文档级中文事件关系检测方法及系统
本发明属于数据挖掘领域,具体涉及一种文档级中文事件关系检测方法及系统。
背景技术:
1、事件是由特定人、物、事在特定时间和特定地点相互作用的客观事实。事件触发词是指表达事件发生或变化的动词或动词短语,如“结婚”、“死亡”等。事件的发生往往不是孤立现象,必然存在与之相关的其它事件,例如原因事件、结果事件和并发事件等。这种事件之间相互依存和关联的逻辑形式,称为事件关系。事件关系客观存在于事件之间,并且作用于原本孤立的事件集合中。事件关系能将离散于文本中的事件相连接,形成事件关系网络和事件发展的拓扑脉络。因此,分析事件关系对于目前大规模的信息分析与处理具有重要的应用价值,例如,关联事件聚类、新闻事件的关系网络构建,以及突发事件推理与预测等。
2、事件关系检测是一种深入判定两两事件之间具有何种逻辑关系的任务。目前,事件关系检测的方法可以分为基于规则的方法和基于机器学习的方法。基于规则的方法主要依靠人工定义规则或模板来抽取事件关系,而基于机器学习的方法则通过训练大规模的语料库来学习事件关系的模式。在基于机器学习的方法中,深度学习技术如cnn、lstm和transformer等,被广泛应用于事件关系检测任务。这些方法通常将文本输入转换为向量表示,并使用向量运算来模拟人类对文本的理解和推理过程。但是,现有的事件关系检测模型大多仅仅着眼于某一特定的事件关系类型(如“因果”关系)的判定,并不具有全面性和普适性;其次,以往的工作主要针对单一关系类型的细粒度问题,如隐式因果关系、文档级因果关系和域因果关系,这些都是为具体问题量身定制的,不适合检测多种类型的事件关系。
技术实现思路
1、本发明的目的之一在于提供一种可靠性高且精确度高的文档级中文事件关系检测方法。
2、本发明的目的之二在于提供一种实现所述文档级中文事件关系检测方法的系统。
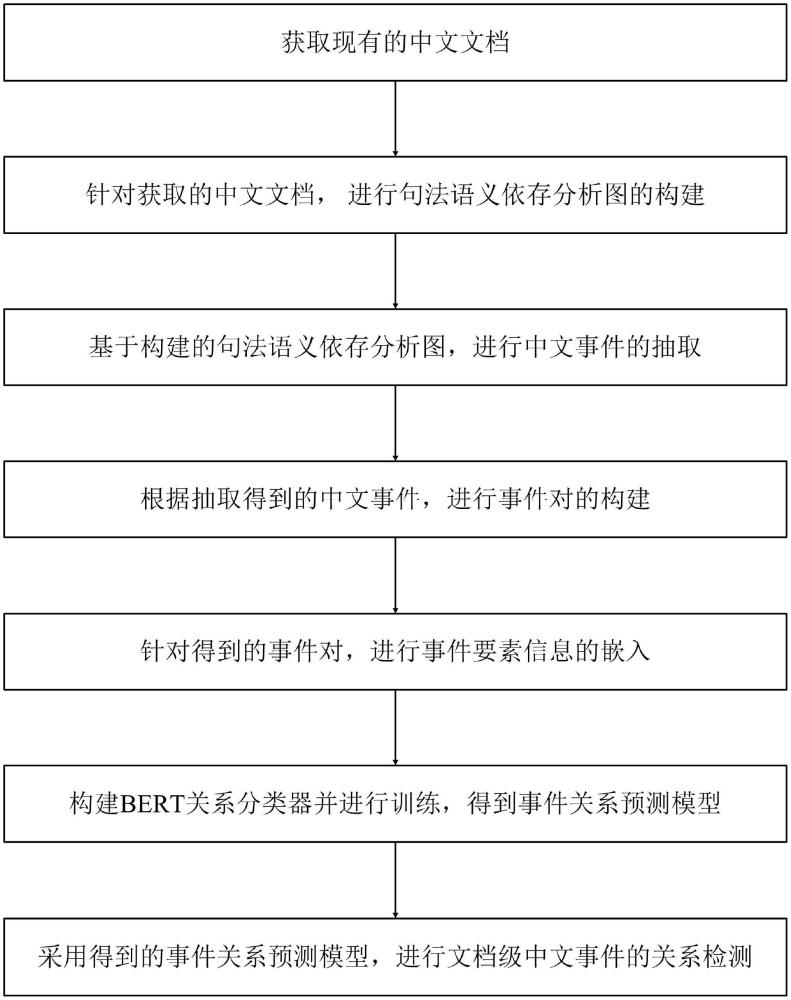
3、本发明提供的这种文档级中文事件关系检测方法,包括如下步骤:
4、s1.获取现有的中文文档;
5、s2.针对步骤s1获取的中文文档,进行句法语义依存分析图的构建;
6、s3.基于步骤s2构建的句法语义依存分析图,进行中文事件的抽取;
7、s4.根据步骤s3抽取得到的中文事件,进行事件对的构建;
8、s5.针对步骤s4得到的事件对,进行事件要素信息的嵌入;
9、s6.构建bert关系分类器并进行训练,得到事件关系预测模型;
10、s7.采用步骤s6得到的事件关系预测模型,进行文档级中文事件的关系检测。
11、步骤s2所述的针对步骤s1获取的中文文档,进行句法语义依存分析图的构建,具体包括如下步骤:
12、基于句法语义依存分析的句法语义依存分析树的构建:
13、采用语法解析工具,对文档进行分词、词性标注和语法语义分析;
14、根据语法语义分析结果,将文档转换为依存句法分析树;依存句法分析树中的节点表示单词,边表示语法语义依赖关系,父母节点前后的单次为左右两边的子代节点;
15、将所有单词节点按照在文档出现的顺序进行升序编号,根节点的编号为0;
16、对依存句法分析树进行剪枝:只保主干成分,以减少依存句法分析树的节点数量;所述的主干成分包括主语、触发词和宾语;对剪枝后的依存句法分析树进行语义依存分析,获取触发词之间的语义关联;将得到的语义关联增加到原始的依存句法分析树中;
