一种基于文本分类进行地址分类的快速微调方法及系统
本发明涉及数据处理,尤其涉及一种基于文本分类进行地址分类的快速微调方法及系统。
背景技术:
1、地址标准化是一个细致的过程,它涉及将原始、格式各异的地址数据通过精确的提取、解析和验证,最终重构为统一和标准化的格式。这个过程不仅显著增强了数据的可用性和一致性,而且对于物流、城市规划、紧急响应等关键领域的高效运作起着至关重要的作用。具体来说,地址标准化的流程包括几个关键步骤。首先,它需要对输入的地址信息进行精确处理,这些原始数据可能格式各异,包含不同的地理要素。接下来,通过一系列精确的处理步骤,这些原始地址数据被转换成具有统一格式的输出,这些输出能够清晰地反映出地址中的各个地理要素,如省、市、区、街道以及乡镇/社区等。现有的针对地址分类的算法中,大部分是通过地址围栏的方式来实现,没有考虑到利用文本分类算法以及对预训练模型的微调技术来提高地址分类的准确率,因此在处理文字地址的分类任务时分类效果较差。可见,现有技术存在缺陷,亟待解决。
技术实现思路
1、本发明所要解决的技术问题在于,提供一种基于文本分类进行地址分类的快速微调方法及系统,能够有效根据待分类文本的区域特点来提高地址分类的针对性和准确度,减少分类出错。
2、为了解决上述技术问题,本发明第一方面公开了一种基于文本分类进行地址分类的快速微调方法,所述方法包括:
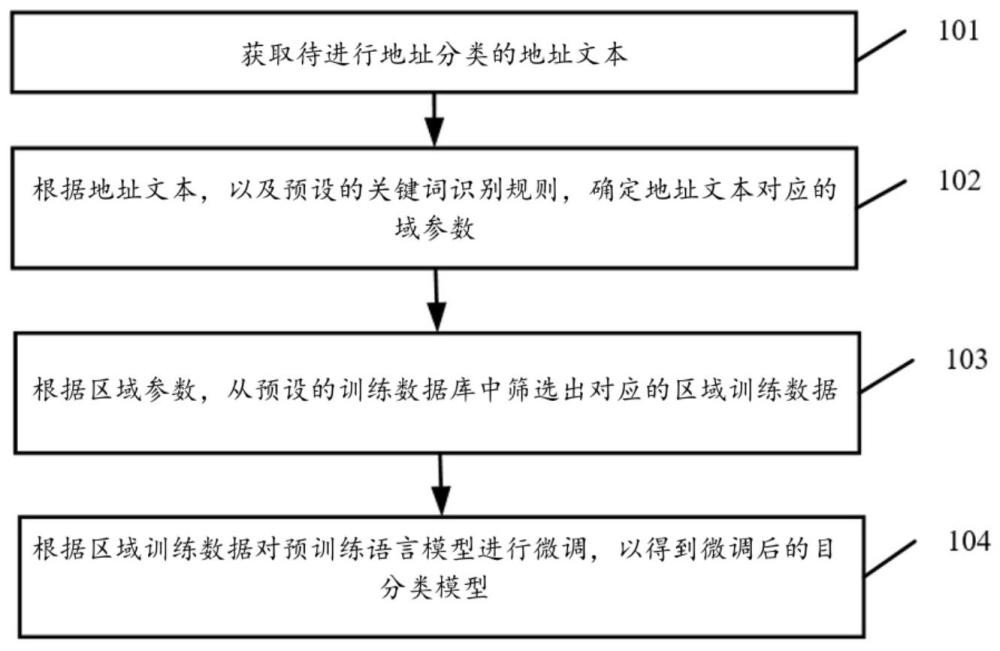
3、获取待进行地址分类的地址文本;
4、根据所述地址文本,以及预设的关键词识别规则,确定所述地址文本对应的区域参数;
5、根据所述区域参数,从预设的训练数据库中筛选出对应的区域训练数据;
6、根据所述区域训练数据对预训练语言模型进行微调,以得到微调后的目标分类模型;所述目标分类模型用于对所述地址文本进行地址分类。
7、作为一个可选的实施方式,在本发明第一方面中,所述根据所述地址文本,以及预设的关键词识别规则,确定所述地址文本对应的区域参数,包括:
8、根据标准区域规划级别对应的第一关键词规则,对所述地址文本进行识别,得到多个第一关键词;
9、根据非标准区域规划对应的第二关键词规则,对所述地址文本进行识别,得到多个第二关键词;
10、根据所述第一关键词,确定所述地址文本对应的区域级别复杂度和区域位置范围;
11、根据所述第二关键词,确定所述地址文本对应的地址详细度和地址缺失度;
12、将所述区域级别复杂度、所述区域位置范围、所述地址缺失度和所述地址详细度,确定为所述地址文本对应的区域参数。
13、作为一个可选的实施方式,在本发明第一方面中,所述根据所述第一关键词,确定所述地址文本对应的区域级别复杂度和区域位置范围,包括:
14、将每一所述第一关键词输入至训练好的区别级别分类器,得到每一所述第一关键词对应的区域级别;
15、计算所有所述第一关键词对应的区域级别之间的标准差值,得到所述地址文本对应的区域级别复杂度;
16、在预设的地图数据上标注每一所述第一关键词对应的关键词位置范围;所述关键词位置范围通过预设的关键词和位置范围的对应数学关系计算得到;
17、计算任意两个所述第一关键词对应的关键词位置范围之间的交集,得到多个交集区域;
18、根据所述多个交集区域,确定出所述地址文本对应的区域位置范围。
19、作为一个可选的实施方式,在本发明第一方面中,所述根据所述多个交集区域,确定出所述地址文本对应的区域位置范围,包括:
20、对于每一交集区域,计算该交集区域所属于的所有所述关键词位置范围的数量;
21、计算该交集区域的区域面积;
22、计算该交集区域与最近的一个其他交集区域之间的区域距离;
23、计算所述数量、所述区域面积和所述区域距离之间的乘积,得到区域优先度;
24、基于动态规划算法,计算出包括有所有所述区域优先度大于第一优先度阈值的所述交集区域的最大多边形区域,得到所述地址文本对应的区域位置范围。
25、作为一个可选的实施方式,在本发明第一方面中,所述根据所述第二关键词,确定所述地址文本对应的地址详细度和地址缺失度,包括:
26、将每一所述第二关键词输入至训练好的划分细度分类器,得到每一所述第二关键词对应的划分细度;
