一种基于主成分分析的短期风电功率预测误差成因评估方法与流程
本发明涉及互联网,更具体地说,本发明涉及一种基于主成分分析的短期风电功率预测误差成因评估方法。
背景技术:
1、目前风力发电技术正处于快速发展的阶段,取得了显著的进展。风力发电领域正在积极应用智能化和数字化技术,广泛推进远程监测、大集控和大数据分析以及功率预测系统等相关领域的布局。
2、风电场及相关产业模型预测正朝着更精确、多维度、数据驱动和ai化的方向发展。然而,预测仍存在一些不足之处。首先,预测模型受到多种因素的影响,如气象条件的变化和设备状况的不确定性,导致预测结果与实际情况存在误差。其次,由于风力是不可控的自然资源,其强度和方向难以完全预测,造成风力预测的不确定性。此外,预测结果也会受到市场需求变化、环境调整、资源调配等因素的影响,导致结果的不稳定性。所以需要提高数据分析能力、通过改进算法,并结合实时监测与调整,才能逐步减小误差、提高预测的准确性,从而促进风电产业的可持续发展。
3、传统的功率预测系统大多不具备误差溯源和结果追踪的功能。例如,可能会忽略风电场的地貌或季节特征,从而低估或高估了风电场的出力情况,由于缺少误差因果分析和结果量化将原因单纯归结于数值天气预报不准确。
技术实现思路
1、本发明针对现有技术中存在的技术问题,提供一种基于主成分分析的短期风电功率预测误差成因评估方法,以解决上述背景技术中提出的问题。
2、本发明解决上述技术问题的技术方案如下:一种基于主成分分析的短期风电功率预测误差成因评估方法,具体包括以下步骤:
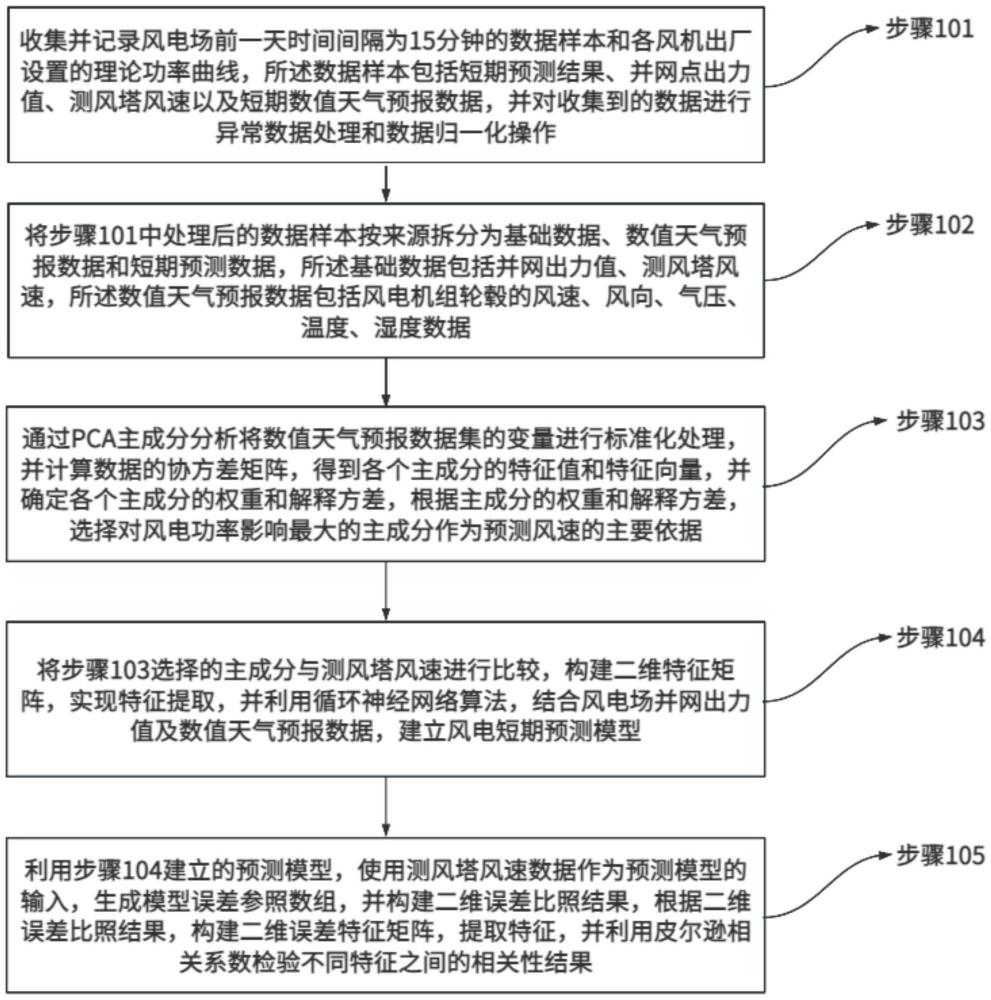
3、步骤101、收集并记录风电场前一天时间间隔为15分钟的数据样本和各风机出厂设置的理论功率曲线,所述数据样本包括短期预测结果、并网点出力值、测风塔风速以及短期数值天气预报数据,并对收集到的数据进行异常数据处理和数据归一化操作;
4、步骤102、将步骤101中处理后的数据样本按来源拆分为基础数据、数值天气预报数据和短期预测数据,所述基础数据包括并网出力值、测风塔风速,所述数值天气预报数据包括风电机组轮毂的风速、风向、气压、温度、湿度数据;
5、步骤103、通过pca主成分分析将数值天气预报数据集的变量进行标准化处理,并计算数据的协方差矩阵,得到各个主成分的特征值和特征向量,并确定各个主成分的权重和解释方差,根据主成分的权重和解释方差,选择对风电功率影响最大的主成分作为预测风速的主要依据;
6、步骤104、将步骤103选择的主成分与测风塔风速进行比较,构建二维特征矩阵,实现特征提取,并利用循环神经网络算法,结合风电场并网出力值及数值天气预报数据,建立风电短期预测模型;
7、步骤105、利用步骤104建立的预测模型,使用测风塔风速数据作为预测模型的输入,生成模型误差参照数组,并构建二维误差比照结果,根据二维误差比照结果,构建二维误差特征矩阵,提取特征,并利用皮尔逊相关系数检验不同特征之间的相关性结果。
8、在一个优选地实施方式中,所述步骤101中,收集并记录风电场前一天时间间隔为15分钟的数据样本和各风机出厂设置的理论功率曲线,所述数据样本包括短期预测结果、并网点出力值、测风塔风速以及短期数值天气预报数据,并对收集到的数据进行异常数据处理和数据归一化操作,具体步骤如下:
9、步骤a1、数据源收集:记录风电场每15分钟的实际出力值和风电场附近测风塔的风速数据,获取风电场所在地区的天气预报数据,包括温度、湿度、风速,以及风电场中各风机的出厂设置功率曲线,所述功率曲线反映了每台风机在不同风速下的理论最大功率输出;
10、步骤a2、异常数据处理:从收集到的数据样本中检查缺失值和异常值,针对缺失值,采取填充策略;
