一种基于两阶段聚类的地铁站点特性挖掘方法
本发明涉及一种基于两阶段聚类的地铁站点特性挖掘方法,属于时空数据技术挖掘领域。
背景技术:
1、城市轨道交通是公共交通的重要组成部分,以高效便捷、准时、安全、可靠等优点受到社会各界青睐而迅速发展。城市轨道交通车站不仅是轨道交通网络的关键结点,也是城市结构的重要构成,受出行活动的影响,各站点之间存在显著差异,因此对站点进行精细化分类并以此为基础挖掘地铁站点的时间特性和空间特性可为地铁站点精细化管理如流量预测、流量控制以及周边设施建设和土地利用提供参考。
2、关于城市轨道交通站点分类的研究,主要集中在以下几个方面:1)、以地铁站点服务范围内的土地利用特征进行分类,该方法能够反映出地铁站点服务范围内的空间特性,但需要合理划分地铁站点的服务范围,并需要大量的土地利用数据和poi(points ofinterest)数据。2)、以地铁站点客流量的时间波动特征进行分类,该方法能够反映出地铁站点客流的时间特性,分类标准简单且直观,但需要大量进出站刷卡数据。3)、以地铁站点的自身的交通属性进行分类,如接驳的公交线路数量、距离中心区域的距离、是否为换乘站点等,但是该方法没有考虑地铁站点周边的土地利用特征和地铁站点客流量的时间波动特征,分类标准虽然清晰但比较片面。
3、现有方法中从原因层面出发,考虑了地铁站点服务范围内的空间特性,解释了地铁站点客流的可能成因;从结果层面出发,考虑了地铁站点客流的时间特性,阐述了地铁站点客流的具体特征。然而地铁站点服务范围内的空间特性会造就地铁站点客流的时间特性,地铁站点客流的时间特性又会反向促进地铁站点服务范围内的空间特性。仅考虑空间特性并不能阐述地铁站点客流实际的时间特性;仅考虑时间特性则只能从结果层面阐述地铁站点客流的表面特征而无法解释其形成原因。
4、因此,本领域技术人员亟需将地铁站点实际客流特征与地铁站点周边空间特征相结合,解决地铁站点特性挖掘不全面的技术问题。
技术实现思路
1、目的:为了克服现有技术中存在的不足,本发明提供一种基于两阶段聚类的地铁站点特性挖掘方法,考虑客流时间分布特征和客流量级,提高地铁站点服务范围的划分精度,设计0-1回归模型,对地铁站点类型进行精细化分类,帮助公共交通运营企业更加准确的归类地铁站点,挖掘不同类型站点的时间特性和空间特性,为不同类型站点的运营管理提供决策支持,为地铁站点周边设施建设和土地利用提供理论依据。
2、技术方案:为解决上述技术问题,本发明采用的技术方案为:
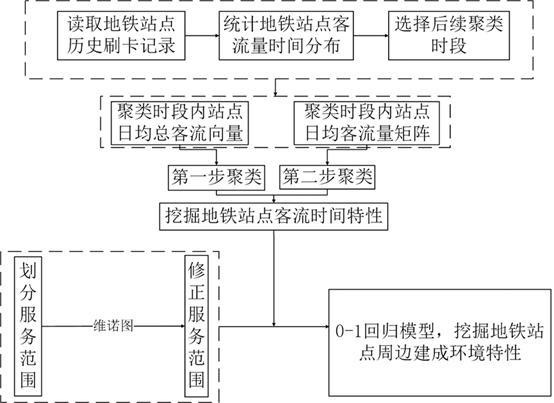
3、一种基于两阶段聚类的地铁站点特性挖掘方法,包括以下步骤:
4、步骤1:获取地铁站点刷卡数据,统计地铁站点客流量的时间分布,确定有效聚类时段。
5、步骤2:计算地铁站点在有效聚类时段内的各时段的日均进站客流量、日均出站客流量,得到地铁站点客流量矩阵、地铁站点总客流对数向量。
6、步骤3:对地铁站点总客流对数向量使用fcm算法,利用肘部法则得到第一步聚类的最优簇数k1。
7、步骤4:基于最优簇数k1,采用fcm算法对各地铁站点总客流对数向量进行第一步聚类,得到基于地铁客流量级的聚类结果。
8、步骤5:对地铁站点客流量矩阵使用fcm算法,利用肘部法则并计算轮廓系数评价聚类效果得到第二步聚类的最优簇数k2。
9、步骤6:基于最优簇数k2,采用fcm算法对地铁站点客流量矩阵进行第二步聚类,得到基于地铁站点客流量矩阵的聚类结果作为时间特性。
10、步骤7:基于地铁客流量级的聚类结果和基于地铁站点客流量矩阵的聚类结果对地铁站点归类,采用维诺图修正地铁站点服务范围,采用0-1回归方法,获取不同类型站点的空间特性。
11、作为优选方案,所述步骤1,具体包括:
12、步骤1.1:读取连续若干天的地铁历史刷卡数据,所述地铁历史刷卡数据包括但不限于:日期、进站时间、出站时间、进站站点和出站站点5个字段;
