一种基于NABC-BiGRU和自注意力机制的时间序列预测方法
本发明涉及工控网络安全防御,尤其涉及一种基于nabc-bigru和自注意力机制的时间序列预测方法。
背景技术:
1、近年来,随着两化融合、新基建、制造强国等战略的推进,工业控制系统与互联网的融合逐渐加深。当这些工控系统暴露在互联网下,越来越多的网络攻击极大地威胁了工控系统的正常运行,因此亟需引入一些设备和技术对工业控制网络进行有效防护。
2、在众多应对未知安全威胁的防护方法中,蜜罐和蜜网技术受到了极大的关注。蜜罐技术是一种主动防御方法,主要通过模拟真实设备吸引攻击者从而获取信息。蜜网技术则是对蜜罐技术的发展,能够将多个蜜罐通过网络组合在一起构成蜜网,可以通过蜜网模拟一个比较完善的体系。但是,目前研究出的工控蜜网仍旧无法较好地模拟真实工控系统,大多数工控蜜网仅仅考虑增强蜜罐单体设备的交互能力,虽然能够增加响应序列,但忽略了对攻击者持续响应及缺乏对蜜网内设备之间通信交互方法的研究。因此,在模拟真实工控系统网络环境时存在缺陷,如何提高工控蜜网的持续响应能力成为了一个非常棘手的问题。
3、时间序列可看作一组按照时间顺序排列的随机变量,分析一段时间内的数据来获取重要的特征。时间序列预测就是通过前一段时间的数据预测生成后续的数据信息。
4、论文“wang x f,zhang y.multi-step-ahead time series prediction methodwith stacking lstm neural network[c].2020 3rd international conference onartificial intelligence and big data(icaibd),chengdu,2020:51.”提出了一种基于堆叠lstm神经网络的多输出迭代预测模型,用于解决减少长期时间序列预测的误差积累和误差传播并且降低了迭代策略的计算复杂度。虽然该方法能够减少误差传播与积累并具有较好的长期预测性能,但此方法使用的前提是单一领域的数据集,无法较好地模拟真实工控系统。
5、论文“guangxu chen,hailong tian,et al.time series forecasting of oilproduction in enhanced oil recovery system based on a novel cnn-gru neuralnetwork[j].geoenergy science and engineering,2024:2949-8910.”提出一种基于cnn-gru的时间序列预测模型,该模型具有较强的泛化能力,能够准确地描述变量之间的非线性关系,并且不需要对储备池类型和储备池性质进行预先假设,根据历史生产数据即可快速进行预测。虽然该方法具有较好的预测能力,但相比于gru模型,它需要更长的运行时间,并且仅仅考虑了单个变量的影响。
6、综上所述,现有的工业控制领域的时间序列预测方法存在实用性差、考虑问题片面、场景过于单一等问题,导致其准确率低,难以在工业控制网络中进行应用,实用性和参考性不高。为了实现具有持续响应能力的工控蜜网,本发明提出了一种基于nabc-bigru和自注意力机制的时间序列预测方法。
技术实现思路
1、本发明提出了一种基于nabc-bigru和自注意力机制的时间序列预测方法,该方法具备高交互性,能够预测蜜网内部设备间的通信行为和单个蜜罐内部的状态信息数据,提高对攻击者的诱捕能力。与使用传统人工蜂群算法的模型相比,该模型向最优值收敛的速度大幅提升,并且数据预测准确率也有所提高。与使用单一网络的模型相比,该模型吸收了不同网络的优点,能够生成持续响应的数据信息,从而提高工控蜜网的仿真能力和持续响应能力,进一步有效提高对攻击者的诱捕能力。
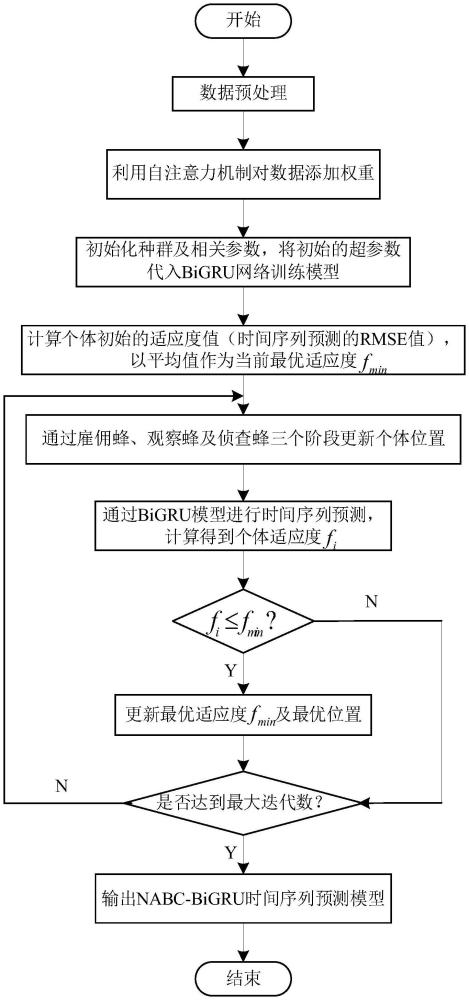
2、本发明的技术方案如下:一种基于nabc-bigru和自注意力机制的时间序列预测方法,采集时间实例数据,通过权重添加层利用自注意力机制为数据添加权重;神经网络预测层使用双向gru模型,采用改进的人工蜂群算法对双向gru模型的超参数进行优化,添加权重后的数据经神经网络预测层进行预测。
3、所述权重添加层根据数据特点,利用自注意力机制为数据添加权重,具体步骤如下:
4、步骤1.1、对输入的m维数据样本z(t)={z1,z2,…,zm}作常规运算,分配相应权重βi和偏置向量bi:
5、
6、步骤1.2、利用tanh激活函数建立不同时间实例zi间的映射关系,根据不同时间实例对时间序列预测的贡献而分配相应权重值qi,计算公式如下:
