本发明涉及负载预测,特别是涉及一种基于复杂周期的边缘云长序列负载预测方法。
背景技术:
1、边缘缓存技术通过将热门或常用内容存储在边缘节点,使用户请求可以直接从缓存中获取,从而减轻源服务器的负担并提高缓存命中率。然而,由于边缘节点的存储空间有限,将所有热门内容都缓存到这些有限的空间中并不现实。
2、目前,基于机器学习的主动边缘缓存工作已经取得了一定进展。然而,现有研究大多从用户行为出发,寻找内容之间的相关性。这种方法可能会受到单一事件或特定群体的影响,导致负载预测结果不准确,从而影响缓存策略的准确性,加大了边缘云平台负载压力。
技术实现思路
1、本发明旨在至少解决现有技术中存在的边缘节点负载预测结果不准确,从而影响缓存策略的准确性技术问题,特别创新地提出了一种基于复杂周期的边缘云长序列负载预测方法。
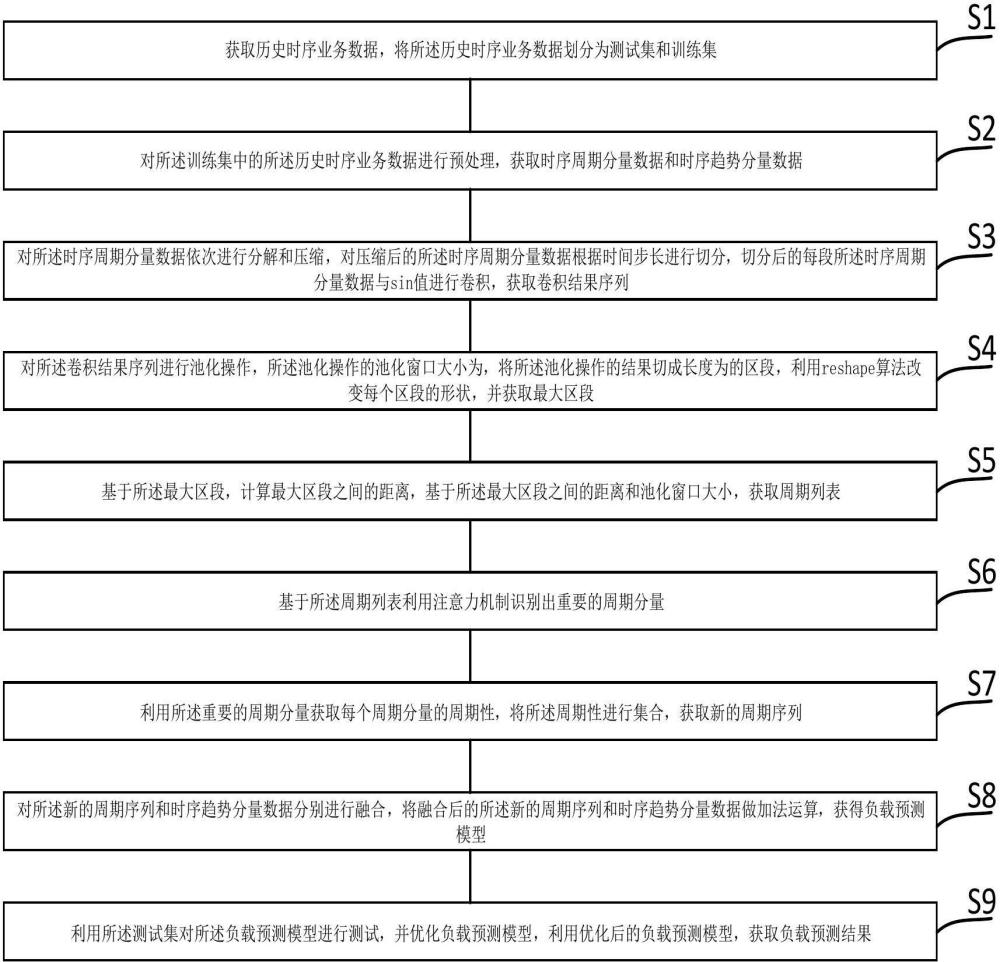
2、为了实现本发明的上述目的,本发明提供了一种基于复杂周期的边缘云长序列负载预测方法,包括:
3、s1、获取边缘云平台的历史时序业务数据,将所述历史时序业务数据划分为测试集和训练集;
4、s2、对所述训练集中的所述历史时序业务数据进行预处理,获取时序周期分量数据和时序趋势分量数据;
5、s3、对所述时序周期分量数据依次进行分解和压缩,对压缩后的所述时序周期分量数据根据时间步长进行切分,切分后的每段所述时序周期分量数据与sin值进行卷积,获取卷积结果序列;
6、s4、对所述卷积结果序列进行池化操作,所述池化操作的池化窗口大小为,将所述池化操作的结果切成长度为的区段,利用reshape算法改变每个区段的形状,并获取每个所述区段中的最大值;
7、s5、基于每个所述区段的最大值,计算相邻最大值之间的距离,基于所述最大值之间的距离和池化窗口大小,获取周期列表;
8、s6、基于所述周期列表利用注意力机制识别出重要的周期分量;
9、s7、利用所述重要的周期分量获取每个周期分量的周期性,将所述周期性进行组合,获取结合周期重构的序列;
10、s8、对所述结合周期重构的序列和时序趋势分量数据分别进行融合,将融合后的所述结合周期重构的序列和时序趋势分量数据做加法运算,获得负载预测模型;
11、s9、利用所述测试集对所述负载预测模型进行测试,并优化负载预测模型,利用优化后的负载预测模型,获取负载预测结果。