17、事件之间的语义依存关系采用exx表示;对于触发词间的非exx关系,在依赖的子节点中查询并获取,并作为触发词之间的语义关联;所述的exx包括ecoo、epurp和esucc:ecoo表示并列关系,指若干个平行的语义事件;epurp表示先行关系,指在时间、空间上发生有序的事件或在逻辑、语义上关联性大于设定强度的先行发生的事件;esucc表示后继关系,指语义上更进一步的结果类事件,包括时间、空间、逻辑或语义上后续发生的事件;
18、基于触发词和语义结构的句法语义依存分析树的调整:
19、触发词调整:提升处于触发词链中每个触发词节点的层级,使得调整后的句法语义依存分析树中的所有触发词节点和核心根节点具有相同的层级;所述的核心根节点,在调整前只包括语句核心词,在调整后包括根节点的直接孩子节点;
20、介词结构调整:提升介词引导的充当主语或宾语的节点层级,使得调整后的节点作为对应核心根节点的直接孩子节点;
21、被动语态调整:提升被动语句对应节点的层级,修改句法依存关系;
22、最终,完成句法语义依存分析图的构建。
23、步骤s3所述的基于步骤s2构建的句法语义依存分析图,进行中文事件的抽取,具体包括如下步骤:
24、依次扫描句法语义依存分析图中核心根节点及对应的孩子节点;
25、抽取事件主语、谓语和宾语,并采用以下规则进行补全:
26、规则1:由核心根节点触发的事件不存在具有语义依存关系的较早事件,则不进行补全;
27、规则2:若存在直接成分缺失,且ert中sdp为非引发关系,若最近关联事件只存在一个主语,则在最近的关联事件中查询获取关联事件的主语,并用于补全缺省主语;
28、规则3:若存在直接成分缺失,且ert中sdp为引发关系,若最近关联事件存在若干个主语,则取最近关联事件中距离当前事件最远的主语,用于补全缺省主语;
29、规则4:若最近关联事件的主语词性不属于pol,且主语存在定语时,则取主语第一个定语用于补全缺省主语;
30、规则5:若最近关联事件的主语词性不属于pol,且主语不存在定语,则取关联事件整体用于补全缺省主语;
31、规则6:若最近关联事件的主语词性为名词或属于pol,则直接取关联事件主语用于补全缺省主语;
32、规则7:若为介词引发的成分缺省,且sdp为引发关系,则在最近关联事件中查找主语,用于补全缺省的主语或宾语;
33、规则8:若由被动语态引起的成分缺省,且sdp为引发关系,则取最近关联事件的主语,用于补全缺省事件的宾语成分;
34、规则9:若关联事件主语的词性属于pol,且主语存在定语,同时定语的词性也属于pol,则在最近关联事件中取距离本事件最远的定语,用于补全主语的缺省修饰部分;
35、规则10:若关联事件主语的词性属于pol,且主语不存在定语,则取最近关联事件中距离本事件最远的主语,用于补全主语的缺省修饰部分;
36、所述的ert为时间关系二元组(dp,sdp),其中dp为句法依存关系,sdp为语义依存关系;所述的pol为词性集{ni,nz,nh,j},其中ni为机构团体,nz为专有名词,nh为人名,j为简称。
37、步骤s4所述的根据步骤s3抽取得到的中文事件,进行事件对的构建,包括如下步骤:
38、对于跨文档数据,进行文档聚类,以减少匹配的复杂度:采用word2vec算法将文档表示为高维向量,然后基于卷积神经网络和自编码器,将文档向量嵌入到低维潜在空间,最后采用谱聚类算法将得到的文档低维表示进行聚类;
39、对聚类的数据,进行数据增强,完成事件对的构建。
40、所述的步骤s4,具体包括如下步骤:
41、采用word2vec算法将文档表示为高维向量;
42、基于卷积神经网络和自编码器,将文档向量嵌入到低维潜在空间:
43、构建的自编码器包括编码器和解码器;采用卷积神经网络构建编码器,采用反卷积网络构建解码器;
44、编码器有n个卷积核,第k个卷积核为nk,偏置为bk和ck;对于输入数据x,第k个卷积核的输入hk和解码器的重构数据表示为:
45、hk=σ(x*wk+bk)
46、
47、式中wk为第k个特征图的权重矩阵;*为二维卷积运算;σ()为映射函数;hk为第k个卷积核的输入;为wk的转置;
48、训练时,采用如下误差函数l进行训练:
49、
50、式中为解码器输出;η为正则系数;w为模型权重向量;|| ||为正则化,右上角的2表示l2正则化;
51、采用谱聚类算法将得到的文档低维表示进行聚类:
52、文档预处理:进行中文分词、去除停用词并将文档用向量进行表示;中文分词采用分词库jieba完成;基于word2vec方法,采用skip-gram方法得到词向量,将每篇文档看成为所包含词的组合,由此文档所含词的词向量堆叠构成文档词矩阵,并用于表示对应的文档;设定dj为第j篇文档的向量表示,nj为第j篇文档所含单词的数量,wi为通过skip-gram得到的词向量,则最终构成的文档矩阵表示为
53、采用自编码器将高维文档矩阵嵌入到低维潜在向量空间中;
54、采用得到的低维向量表示进行谱聚类,得到最终的聚类结果;
55、对聚类的数据,进行数据增强,完成事件对的构建:
56、采用如下规则进行数据增强:
57、规则1:相互性,若a和b有关系,则b和a也有关系;
58、规则2:传递性,若a与b为时序关系,b与c为时间等同关系,则a与c也为时序关系;
59、规则3:传递性,若a与b为时序关系,b与c为共指关系,则a与c也为时序关系;
60、规则4:传递性,若a与b为因果关系,b与c为共指关系,则a与c也为因果关系;
61、规则5:传递性,若a与b为包含关系且a包含b,b与c为共指关系,则a与c也为包含关系且a包含c;
62、规则6:传递性,若a与b为包含关系且a包含b,a与c为共指关系,则c与b也为包含关系且c包含b;
63、规则7:传递性,若a与b为内容信息提及关系且a提及b,b与c为共指关系,则a与c也为内容信息提及关系且a提及c;
64、规则8:传递性,若a与b为内容信息提及关系且a提及b,a与c为共指关系,则c与b也为内容信息提及关系且c提及b;
65、规则9:传递性,若a与b为共指关系,a与c为共指关系,则b与c也为共指关系;
66、规则10:传递性,若a与b为时间等同关系,a与c为时间等同关系,则b与c也为时间等同关系;
67、事件类型嵌入:将信息统一放入到恢复出的事件句子的句首,并在该信息两边添加设定标记,以区分原始信息。
68、步骤s5所述的针对步骤s4得到的事件对,进行事件要素信息的嵌入,具体包括如下步骤:
69、基于bert模型构建嵌入模型,采用嵌入模型对步骤s4得到的事件对,进行事件要素信息的嵌入;
70、构建的嵌入模型包括event core embedding层、token embeddings层、segmentembeddings层和position embeddings层;
71、event core embedding层:首先获取事件的若干核心元素;然后对于每个核心元素,记录核心元素在事件恢复句子中的开始和结束位置;最后,将起始范围和结束范围内的tokens标记emc,其他内容标记为em-c,
72、token embeddings层:将各个词转换成固定维度的向量;同时,在tokenization的结果和开头,插入设定的token信息;
