进一步,在步骤s14,所述最大值-最小值方法如下式所示;
29、 (7);
30、式中,为归一化后的数据,为原始数据,、为原始数据的最大值和最小值。
31、进一步,在步骤s2,采用完全集合经验模态分解ceemdan算法对原始数据集中的特征信号进行模态分解,获取若干个本征模态分量imf和一个残差分量,具体步骤如下:
32、a、将待分解的检测数据信号添加 k次均值为0的高斯白噪声,构造共 k次待分解序列;
33、(8);
34、式中,为高斯白噪声权值系数,为第次处理时产生的高斯白噪声, t表示时间点的总个数;
35、b、对上述序列进行emd分解,得到第1个模态分量imf,并取其均值作为ceemdan算法分解得到的第一个imf;
36、 (9);
37、 (10);
38、式中,表示第次emd分解后的第1个本征模态分量;计算 k次emd分解得到的第1个本征模态分量的平均值,得到第一个本征模态分量;表示第1次分解后的残差信号;
39、c、将分解后得到的第阶段残差信号添加特定噪声后,继续进行emd分解;
40、(11);
41、 (12);
42、式中,表示ceemdan算法分解得到的第个本征模态分量;和分别表示对序列进行emd分解后的第1和第个本征模态分量;表示ceemdan算法对第阶段残差信号加入噪声的权值系数;表示第阶段残差信号;表示第阶段残差信号;
43、d、重复步骤c直至第次分解的残差信号为0或单调信号,则迭代停止,ceemdan算法分解结束。
44、进一步,在步骤s2,对每个imf分量计算样本熵,具体如下:
45、首先,选择一个所需的模板长度 m,然后执行以下过程:对于给定的经ceemdan算法分解得到的每个本征模态分量,表示第个数据点, n表示 imf序列长度,构造所有长度为 m的连续子序列,并计算每个子序列与后续其它所有子序列的相似度,相似度能通过欧氏距离计算所得,然后设定相似度阈值 r,统计每个子序列在相似度阈值 r内相似子序列的数量,更换模板长度为 m+1,重复上述过程,最后计算两个熵值、,并利用式(13)计算样本熵;
46、(13);
47、式中,为在相似度阈值 r下匹配 m个子序列长度的相似子序列的数量,为在相似度阈值 r下匹配 m+1个子序列长度的相似子序列的数量;
48、根据样本熵的大小对经ceemdan算法分解得到的所有本征模态分量进行筛选和逆重构,得到去噪后的一维时间序列特征数据集。
49、进一步,在步骤s3,采用格拉姆角场gaf将重构后的一维时间序列特征数据集中的一维时间序列转换为二维图像,具体步骤如下:
50、a、将一维时间序列特征数据集中的特征包括风速、风向、转速、温度、电压、电流、输出功率和振动信号的时序数据规范化至区间[-1,1]后,假设某一特征的时序数据序列为,表示第个时序数据点,,规范化后的值记为;规范化后的格拉姆矩阵gram matrix就如下所示:
51、(14);
52、式中,表示向量与向量之间的夹角,;
53、b、将规范后的值转化为极坐标:
54、(15);
55、式中,表示点的时间戳,为时序数据中所包含的所有时间点的个数,每一个时间点包含两个信息:一个是该时间点的规范化值,另一个是该时间点所在的时间戳,上述极坐标转换把这两个信息都包含进来,且没有损失任何信息,极轴保留了时间上的关系,极角保留了数值上的关系;至此,将重构后的一维时间序列特征数据集中的一维时间序列转换为以、为形式的二维图像。
56、进一步,在步骤s4,所述sp模型输出的一级和二级故障分类标签的损失函数均为多元交叉熵损失函数,如下所示:
57、(16);
58、式中, n v表示多元时间样本的个数; l表示每个多元时间序列样本包含的scada样本数量,上标 c表示对应的分类标签为 c;表示一级故障分类标签内所包含的标签总数,下标表示每一多元时间序列样本中的由scada系统采集的第个时刻的样本;表示第个多元时间序列样本中第个时刻scada样本的标签是否为 c;表示模型对于第个多元时间序列样本中第个时刻scada样本的标签预测为 c的概率;为对数计算;
59、所述sp模型输出一级和二级故障分类标签过程是:①利用不同类型故障的数据训练得到分类故障字典;②基于所述分类故障字典对输入的一维时间序列进行重构,并计算重构信号与原始信号之间的残差;③找到残差最小的分类故障字典所对应的故障类型就是sp模型的故障诊断结果。
60、进一步,在步骤s4,所述决策融合方法有:d-s证据理论、贝叶斯推理、模糊推理以及专家系统。
61、本发明与现有技术相比,具有如下优点与有益效果:
62、1、本发明深入挖掘不同故障类型与多源监测量的关联关系,采用箱线图四分位法对数据中的异常值进行检测和提出,采用拉格朗日插值法对其进行修正;采用多种相关系数法相结合来对不同类型故障的监测量进行特征筛选,得到与不同类型故障强相关的特征集合;经过数据清洗、特征筛选后的时间序列数据具有更高的质量和更强的规律性,更适合准确的海上风电机组故障诊断,减小异常数据和冗余数据对预测精度和速度的影响。
63、2、本发明利用完全集合经验模态分解(ceemdan)算法在信号处理上的优势,将波动比较大的特征信号分解为若干个频率不同的本征模态分量,并利用样本熵对各模态分量进行筛选和降维,去除信号中含有的复杂噪声成分,提高了信号的适用范围;其次,利用格拉姆角场(gaf)将去噪后的一维时间序列转换为二维图像,可以更好地捕捉监测量的高维特征。
64、3、本发明采用sp模型和cnn模型对复杂工况下的海上风电机组故障进行诊断,通过将sp模型和cnn模型的故障诊断结果相互融合,使得能够同时捕获时域特征与图像特征,从而提高故障诊断的准确度,具有更强的抗噪声干扰能力、泛化性和鲁棒性。
- 还没有人留言评论。精彩留言会获得点赞!