12、作为本发明的一种可选实施例,可选地,所述对所述历史时序业务数据进行预处理,获取时序周期分量数据和时序趋势分量数据包括:
13、s21、对所述历史时序业务数据进行归一化操作,将所述历史时序业务数据进行压缩;
14、s22、将归一化后的所述历史时序业务数据划分为相同时间步长的历史时序业务数据,并从划分后的历史时序业务数据中提取特征,获取训练特征序列数据;
15、s23、对所述训练特征序列数据进行平均池化,获取时序周期分量数据和时序趋势分量数据。
16、作为本发明的一种可选实施例,可选地,对所述训练特征序列数据进行平均池化,获取时序周期分量数据和时序趋势分量数据的表达式为:
17、
18、
19、其中,表示时序趋势分量数据,表示移动平均操作,表示收尾填充操作,表示训练特征序列数据,表示时序周期分量数据。
20、作为本发明的一种可选实施例,可选地,所述对所述时序周期分量数据依次进行分解和压缩的表达式为:
21、
22、
23、其中,表示时序周期分量数据,表示分解操作,表示训练特征序列数据,表示压缩后的时序周期分量数据,表示矩阵压缩操作。
24、作为本发明的一种可选实施例,可选地,所述对压缩后的所述时序周期分量数据根据时间步长进行切分,切分后的每段所述时序周期分量数据与sin值进行卷积,获取卷积结果序列的表达式为:
25、
26、
27、
28、
29、...
30、
31、...
32、
33、
34、其中,表示第个压缩后的时序周期分量数据,表示对压缩后的时序周期分量数据根据时间步长进行切分的总段数,表示对第个压缩后的时序周期分量数据的第一次迭代,表示划分压缩后的时序周期分量数据,表示卷积操作的迭代总数,表示时序周期分量数据的序列长度,表示将0-2π均匀取值的取值长度,表示向上取整,表示卷积操作的迭代数,表示卷积结果序列,卷积操作,表示sin值;表示处于第几部分,表示处于第部分,表示处于第部分。。
35、作为本发明的一种可选实施例,可选地,所述对所述卷积结果序列进行池化操作,所述池化操作的池化窗口大小为,将所述池化操作的结果切成长度为的区段,利用reshape算法改变每个区段的形状,并获取每个所述区段中的最大值的表达式为:
36、
37、
38、
39、
40、...
41、
42、...