73、segment embeddings层:句子对中的两个句子拼接后输入到segment embeddings层;segment embeddings层包括两种向量表示,前一个向量将0赋给第一个句子中的各个token后一个向量是把1赋给第二个句子中的各个token,从而区分句子对中的不同句子;
74、position embeddings层:用于得到序列的位置信息;
75、最终,将event core embedding层、token embeddings层、segment embeddings层和position embeddings层的输出进行直接相加,并通过一层layernorm+dropout后输出,完成事件要素信息的嵌入。
76、步骤s6所述的构建bert关系分类器并进行训练,得到事件关系预测模型,具体包括如下步骤:
77、对输入的序列,添加设定的token信息,使得bert模型能够接受语句级别的输入;
78、在bert模型的输出端,增加全连接层和softmax层,用于输出最后的分类概率;
79、训练过程中,采用如下函数作为损失函数ll:
80、
81、式中n为训练时同一批次的数据数量;wi为第i个数据的bert模型权重;ti为第i个数据的预测目标类别向量;outputi为第i个数据的原bert模型的输出;sigmoid()为激活函数,且
82、基于adam算法实现对模型的训练。
83、所述的基于adam算法实现对模型的训练,具体包括如下步骤:
84、采用如下算式作为权重值的迭代更新算式:
85、v'=b1v+(1-b1)dw
86、s'=b2s+(1-b2)dw2
87、
88、式中v'为更新后的一阶动量;b1为adam算法进行矩估计的第一指数衰减速率;v为更新前的一阶动量;dw为参数w的一阶梯度;s'为更新后的二阶动量;b2为adam算法进行矩估计的第二指数衰减速率;dw2为参数w的二阶梯度;w'为更新后的优化参数;w为更新前的优化参数;α为学习速率;ε为学习步长;s为更新前的二阶动量。
89、本发明还提供了一种实现所述文档级中文事件关系检测方法的系统,包括数据获取模块、图构建模块、事件抽取模块、事件对构建模块、信息嵌入模块、关系预测模块和关系检测模块;数据获取模块、图构建模块、事件抽取模块、事件对构建模块、信息嵌入模块、关系预测模块和关系检测模块依次串接;数据获取模块用于获取现有的中文文档,并将数据信息上传图构建模块;图构建模块用于根据接收到的数据信息,针对获取的中文文档,进行句法语义依存分析图的构建,并将数据信息上传事件抽取模块;事件抽取模块用于根据接收到的数据信息,基于构建的句法语义依存分析图,进行中文事件的抽取,并将数据信息上传事件对构建模块;事件对构建模块用于根据接收到的数据信息,根据抽取得到的中文事件,进行事件对的构建,并将数据信息上传信息嵌入模块;信息嵌入模块用于根据接收到的数据信息,针对得到的事件对,进行事件要素信息的嵌入,并将数据信息上传关系预测模块;关系预测模块用于根据接收到的数据信息,构建bert关系分类器并进行训练,得到事件关系预测模型,并将数据信息上传关系检测模块;关系检测模块用于根据接收到的数据信息,采用得到的事件关系预测模型,进行文档级中文事件的关系检测。
90、本发明提供的这种文档级中文事件关系检测方法及系统,根据句法语义依存分析图的构建、中文事件的抽取和事件对的构建,保证了事件关系判断的基础,并同时根据bert关系分类器实现文档级中文事件的关系检测;而且本发明的可靠性更高,而且(精确度更高。
- 还没有人留言评论。精彩留言会获得点赞!