13、步骤1.2:根据获得的地铁历史刷卡数据,分别统计各地铁站点在各时段的日均进站客流量、日均出站客流量,其中1代表进站、2代表出站,i为地铁站点编号,t为时段编号;
14、步骤1.3:计算所有地铁站点在t时段的日均客流量,i为地铁站点总数量;统计地铁站点日均客流量各时段分布,绘制地铁站点日均客流量时段分布折线图,根据分布折线图选择客流分布密集程度大于密集阈值对应的时段t作为有效聚类时段。
15、作为优选方案,所述步骤2,具体包括:
16、步骤2.1:从、中截取部分,得到有效聚类时段t内的日均进站客流量、日均出站客流量;
17、步骤2.2:将有效聚类时段t内的日均进站客流量当作第一列、日均出站客流量当作第二列,得到地铁站点客流量矩阵;将客流量矩阵同列求和得到地铁站点总客流向量,对地铁站点总客流向量求自然对数得到地铁站点总客流对数向量;其中,t0表示第一个聚类时段,t1表示最后一个聚类时段;
18、步骤2.3:生成地铁站点总客流对数向量数据集,其中xi为样本点,其表达式为:;生成地铁站点客流量矩阵数据集f=,其中。
19、作为优选方案,所述步骤3,具体包括:
20、步骤3.1:对地铁站点总客流对数向量数据集x进行聚类,设定聚类簇数,n1为聚类上限簇数,n2为聚类下限簇数;
21、步骤3.2:基于聚类簇数n,计算每簇的聚类中心cn,其计算公式为:;其中,m为隶属度因子;为对簇中心的隶属度,其满足条件:;
22、步骤3.3:基于聚类中心cn,计算样本点xi对簇中心的隶属度,计算公式为:
23、;
24、其中,cj表示第j个聚类中心;
25、步骤3.4:基于聚类中心cn和隶属度,构建目标函数,并求解目标函数得到第一步聚类的聚类结果;其中,目标函数计算公式如下:
26、;
27、表示欧式距离;
28、步骤3.5:根据第一步聚类的聚类结果画出畸变程度—聚类簇数折线图,利用肘部法则得到第一步聚类的最优簇数。
29、作为优选方案,所述求解目标函数的方法,具体包括:
30、将聚类中心与隶属度代入目标函数开始迭代,其迭代过程如下:
31、a)设定聚类簇数范围,设定隶属度因子m ,设定最大迭代次数,设定误差范围;
32、b)初始化隶属度,需要满足条件;
33、c)根据隶属度计算聚类中心cn;
34、d)将隶属度和聚类中心cn代入目标函数y1计算函数值y1;
35、e)根据聚类中心cn计算隶属度;
36、f)根据隶属度计算聚类中心;
37、g)将隶属度和聚类中心代入目标函数y1计算函数值,计算,当处于误差范围之内则认为目标函数已迭代至最小值,或当迭代次数达到上限,则停止迭代,输出第一步聚类的聚类结果,否则跳转e);
38、基于聚类中心cn,计算各簇的畸变程度,其计算公式如下:
39、;
40、dn为各簇畸变程度,是聚类中心与欧式距离的平方之和;计算聚类簇数n的总畸变程度dn,其计算公式为:,得到在聚类簇数n下的总畸变程度dn,画出dn-n折线图,由肘部法则得出第一步聚类的最优簇数k1。
41、作为优选方案,所述步骤4,具体包括:
42、步骤4.1:基于第一步聚类的最优簇数k1,初始化隶属度;隶属度因子m,最大迭代次数,误差范围;
43、步骤4.2:基于隶属度,计算聚类中心;
44、步骤4.3:基于隶属度、聚类中心cn计算函数值y2:
45、;
46、步骤4.4:基于聚类中心cn,计算隶属度,其计算公式为:
47、;
48、步骤4.5:基于隶属度,计算聚类中心;
49、步骤4.6:基于隶属度、聚类中心计算函数值
50、;
51、步骤4.7:计算,当处于误差范围内则认为y2已经迭代至最小值,或当迭代次数达到上限,则停止迭代,输出基于地铁客流量级的聚类结果,否则跳转步骤4.4。
52、作为优选方案,所述步骤5,具体包括:
53、步骤5.1:对地铁站点客流量矩阵数据集f进行聚类,设定聚类簇数<mstyle displaystyle="true" mathcolor="#000000"><mi>n</mi><mi>∈</mi><mrow><mo>[</mo><mrow><msub><mi>n</mi><mn>1</mn></msub><mi>,</mi><msub><mi>n</mi><mn>2</mn></msub></mrow><mo>]</mo></mrow></mstyle>,其中n1为聚类上限簇数,n2为聚类下限簇数;
54、步骤5.2:基于聚类簇数n,计算每簇的聚类中心cn,计算公式为:
55、;
56、其中,为fi对聚类中心cn的隶属度,其满足条件:;
57、步骤5.3:基于聚类中心cn,计算样本点fi对簇中心的隶属度,计算公式为:
58、;
59、步骤5.4:基于聚类中心cn和隶属度,引入目标函数,并求解目标函数得到第二步聚类的聚类结果;其中,目标函数计算公式如下:
60、;
61、步骤5.5:根据第二步聚类的聚类结果画出畸变程度—聚类簇数折线图,利用肘部法则得到第二步聚类簇数;
62、步骤5.6:根据第二步聚类簇数画出轮廓系数—聚类簇数折线图,评价第二步聚类簇数的聚类效果,得到第二步聚类的最优簇数k2。
63、作为优选方案,所述求解目标函数的方法,具体包括:
64、将聚类中心cn和隶属度代入目标函数开始迭代,其迭代过程如下:
65、a)设定聚类簇数范围,设定隶属度因子m ,设定最大迭代次数,设定误差范围;
66、b)初始化隶属度,需要满足条件;
67、c)根据隶属度计算聚类中心cn;
68、d)将隶属度和聚类中心cn代入目标函数计算函数值y3;
69、e)根据聚类中心cn计算隶属度;
70、f)根据隶属度计算聚类中心;
71、g)将隶属度和聚类中心代入目标函数计算函数值,计算,当处于误差范围之内则认为目标函数已迭代至最小值,或当迭代次数达到上限,则停止迭代,输出第二步聚类的聚类结果,否则跳转e);
72、基于聚类中心cn,计算各簇的畸变程度,其计算公式如下:
73、;
74、dn为各簇畸变程度,是聚类中心与欧式距离的平方之和;计算聚类簇数n的总畸变程度dn,计算公式为:,得到在聚类簇数n下的总畸变程度dn,画出dn—n折线图,由肘部法则得到第二步聚类簇数k2;
75、所述根据第二步聚类簇数画出轮廓系数—聚类簇数折线图,评价第二步聚类簇数的聚类效果,得到第二步聚类的最优簇数k2,具体包括:
76、a)基于聚类结果,计算簇n单一样本点fi的内聚度,计算公式为:
77、;
78、式中,为样本点fi与簇n的其他样本点f的欧氏距离之和,q为簇n的样本点总量;
79、b)基于聚类结果,计算簇n单一样本点fi与除本簇之外其它簇样本点的平均距离最小值bi,计算公式为:
80、;
81、式中,为样本点fi与其它簇样本点的欧氏距离之和,为非簇n的其它簇样本点总量;
82、c)基于ai、bi,计算簇n单一样本点fi的轮廓系数si,计算公式为:
83、;
84、d)基于簇n单一样本点的轮廓系数si,计算簇n的轮廓系数,计算公式为:
85、;
86、e)基于簇n的轮廓系数,计算聚类簇数n的轮廓系数,计算公式为:
87、;
88、画出-n折线图, 评价不同聚类簇数n的聚类效果,得到第二步聚类的最优簇数k2。
89、作为优选方案,所述步骤6,具体包括:
90、步骤6.1:基于第二步聚类的最优簇数k2,初始化隶属度;隶属度因子m,最大迭代次数,误差范围;
91、步骤6.2:基于隶属度,计算聚类中心;
92、步骤6.3:基于隶属度、聚类中心cn计算函数值y4:
93、;
94、步骤6.4:基于聚类中心cn,计算隶属度,计算公式为:
95、;
96、步骤6.5:基于隶属度,计算聚类中心;
97、步骤6.6:基于隶属度、聚类中心计算函数值:
98、;
99、步骤6.7:计算,当处于误差范围内则认为y4已经迭代至最小值,或当迭代次数达到上限,则停止迭代,输出基于地铁站点客流量矩阵的聚类结果,否则跳转步骤6.4;