11、步骤a3、数据归一化:对处理后的数据进行归一化,通过将不同维度的数据归一化到相同的尺度,以便模型训练更稳定且具有更好的性能。
12、在一个优选地实施方式中,所述步骤102中,将步骤101中处理后的数据样本按来源拆分为基础数据、数值天气预报数据和短期预测数据,所述基础数据包括并网出力值、测风塔风速,所述数值天气预报数据包括风电机组轮毂的风速、风向、气压、温度、湿度数据,具体步骤如下:
13、步骤b1、基础数据拆分:从收集到的数据样本中提取并网出力值和测风塔风速作为基础数据,创建一个基础数据集,包含时间、并网出力值和测风塔风速作为列;
14、步骤b2、数值天气预报数据拆分:从收集到的数据样本中提取数值天气预报数据,创建一个数值天气预报数据集,包含时间、风速、风向、气压、温度、湿度信息作为列;
15、步骤b3、短期预测数据拆分:从数据样本中提取短期预测数据,并创建一个短期预测数据集,包含时间和相应的预测数据作为列;
16、步骤b4、数据存储:将处理后的基础数据、数值天气预报数据和短期预测数据整合到一个统一的数据集中,并将处理后的数据集存储在数据库中,以备后续分析和使用。
17、在一个优选地实施方式中,所述步骤103中,通过pca主成分分析将数值天气预报数据集的变量进行标准化处理,并计算数据的协方差矩阵,得到各个主成分的特征值和特征向量,根据特征向量中的系数,确定各个主成分的权重和解释方差,根据主成分的权重和解释方差,选择对风电功率影响最大的主成分作为预测风速的主要依据,具体步骤如下:
18、步骤c1、标注化数据:从数值天气预报数据集中获取多维数据样本,包括风速、温度、湿度多个变量,并对数据进行标准化处理,使各个变量具有相同的量纲和均值为0、方差为1,以消除不同变量之间的量纲差异;
19、步骤c2、pca主成分分析:使用pca对标准化后的数据进行降维处理,以提取最重要的特征和减少数据的维度,并计算数据的协方差矩阵,进行特征值分解,得到各个主成分的特征值和特征向量,具体计算公式如下:
20、
21、其中,cov(x,y)是协方差矩阵,x和y是两个变量,和分别是它们的均值,n是样本数量;
22、步骤c3、确定权重和解释方差:将特征向量中的系数作为各个主成分的权重,表示每个变量在主成分中的贡献程度,并将每个特征值除以所有特征值之和,得到的比例为每个主成分解释的方差比例;
23、步骤c4、选择主成分:根据特征值的大小选择保留的主成分数量,选择解释总方差的比例最高的主成分,以便保留最重要的信息。
24、在一个优选地实施方式中,所述步骤104中,将步骤103选择的主成分与测风塔风速进行比较,构建二维特征矩阵,实现特征提取,并利用循环神经网络算法,结合风电场并网出力值及数值天气预报数据,建立风电短期预测模型,具体步骤如下:
25、步骤d1、构建特征矩阵:将选择的主成分和测风塔风速数据组合,构建二维特征矩阵,包括实测风速和基于数值天气预报预测风速的主成分,其中,特征矩阵的每一行表示一个时间点的特征,列包括测风塔风速和选定的主成分;
26、步骤d2、误差分析:将基础数据按照风速测量误差、发电损耗和采集间隔误差产生原因进行深入分析,利用条件概率判断和不确定度假设方式分别带入理论功率曲线模型,对误差进行分析和建模,具体计算公式如下:
27、p1=σ|yi-yi(k)|
28、其中,k为i时刻的实测风速,yi为i时刻实测并网点出力,yi(k)为i时刻k对应的理论功率值,p1为基础数据造成的估计误差;
29、此处等式成立先验条件为若ki>0且ki<30时,否则公式中yi(k)为0;另外若存在ki=ki+1=ki+2...,则对应的yi(ki)=yi+1(ki+1)=yi+2(ki+2)=0;