7、
8、步骤1.3、利用softmax函数对qi进行归一化处理,计算公式如下:
9、
10、步骤1.4、将权重值与其对应数据样本相乘,所有结果组合得到输出数据f={α1z1,…,αmzm},作为后续神经网络预测层的输入数据。
11、所述双向gru模型的超参数优化过程如下:
12、步骤2.1、初始化种群和相关参数,即随机生成n个超参数组{x1,x2,…,xn},再利用改进的人工蜂群算法生成双向gru模型的最优初始超参数组合;
13、步骤2.2、将初始超参数代入到双向gru模型中;经权重添加层处理后的数据输入至双向gru模型中,将时间序列预测的均方根误差rmse作为适应度的值fit(),样本数据在当前超参数xi下的初始适应度为fit(xi),将个体初始适应度fit(xi)的平均值作为当前最优适应度fbest,其中个体适应度fit(xi)则表示样本数据在当前选择的超参数xi下的预测效果;
14、步骤2.3、通过雇佣峰、观察蜂和侦察峰三个阶段优化并更新超参数的值,并通过双向gru模型进行时间序列预测,计算个体适应度fit(xi);
15、步骤2.4、将当前个体适应度fit(xi)与最优适应度fbest进行比较,fit(xi)小于fbest,更新超参数组合的值和最优适应度fbest,否则不断重复步骤2.3直到达到最大迭代数m,当达到最大迭代数时输出优化后的双向gru模型。
16、所述改进的人工蜂群算法具体为:
17、步骤2.3.1、初始化阶段;随机生成n个超参数组{x1,x2,…,xn},其中每组超参数xi有c个元素{xi1,xi2,…,xic},xij代表第i组超参数的第j个元素的值,初始化元素取值的上限为uc、下限为dc,设置试验限制limit以及最大迭代数m,计算初始超参数的值xi,具体公式如下:
18、xij=dc+rand(0,1)*(uc-dc)i∈{1,...,n},j∈{1,...,c}
19、步骤2.3.2、变异阶段,在初始化阶段后面添加一个变异函数;将n个超参数组合一分为二,对后一半的超参数组使用变异函数,使其能够根据第i组超参数中元素的值xij的大小变异为新的数值;具体公式如下:
20、
21、步骤2.3.3、雇佣峰阶段,选择一组超参数xi,通过与之不同的一组超参数xk辅助随机生成一个新的超参数组合yi,其中yi不包含在初始的n组超参数中,同时避免n组超参数内其他组合的干扰,用一个随机变量μij对yi进行调整,根据实际情况调整μij的数值,之后计算样本数据在超参数yi下的预测效果适应度fit(yi),当前的fit(yi)比fit(xi)更小,则用yi替换xi,从而对n个超参数组进行更新,具体公式如下,xkj代表第k组超参数的第j个元素的值:
22、yij=xij+μij*(xij-xkj)k≠i∈{1,...,n},j∈{1,...,c}
23、步骤2.3.4、观察蜂阶段,基于轮盘赌选择公式和sigmoid函数提出新的概率计算公式以及概率选择公式,计算选择当前超参数xi的概率pi,fit(xi)为样本数据中第i组超参数xi下的适应度值,当pi大于0至1间的一个随机数rand()时,则用xi再次从步骤2.3.3开始执行判断是否需要对超参数组进行更新,否则,执行步骤2.3.5,具体公式如下:
24、
25、步骤2.3.5、侦察峰阶段,当对每个超参数xi执行的搜索或更新操作的次数大于等于试验限制时,会生成新的超参数组xi+1,用于避免生成的超参数组无法在长时间迭代后向最优解收敛,没有到达试验限制limit则判断是否到最大迭代次数m,没到达m则执行步骤2.3.3,到达最大迭代次数则执行步骤2.3.5,具体公式如下:
26、
27、步骤2.3.5、当超过最大迭代次数m时,则输出最优的一组超参数xi。
28、本发明的有益效果:本发明针对当前工控蜜网对攻击者无法持续交互响应以及诱捕能力低的问题,提出了一种基于nabc-bigru和自注意力机制的时间序列预测方法,关键点主要包括以下三点:
29、提出一种基于改进的人工蜂群算法,在对bigru神经网络最优超参数组合的选择方式这个方面给出了改进的方案,不仅能够较快地向最优值收敛,还能获取更优的最优值。
30、利用自注意力机制给数据添加适应性权重,并结合改进后的人工蜂群算法对bigru神经网络的超参数进行优化,提高时间序列的预测精度。
31、将所提出的方法应用于工控蜜网内设备间的通信仿真中,为各个设备预测生成仿真数据,能够有效提高工控蜜网的持续响应能力,并进一步提高对攻击者的诱捕能力。
- 还没有人留言评论。精彩留言会获得点赞!