43、
44、
45、
46、其中,表示第个卷积结果序列,表示区段总段数,表示划分卷积结果序列,表示池化操作的总迭代数,表示卷积结果序列的长度,表示池化窗口大小,表示向上取整,表示池化操作的迭代数,表示第次迭代的最大值,表示最后一次迭代的最大值,表示池化操作的总迭代数,表示最大值,取最大值函数;表示处于第几部分,表示处于第部分,表示处于第部分。
47、作为本发明的一种可选实施例,可选地,所述获取周期列表的表达式为:
48、
49、其中,表示周期列表,表示计算相邻最大值之间的距离,表示最大值,表示池化窗口大小。
50、作为本发明的一种可选实施例,可选地,所述基于所述周期列表利用注意力机制识别出重要的周期分量的表达式为:
51、
52、<mstyle displaystyle="true" mathcolor="#000000"><msub><mi>x</mi><mi>set</mi></msub><mi>=</mi><mi>{</mi><msubsup><mi>x</mi><mi>t</mi><mi>set</mi></msubsup><mi>=</mi><mi>set</mi><mi>(</mi><msubsup><mi>x</mi><mrow><mi>t</mi><mi>±</mi><mi>τ</mi></mrow><mi>i</mi></msubsup><mi>),</mi><mi>i</mi><mi>∈</mi><mi>[</mi><mn>0</mn><mi>,</mi><mi>num</mi><mi>(</mi><mi>period</mi><mi>)</mi><mi>−</mi><mn>1</mn><msubsup><mi>]}</mi><mrow><mi>t</mi><mi>=</mi><mi>s</mi><mi>_</mi><mi>begin</mi></mrow><mrow><mi>s</mi><mi>_</mi><mi>end</mi></mrow></msubsup></mstyle>
53、其中,表示在单个周期内,表示时间点对应的单个周期偏移节点,表示周期列表,表示周期列表,表示时序周期分量数据,表示训练集,表示结尾,表示开头,表示的集合,表示对过滤重复节点后的结果,表示去重操作,表示第个周期内,时刻对应的多个周期偏移节点,表示计数操作,表示周期列表。
54、作为本发明的一种可选实施例,可选地,所述利用所述重要的周期分量获取每个周期分量的周期性,将所述周期性进行组合,获取结合周期重构的序列表达式:
55、
56、其中,表示结合周期重构的序列,表示对进行线性映射后的结果,表示深度学习线性层,表示对时刻的所有的周期对应的偏置节点集合,表示结尾,表示开头。
57、作为本发明的一种可选实施例,可选地,所述利用优化后的负载预测模型,获取负载预测结果的表达式为:
58、
59、其中,表示负载预测结果,表示融合的线性层,表示结合周期重构的序列,表示融合时序趋势分量数据的线性层,表示时序趋势分量数据。
60、本发明的有益效果在于,通过综合考虑历史时序业务数据的时序周期分量和时序趋势分量,结合注意力机制识别重要周期分量,进而构建出的长序列负载预测模型,利用负载预测模型对边缘节点未来负载进行预测,这种预测方法不仅提高了预测精度,而且更加适应复杂周期的动态变化,有助于优化边缘云平台的缓存策略,提升缓存效率,降低源服务器的负载压力。同时,本发明的方法具有较强的可扩展性和灵活性,可以根据不同的业务需求和数据特点进行定制化调整,满足不同场景下的负载预测需求。本发明首先对历史时序业务数据进行预处理,提取出时序周期分量数据和时序趋势分量数据。然后,通过对时序周期分量数据进行分解、压缩、卷积和池化等操作,结合注意力机制识别出重要的周期分量,从而获取每个周期分量的周期性,并构建出结合周期重构的序列。接着,将结合周期重构的序列和时序趋势分量数据进行融合,生成负载预测模型。最后,利用测试集对负载预测模型进行测试和优化,获取准确的负载预测结果。相比传统的基于用户行为的内容相关性预测方法,本发明的方法不仅考虑了用户行为的影响,还综合考虑了时序周期分量和时序趋势分量的影响,从而提高了预测精度和稳定性。此外,本发明的方法还采用了注意力机制,降低了计算复杂度和资源消耗,使得预测过程更加高效和可靠。
61、本发明的附加方面和优点将在下面的描述中部分给出,部分将从下面的描述中变得明显,或通过本发明的实践了解到。