30、步骤d3、模型误差计算:将实测风速与数值天气预报预测风速分别带入理论功率曲线模型得到数值天气预报造成的实际误差,具体计算公式如下:
31、
32、其中,k为i时刻的实测风速,yi为i时刻实际并网有功点功率值,为i时刻的数值天气预报预测风速,yi(k)为i时刻k对应的理论功率值,p2为数值天气预报数据造成的估计误差;
33、此处等式成立先验条件为若ki>0且ki<30时,否则公式中yi(ki)=yi(g(yi));其中,为理论功率曲线,yi(x)的逆函数即根据功率取得估计风速;
34、步骤d4、建立短期风电功率预测模型:将构建的特征矩阵与风电场并网出力值进行对齐,以便建立监督学习模型,设计循环神经网络模型的结构,包括循环神经网络单元、网络层数和隐藏单元数量,并将特征矩阵作为输入序列,风电场并网出力值作为目标序列,用于训练循环神经网络模型,将其作为风电短期风电功率预测模型。
35、在一个优选地实施方式中,所述步骤105中,利用步骤104建立的预测模型,使用测风塔风速数据作为预测模型的输入,生成模型误差参照数组,并构建二维误差比照结果,根据二维误差比照结果,构建二维误差特征矩阵,提取特征,并利用皮尔逊相关系数检验不同特征之间的相关性结果,具体步骤如下:
36、步骤e1、二维误差比照:将测风塔风速数据作为预测模型的输入,生成模型的预测结果,根据预测结果,得到模型误差参照数组,将模型误差参照数组与模型预测样本构建二维误差比照结果,对输出结果进行评估,具体计算公式如下:
37、p3=σ|zi(k)-p|
38、其中,k为i时刻的实测风速,z为风速功率预测模型,p为i时刻的并网点出力,p3为预测模型造成的估计误差;
39、此处等式成立先验条件为若ki>0且ki<30时,否则公式中zi(ki)=zi(g(p)),其中p为i时刻实际并网有功点功率值,g(x)为理论功率曲线,yi(x)的逆函数即根据功率取得估计风速;
40、步骤e2、构建二维误差特征矩阵:对输出结果逐时间分辨率的统计结果求和后与逐时间分辨率的原始误差构建二维误差特征矩阵,对步骤e1的输出结果利用皮尔逊相关系数检验,检验二维特征矩阵中不同特征之间的相关性结果,具体计算公式如下:
41、
42、其中,εi为i时刻样本的误差,ai、bi、ci均为i时刻随机常数,为不确定度引起的随机误差,p1、p2、p3作为样本相关的特征;
43、步骤e3、对步骤e2的结果进行真实占比估计计算,具体计算公式如下:
44、
45、其中,dα表示特征α真实占比估计,pα表示特征α的皮尔逊相关系数,p1+p2+p3分别表示所有特征之间的皮尔逊相关系数之和。
46、本发明的有益效果是:收集风电场前一天时间间隔为15分钟的数据样本和各风机出厂设置的理论功率曲线,并对收集到的数据进行异常数据处理,将处理后的数据样本拆分为基础数据、数值天气预报数据和短期预测数据,将基础数据按误差产生原因进行深入分析,利用条件概率判断和不确定度假设方式分别带入理论功率曲线模型,通过pca主成分分析将数值天气预报数据进行标准化处理,并确定各个主成分的权重和解释方差,选择对风电功率影响最大的主成分作为预测风速的主要依据,利用循环神经网络算法建立预测模型,将测风塔风速数据作为预测模型的输入,构建二维误差特征矩阵,提取特征,利用皮尔逊相关系数检验不同特征之间的相关性结果,以评估预测模型的准确性,本发明通过充分挖掘短期风电功率预测中的误差来源和其贡献的量化评估,更精准地追踪模型误差的来源和波动性,有助于更好地理解数据的特性和模式,并针对性地调整和改进模型的特征选择、变量权重,提升模型的精度和预测能力。
- 还没有人留言评论。精彩留言会获得点赞!