27、计算所有所述第二关键词对应的划分细度对应的出现次数的加权求和平均值,得到所述地址文本对应的地址详细度;其中,每一所述出现次数的加权计算时的权重与对应的所述划分细度的值成正比;所述划分细度的值与所述第二关键词能够表征的地址详细度程度成正比;
28、计算预设的多个标准划分细度中在所有所述第二关键词对应的划分细度中的出现次数低于次数阈值的标准划分细度的数量,得到所述地址文本对应的地址缺失度。
29、作为一个可选的实施方式,在本发明第一方面中,所述根据所述区域参数,从预设的训练数据库中筛选出对应的区域训练数据,包括:
30、对于预设的训练数据库中的每一候选训练数据,获取该候选训练数据对应的区域标注参数;
31、计算所述区域标注参数和所述区域参数之间的相似度,得到该候选训练数据的数据优先度;
32、根据所述数据优先度从大到小对所有所述候选训练数据进行排列得到数据序列;
33、将所述数据序列中前预设数量的且所述数据优先度大于第二优先度阈值的所有所述候选训练数据,确定为区域训练数据。
34、作为一个可选的实施方式,在本发明第一方面中,所述根据所述区域训练数据对预训练语言模型进行微调,以得到微调后的目标分类模型,包括:
35、将所述区域训练数据分为训练数据集和验证数据集;
36、将所述训练数据集输入至预训练好的bert模型中进行微调训练,并在微调训练中以交叉熵损失函数为目标更新所述bert模型的模型参数;
37、根据所述验证数据集对微调训练后的所述bert模型进行验证计算预测准确率,在所述预测准确率大于预设的准确率阈值时,将所述bert模型确定为微调后的目标分类模型。
38、作为一个可选的实施方式,在本发明第一方面中,所述bert模型为预先通过中文数据集进行训练得到的,在微调过程中使用macbert-large-chinese作为其初始权重;所述bert模型包含24层的transformer结构,拥有1024个隐藏单元,16个自注意力头;所述微调训练基于深度学习框架paddle来实现,使用adamw优化器,最大文本输入序列长度设置为64,进行3个epoch的训练,采用动态学习率,学习率初始值设为1.5e-5,并通过lambda函数lambda进行所述动态学习率的衰弱调整。
39、本发明实施例第二方面公开了一种基于文本分类进行地址分类的快速微调系统,所述系统包括:
40、获取模块,用于获取待进行地址分类的地址文本;
41、确定模块,用于根据所述地址文本,以及预设的关键词识别规则,确定所述地址文本对应的区域参数;
42、筛选模块,用于根据所述区域参数,从预设的训练数据库中筛选出对应的区域训练数据;
43、微调模块,用于根据所述区域训练数据对预训练语言模型进行微调,以得到微调后的目标分类模型;所述目标分类模型用于对所述地址文本进行地址分类。
44、作为一个可选的实施方式,在本发明第二方面中,所述确定模块根据所述地址文本,以及预设的关键词识别规则,确定所述地址文本对应的区域参数的具体方式,包括:
45、根据标准区域规划级别对应的第一关键词规则,对所述地址文本进行识别,得到多个第一关键词;
46、根据非标准区域规划对应的第二关键词规则,对所述地址文本进行识别,得到多个第二关键词;
47、根据所述第一关键词,确定所述地址文本对应的区域级别复杂度和区域位置范围;
48、根据所述第二关键词,确定所述地址文本对应的地址详细度和地址缺失度;
49、将所述区域级别复杂度、所述区域位置范围、所述地址缺失度和所述地址详细度,确定为所述地址文本对应的区域参数。
50、作为一个可选的实施方式,在本发明第二方面中,所述确定模块根据所述第一关键词,确定所述地址文本对应的区域级别复杂度和区域位置范围的具体方式,包括:
51、将每一所述第一关键词输入至训练好的区别级别分类器,得到每一所述第一关键词对应的区域级别;
52、计算所有所述第一关键词对应的区域级别之间的标准差值,得到所述地址文本对应的区域级别复杂度;
53、在预设的地图数据上标注每一所述第一关键词对应的关键词位置范围;所述关键词位置范围通过预设的关键词和位置范围的对应数学关系计算得到;
54、计算任意两个所述第一关键词对应的关键词位置范围之间的交集,得到多个交集区域;
55、根据所述多个交集区域,确定出所述地址文本对应的区域位置范围。
