本发明涉及数据管理,尤其涉及一种针对水害数据中的异常数据筛选方法及系统。
背景技术:
1、目前,在煤矿行业,数据管理和分析对提高生产效率和确保生产安全至关重要,在数据处理和分析领域,数据质量和准确性对于业务至关重要。在实际生产过程中会有诸多水害数据,其具有不同的格式、内容包含一些异常数据如错误、异常值等。处理这些异常数据并将其转换成统一的格式,以便于后续的管理和分析。传统的异常数据处理方法通常是基于预先设定的规则或固定的算法,或者使用特定的数据清洗算法对异常数据进行处理,缺乏灵活性,还需要大量的人工干预和调试,降低了数据处理效率和稳定性。
技术实现思路
1、针对上述所显示出来的问题,本发明提供了一种针对水害数据中的异常数据筛选方法及系统用以解决背景技术中提到的传统的异常数据处理方法通常是基于预先设定的规则或固定的算法,或者使用特定的数据清洗算法对异常数据进行处理,缺乏灵活性,还需要大量的人工干预和调试,降低了数据处理效率和稳定性的问题。
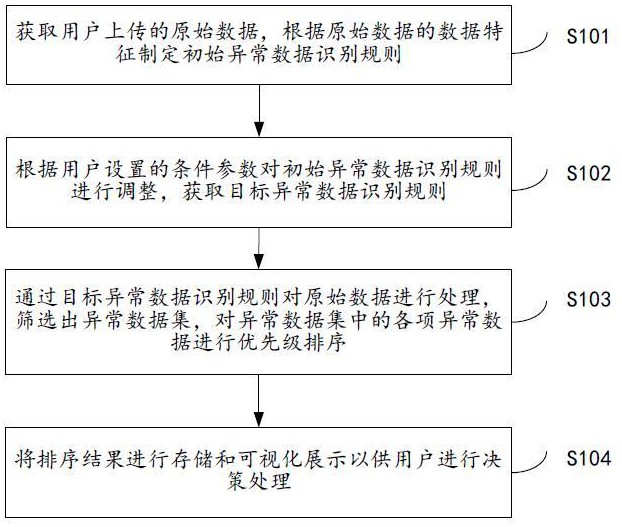
2、一种针对水害数据中的异常数据筛选方法,包括以下步骤:
3、获取用户上传的原始水害数据,根据原始水害数据的数据特征制定初始异常数据识别规则;
4、根据用户设置的条件参数对初始异常数据识别规则进行调整,获取目标异常数据识别规则;
5、通过目标异常数据识别规则对原始水害数据进行处理,筛选出异常数据集,对异常数据集中的各项异常数据进行优先级排序;
6、将排序结果进行存储和可视化展示以供用户进行决策处理。
7、优选的,所述获取用户上传的原始水害数据,根据原始水害数据的数据特征制定初始异常数据识别规则,包括:
8、通过用户自定义配置或数据系统内置规则获取用户上传的原始水害数据并对其进行预处理;
9、确定预处理后的原始水害数据的数据单位和周期性变化特性,根据数据单位和周期性变化特性确定数据特征;
10、根据数据特征定义异常数据的初始判定阈值和第一数据异常上限阈值以及第一数据异常下限阈值,根据第一数据异常上限阈值和第一数据异常下限阈值以及预设阈值区间设置预警级别;
11、根据预警级别、异常数据的判定阈值和第一数据异常上限阈值以及第一数据异常下限阈值结合预设异常检测算法定制初始异常数据识别规则;
12、其中,预设异常检测算法包括:线性回归算法、自回归积分滑动平均值算法、随机森林算法和深度神经网络算法。
13、优选的,根据用户设置的条件参数对初始异常数据识别规则进行调整,获取目标异常数据识别规则,包括:
14、根据用户设置的条件参数确定数据指标应用场景参数,根据数据指标应用场景参数确定常态数据区间和异态数据区间;
15、根据常态数据区间对异常数据的初始判定阈值进行调整,获取目标判定阈值;
16、根据异态数据区间对第一数据异常上限阈值和第一数据异常下限阈值进行调整,获取第二数据异常上限阈值和第二数据异常下限阈值;
17、根据第二数据异常上限阈值和第二数据异常下限阈值对每个预警级别的预警阈值区间进行调整,根据调整结果获取目标数据识别规则。
18、优选的,所述通过目标异常数据识别规则对原始水害数据进行处理,筛选出异常数据集,对异常数据集中的各项异常数据进行优先级排序,包括:
19、通过异常数据识别规则基于统计分析方法对原始水害数据进行处理,筛选出异常数据;
20、确定每个异常数据的当前预警级别,将同一预警级别的异常数据进行整合和排列以构建异常数据集;
21、根据异常数据集中各项异常数据的预警级别对各项数据进行优先级排序,获取排序结果。
22、优选的,所述将排序结果进行存储和可视化展示以供用户进行决策处理,包括:
23、通过特定存储方式将排序结果进行存储,通过人工智能模型对排序结果中的异常数据进行原因分析,获取数据异常原因;
24、将排序结果和数据异常原因相关联进行可视化展示并配置功能选项;
25、获取用户的数据操作需求,根据数据操作需求基于功能选项对排序结果中的异常数据进行操作;
26、根据操作结果生成数据操作日志并进行存储和数据同步。
27、优选的,在根据用户设置的条件参数对初始异常数据识别规则进行调整,获取目标异常数据识别规则之前,还包括:对初始异常数据识别规则进行测试,具体为:
28、根据初始异常数据识别规则确定异常数据的数据识别特征,根据数据识别特征确定用于识别异常数据的定点代码;
29、将定点代码输出到文件中并进行编译生成测试脚本;
30、将测试脚本写入到测试引擎中,获取包含异常数据的水害数据样本;
31、通过测试引擎对水害数据样本进行异常数据识别和筛选测试,获取第一异常数据样本集;
32、确定第一异常数据样本集中异常数据的共同数据特征确定异常数据的第一数据状态变量;
33、获取人工对于水害数据样本的第二异常数据样本集,对比第一异常数据样本集和第二异常数据样本集确定是否存在遗漏异常数据;
34、若是,判断初始异常数据识别规则测试不合格,若否,判断初始异常数据识别规则测试合格;