100、步骤6.8:根据基于地铁站点客流量矩阵的聚类结果得到地铁站点客流随时间波动的规律作为时间特性。
101、作为优选方案,所述步骤7,具体包括:
102、步骤7.1:记地铁站点集合为,其中,pi表示第i个地铁站点,基于地铁站点的坐标,将地铁站点服务半径r划分为内层,外层,是第一半径阈值,是第二半径阈值,将内层与外层合并为地铁站点pi的服务范围;
103、步骤7.2:基于地铁站点的坐标,构建区域的维诺图vvor;
104、步骤7.3:计算地铁站点服务范围与区域维诺图交集,得到地铁站点基于维诺图的服务范围:
105、;
106、其中,内的任意地理点p满足:
107、;
108、根据服务范围获取地铁站点服务范围与区域维诺图的相交边界;
109、当相交边界与地铁站点之间距离小于等于时,内层边界与相交边界共同包围的区域作为的内层区域,的内层边界和外层边界与相交边界共同包围的区域作为的外层区域;
110、当相交边界与地铁站点之间距离大于时,的内层区域作为的内层区域,的内层边界和外层边界与相交边界共同包围的区域作为的外层区域;
111、当不存在相交边界时,的内层区域作为的内层区域,的外层区域作为的外层区域。
112、统计的内、外层范围内居住人口密度、工作人口密度、工作型poi密度、商业型poi密度、餐饮型poi密度、科教文卫型poi密度;
113、步骤7.4:基于地铁客流量级的聚类结果和基于地铁站点客流量矩阵的聚类结果,采用0-1回归方法,进行回归分析,获取不同类型站点的空间特性,具体包括:
114、a)记第一步、第二步聚类结果分别为、,将两阶段聚类结果两两组合,则有;
115、b)以内层范围内居住人口密度、工作人口密度、工作型poi密度、商业型poi密度、餐饮型poi密度、科教文卫型poi 密度作为自变量、以外层范围内居住人口密度、工作人口密度、工作型poi密度、商业型poi密度、餐饮型poi密度、科教文卫型poi 密度作为自变量;
116、c)基于,对每一类聚类结果进行回归分析,设定属于的地铁站点对应的因变量为1,不属于的地铁站点对应的因变量为0,回归模型为:
117、;
118、其中,i为地铁站点,zij代表地铁站点i的第j个自变量,为自变量j的系数,为截距,为随机误差;
119、d)分别将各地铁站点自变量、自变量代入回归模型,求出内层的和外层的,当大于0,对应的内层的自变量产生正向促进作用,当小于0,对应的内层的自变量产生反向抑制作用,当大于0,对应的外层的自变量产生正向促进作用,当小于0,对应的外层的自变量产生反向抑制作用;将自变量产生的正向促进作用和反向抑制作用作为空间特性。
120、有益效果:本发明提供的一种基于两阶段聚类的地铁站点特性挖掘方法,本发明结合fcm算法使用两步聚类框架,从客流量级、客流量时间分布规律两个角度对地铁站点进行聚类,使用维诺图修正了地铁站点的服务范围,设计了0-1回归模型,能够更加精确的帮助公共交通运营企业更加准确的归类地铁站点,为不同类型站点的运营管理提供决策支持,为地铁站点周边设施建设和土地利用提供理论依据。
121、本发明将模糊c均值聚类(fcm)算法应用到地铁站点聚类,由于算法的模糊性,站点的类型更加看重站点与聚类中心的隶属度,使得聚类结果更加灵活;本发明从客流时间分布特点和客流量级两个角度出发对地铁站点历史刷卡记录深入挖掘,并使用两阶段聚类法进行聚类,相较于现有的聚类方法其聚类结果更加全面;本发明将地铁站点的服务半径分为内外两层,并结合维诺图修正地铁站点服务范围,能更加准确的划分地铁站点的真实服务范围、反应地铁站点周边的特点;本发明结合两阶段聚类提出0-1回归模型,将地铁站点客流的时间特性与地铁站点服务范围内的空间特性结合在一起,相较于传统方法同时兼顾了时间与空间两方面,对地铁站点特性的挖掘更加全面。
- 还没有人留言评论。精彩留言会获得点赞!