将数据特征与数据标签进行关联保护的方法及系统与流程
本发明涉及数据安全领域,具体涉及一种将数据特征与数据标签进行关联保护的方法及系统。
背景技术:
1、对数据(图像、文本、点云等数据)进行采集后,需要根据任务需求对数据进行数据标注工作,具体是指对收集到的、未处理的原始数据或初级数据,包括语音、图片、文本、视频等类型的数据进行加工处理,并转换为机器可识别信息的过程。
2、常见的数据标注方法包括:
3、(1)矩形框标注:矩形框标注是一种对目标对象进行目标检测框标注的简单处理方式,常用于标注自动驾驶下的人、车、物等。
4、(2)多边形标注:多边形标注是指在静态图片中,使用多边形框,标注出不规则的目标物体,相对于矩形框标注,多边形标注能够更精准地框定目标,同时对于不规则物体,也更具针对性。
5、(3)语义分割:语义分割是指根据物体的属性,对复杂不规则图片进行区域划分,并标注对应上属性,以帮助训练图像识别模型,常应用于自动驾驶、人机交互、虚拟现实等领域。
6、(4)关键点标注:关键点标注模板最大的应用即是对脸部的关键点进行标注,通过不同方位的关键点标注,可以判断图像上的人物的功能。
7、(5)3d点云标注:3d点云标注是指利用激光雷达采集的数据进行框选标注,供计算机视觉与无人驾驶等人工智能模型训练使用。
8、(6)3d立方体标注:与点云标注不同,3d立方体标注还是基于二维平面图像的标注,标注员通过对立体物体的边缘框定,进而获得灭点,测量出物体之间的相对距离。
9、(7)目标追踪:目标追踪是指在动态的图像中,进行抽帧标注,在每一帧图片中将目标物体标注出来,进而描述它们的运动轨迹,这类标注常应用于训练自动驾驶模型以及视频识别模型。
10、(8)属性判别:属性判别是指通过人工或机器配合的方式,识别出图像中的目标物体,并将其标注上对应属性。
11、由此可知,数据标注的工作成本较高,尤其当数据量非常庞大时,数据标注后形成的数据特征(feature)、以及为每个数据特征标记数据标签(label)的工作成本更高。为了非授权方无偿知晓数据特征和数据标签,需要对数据特征和数据标签进行保护。
12、目前,一般采用数据加解算法对数据特征和数据标签进行保护,具体算法包括:
13、(1)md5算法(message-digest algorithm,信息摘要算法),一种被广泛使用的密码散列函数,可以产生出一个128位(16字节)的散列值(hash value),用于确保信息传输完整一致。
14、(2)sha-2算法(secure hash algorithm 2,安全散列算法2)。一种密码散列函数算法标准,属于sha算法之一,其下又可再分为六个不同的算法标准,包括了:sha-224、sha-256、sha-384、sha-512、sha-512/224、sha-512/256。
15、但是,当数据量非常庞大时,采用上述加密算法的计算量非常高,不便于人们使用。
技术实现思路
1、针对现有技术中存在的缺陷,本发明解决的技术问题为:如何在大幅度降低计算量的基础上,将数据特征与对应的数据标签进行数据保护。
2、为达到以上目的,第一方面,本技术实施例提供一种将数据特征与数据标签进行关联保护的方法,包括以下步骤:
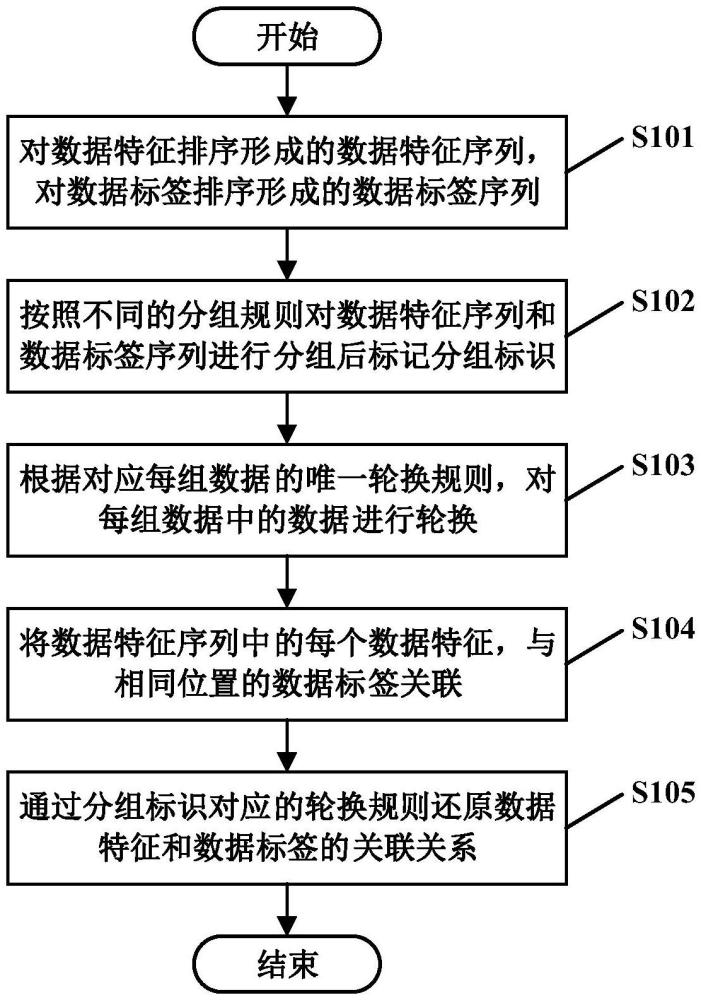
3、数据保护流程:对数据特征和/或数据标签进行排序后,按照预设的分组规则对排序后的数据特征和/或数据标签进行分组后,为每组数据标记唯一的分组标识;根据对应每组数据的轮换规则,对每组数据中的数据进行轮换后,将轮换前数据的关联关系变为轮候后数据的关联关系;
4、数据还原流程:根据每个分组标识和对应的轮换规则,还原对应组的数据特征和/或数据标签的数据排序。