35、确定遗漏异常数据的第二数据状态变量,根据第二数据状态变量对测试引擎的当前状态函数进行修正,获取目标状态函数;
36、根据目标状态函数对初始异常数据识别规则进行修正,获取目标异常数据识别规则,将目标异常数据识别规则作为对水害数据的异常数据识别规则。
37、一种针对水害数据中的所述针对水害数据中的异常数据筛选系统,该系统包括:
38、制定模块,用于获取用户上传的原始水害数据,根据原始水害数据的数据特征制定初始异常数据识别规则;
39、调整模块,用于根据用户设置的条件参数对初始异常数据识别规则进行调整,获取目标异常数据识别规则;
40、筛选模块,用于通过目标异常数据识别规则对原始水害数据进行处理,筛选出异常数据集,对异常数据集中的各项异常数据进行优先级排序;
41、存储展示模块,用于将排序结果进行存储和可视化展示以供用户进行决策处理。
42、优选的,所述制定模块,包括:
43、获取子模块,用于通过用户自定义配置或数据系统内置规则获取用户上传的原始水害数据并对其进行预处理;
44、第一确定子模块,用于确定预处理后的原始水害数据的数据单位和周期性变化特性,根据数据单位和周期性变化特性确定数据特征;
45、设置子模块,用于根据数据特征定义异常数据的初始判定阈值和第一数据异常上限阈值以及第一数据异常下限阈值,根据第一数据异常上限阈值和第一数据异常下限阈值以及预设阈值区间设置预警级别;
46、制定子模块,用于根据预警级别、异常数据的判定阈值和第一数据异常上限阈值以及第一数据异常下限阈值结合预设异常检测算法定制初始异常数据识别规则;
47、其中,预设异常检测算法包括:线性回归算法、自回归积分滑动平均值算法、随机森林算法和深度神经网络算法。
48、优选的,调整模块,包括:
49、第二确定子模块,用于根据用户设置的条件参数确定数据指标应用场景参数,根据数据指标应用场景参数确定常态数据区间和异态数据区间;
50、第一调整子模块,用于根据常态数据区间对异常数据的初始判定阈值进行调整,获取目标判定阈值;
51、第二调整子模块,用于根据异态数据区间对第一数据异常上限阈值和第一数据异常下限阈值进行调整,获取第二数据异常上限阈值和第二数据异常下限阈值;
52、第三调整子模块,用于根据第二数据异常上限阈值和第二数据异常下限阈值对每个预警级别的预警阈值区间进行调整,根据调整结果获取目标数据识别规则。
53、优选的,所述筛选模块,包括:
54、筛选子模块,用于通过异常数据识别规则基于统计分析方法对原始水害数据进行处理,筛选出异常数据;
55、整合子模块,用于确定每个异常数据的当前预警级别,将同一预警级别的异常数据进行整合和排列以构建异常数据集;
56、排序子模块,用于根据异常数据集中各项异常数据的预警级别对各项数据进行优先级排序,获取排序结果。
57、优选的,所述存储和展示模块,包括:
58、存储子模块,用于通过特定存储方式将排序结果进行存储,通过人工智能模型对排序结果中的异常数据进行原因分析,获取数据异常原因;
59、关联子模块,用于将排序结果和数据异常原因相关联进行可视化展示并配置功能选项;
60、操作子模块,用于获取用户的数据操作需求,根据数据操作需求基于功能选项对排序结果中的异常数据进行操作;
61、同步子模块,用于根据操作结果生成数据操作日志并进行存储和数据同步。
62、优选的,在根据用户设置的条件参数对初始异常数据识别规则进行调整,获取目标异常数据识别规则之前,所述系统还用于对初始异常数据识别规则进行测试,具体为:
63、根据初始异常数据识别规则确定异常数据的数据识别特征,根据数据识别特征确定用于识别异常数据的定点代码;
64、将定点代码输出到文件中并进行编译生成测试脚本;
65、将测试脚本写入到测试引擎中,获取包含异常数据的水害数据样本;
66、通过测试引擎对水害数据样本进行异常数据识别和筛选测试,获取第一异常数据样本集;
67、确定第一异常数据样本集中异常数据的共同数据特征确定异常数据的第一数据状态变量;
68、获取人工对于水害数据样本的第二异常数据样本集,对比第一异常数据样本集和第二异常数据样本集确定是否存在遗漏异常数据;
69、若是,判断初始异常数据识别规则测试不合格,若否,判断初始异常数据识别规则测试合格;
70、确定遗漏异常数据的第二数据状态变量,根据第二数据状态变量对测试引擎的当前状态函数进行修正,获取目标状态函数;
71、根据目标状态函数对初始异常数据识别规则进行修正,获取目标异常数据识别规则,将目标异常数据识别规则作为对水害数据的异常数据识别规则。
72、本发明的其它特征和优点将在随后的说明书中阐述,并且,部分地从说明书中变得显而易见,或者通过实施本发明而了解。本发明的目的和其他优点可通过在所写的说明书以及附图中所特别指出的结构来实现和获得。
73、下面通过附图和实施例,对本发明的技术方案做进一步的详细描述。