56、作为一个可选的实施方式,在本发明第二方面中,所述确定模块根据所述多个交集区域,确定出所述地址文本对应的区域位置范围的具体方式,包括:
57、对于每一交集区域,计算该交集区域所属于的所有所述关键词位置范围的数量;
58、计算该交集区域的区域面积;
59、计算该交集区域与最近的一个其他交集区域之间的区域距离;
60、计算所述数量、所述区域面积和所述区域距离之间的乘积,得到区域优先度;
61、基于动态规划算法,计算出包括有所有所述区域优先度大于第一优先度阈值的所述交集区域的最大多边形区域,得到所述地址文本对应的区域位置范围。
62、作为一个可选的实施方式,在本发明第二方面中,所述确定模块根据所述第二关键词,确定所述地址文本对应的地址详细度和地址缺失度的具体方式,包括:
63、将每一所述第二关键词输入至训练好的划分细度分类器,得到每一所述第二关键词对应的划分细度;
64、计算所有所述第二关键词对应的划分细度对应的出现次数的加权求和平均值,得到所述地址文本对应的地址详细度;其中,每一所述出现次数的加权计算时的权重与对应的所述划分细度的值成正比;所述划分细度的值与所述第二关键词能够表征的地址详细度程度成正比;
65、计算预设的多个标准划分细度中在所有所述第二关键词对应的划分细度中的出现次数低于次数阈值的标准划分细度的数量,得到所述地址文本对应的地址缺失度。
66、作为一个可选的实施方式,在本发明第二方面中,所述筛选模块根据所述区域参数,从预设的训练数据库中筛选出对应的区域训练数据的具体方式,包括:
67、对于预设的训练数据库中的每一候选训练数据,获取该候选训练数据对应的区域标注参数;
68、计算所述区域标注参数和所述区域参数之间的相似度,得到该候选训练数据的数据优先度;
69、根据所述数据优先度从大到小对所有所述候选训练数据进行排列得到数据序列;
70、将所述数据序列中前预设数量的且所述数据优先度大于第二优先度阈值的所有所述候选训练数据,确定为区域训练数据。
71、作为一个可选的实施方式,在本发明第二方面中,所述微调模块根据所述区域训练数据对预训练语言模型进行微调,以得到微调后的目标分类模型的具体方式,包括:
72、将所述区域训练数据分为训练数据集和验证数据集;
73、将所述训练数据集输入至预训练好的bert模型中进行微调训练,并在微调训练中以交叉熵损失函数为目标更新所述bert模型的模型参数;
74、根据所述验证数据集对微调训练后的所述bert模型进行验证计算预测准确率,在所述预测准确率大于预设的准确率阈值时,将所述bert模型确定为微调后的目标分类模型。
75、作为一个可选的实施方式,在本发明第二方面中,所述bert模型为预先通过中文数据集进行训练得到的,在微调过程中使用macbert-large-chinese作为其初始权重;所述bert模型包含24层的transformer结构,拥有1024个隐藏单元,16个自注意力头;所述微调训练基于深度学习框架paddle来实现,使用adamw优化器,最大文本输入序列长度设置为64,进行3个epoch的训练,采用动态学习率,学习率初始值设为1.5e-5,并通过lambda函数lambda进行所述动态学习率的衰弱调整。
76、本发明第三方面公开了另一种基于文本分类进行地址分类的快速微调系统,所述系统包括:
77、存储有可执行程序代码的存储器;
78、与所述存储器耦合的处理器;
79、所述处理器调用所述存储器中存储的所述可执行程序代码,执行本发明第一方面公开的基于文本分类进行地址分类的快速微调方法中的部分或全部步骤。
80、本发明第四方面公开了一种计算机存储介质,所述计算机存储介质存储有计算机指令,所述计算机指令被调用时,用于执行本发明第一方面公开的基于文本分类进行地址分类的快速微调方法中的部分或全部步骤。
81、与现有技术相比,本发明实施例具有以下有益效果:
82、本发明能够通过对地址文本的区域参数进行确定,再以此筛选出对应的区域训练数据以对预训练语言模型进行快速和实时的微调,使得目标分类模型能够更准确和有针对性地对地址文本进行地址分类,从而能够有效根据待分类文本的区域特点来提高地址分类的针对性和准确度,减少分类出错。
- 还没有人留言评论。精彩留言会获得点赞!