5、结合第一方面,在一种实施方式中,所述将轮换前数据的关联关系变为轮候后数据的关联关系的流程包括:
6、若仅对数据特征进行轮换,将某个数据标签在轮换前关联的数据特征a,变为轮换后位于a位置的数据特征;若仅对数据标签进行轮换,将某个数据特征在轮换前关联的数据标签a,变为轮换后位于a位置的数据标签;若同时对数据特征和数据标签进行轮换,则将轮换后在相同位置数据特征和数据标签进行关联。
7、结合第一方面,在一种实施方式中,当对数据特征或数据标签进行分组时,定义数据特征和数据标签中的1个为主动轮换对象,另一个为被动轮换对象;该方法的步骤包括:对所有主动对象进行排序并按照分组规则进行分组后,为每组主动轮换对象标记唯一的分组标识;根据每组主动轮换对象的轮换规则,对每组主动轮换对象进行数据轮换后,将每个被动轮换对象关联的初始主动轮换对象,修改为轮换后位于初始主动轮换对象位置的主动轮换对象。
8、结合第一方面,在一种实施方式中,当对数据特征和数据标签进行分组时:
9、所述对数据特征和/或数据标签进行排序的流程包括:数据特征排序形成数据特征序列,对数据标签排序形成数据标签序列;
10、所述分组标识包括与数据特征序列分组后的数据对应的数据特征分组标识,以及与数据标签序列分组后的数据对应的数据标签分组标识;
11、所述将轮换前数据的关联关系变为轮候后数据的关联关系的流程包括:将数据特征序列中的每个数据特征,与数据标签序列中相同位置的数据标签关联;
12、所述据还原流程包括:根据数据特征分组标识确定每组数据特征数据和对应的轮换规则,根据每组数据特征的轮换规则还原该组数据特征形成正确的数据特征序列;根据数据标签分组标识确定每组数据标签数据和对应的轮换规则,根据每组数据标签的轮换规则还原该组数据标签形成正确的数据标签序列;将正确的数据特征序列中的每个数据特征,与正确的数据标签序列中相同位置的数据标签关联。
13、结合第一方面,在一种实施方式中,所述轮换规则包括将每组数据分成若干轮换组的分组数据长度,以及每组轮换组的轮换规则;所述根据对应每组数据的轮换规则,对每组数据中的数据进行轮换的流程包括:按照指定长度将每组数据分为若干轮换组,按照每组轮换组的轮换规则对轮换组中的数据进行轮换;所述分组标识包括对应每组数据的分组数据标识,以及对应每组轮换组的轮换分组标识。
14、结合第一方面,在一种实施方式中,所述每组轮换组的轮换规则为唯一的轮换规则。
15、结合第一方面,在一种实施方式中,所述数据还原流程包括:将分组标识发送给授权方,收到授权方发出的数据还原请求、且数据还原请求中的分组标识和身份信息正确时,通过分组标识对应的轮换规则还原数据特征和数据标签的关联关系。
16、结合第一方面,在一种实施方式中,所述分组规则为指定每组的数据长度。
17、第二方面,本技术实施例提供了一种将数据特征与数据标签进行关联保护的系统,该系统用于实现第一方面提供的方法。
18、第三方面,本技术实施例提供了一种存储介质,该存储介质上存储有计算机程序,所述计算机程序被处理器执行时实现第一方面提供的方法。
19、与现有技术相比,本发明的优点在于:
20、本发明通过指定数据轮换的规则调整数据特征和/或数据标的数据排序顺序,鉴于数据特征和数据标签是存在对应的关系的,因此只要数据特征和数据标签中的1个排序错乱,即使另一个排序正确,也无法得知数据特征和数据标签的对应关系。因此,本发明通过简单的数据轮换调整的方式实现了数据特征与数据标签的关联保护,与现有技术中采用数据加解算法对数据特征和数据标签进行保护相比,本发明的数据轮换过程非常简单,所需计算量非常小,非常适于实用和推广。
- 还没有人留言评论。精彩留言会获得点赞!