一种医疗检验单的数据信息提取分析方法
本发明涉及检验单数据提取,具体涉及一种医疗检验单的数据信息提取分析方法。
背景技术:
1、医疗检验单上记录了患者的医疗检验信息,传统利用人工输入的方式提取医疗检验单上的医疗检验信息,速度较慢效率较低,且需要较大的人力成本,所以现在一般采用数据信息扫描、拍摄提取的方式,完成检验单数据的提取。
2、公开号为cn110378347a的发明专利,公开了一种医疗检验单的关键信息提取方法及装置,依次识别出目标检验单中的各个字符和每个字符对应的左边界坐标和右边界坐标,从而根据所有字符各自对应的左边界坐标和右边界坐标将目标检验单中的所有字符分割成多个文本行,并将每个文本行分割成多个字符块,最终利用关键词匹配的方式从所有字符块中提取出目标检验单中的关键信息。该方法及装置能够准确提取出医疗检验单中的关键信息,克服了现有技术中难以准确提取医疗检验单中的数据的问题,有利于将患者的医疗检验单中的关键信息存储入库,以使得能够将患者的健康信息进行有效地共享流通。
3、然而在进行医疗检验单的信息提取时,首先要将检验单纸面上的信息转换成图像信息、数字信息,然而在进行信息转换的过程中,可能会因为拍摄角度的倾斜,纸面被遮挡、污染等原因,导致图像出现一定畸变,降低信息识别的准确度,或导致图像信息缺失,从而使得提取后的信息的缺失。
技术实现思路
1、本发明的目的是提供一种医疗检验单的数据信息提取分析方法,以解决现有技术中的上述不足之处。
2、为了实现上述目的,本发明提供如下技术方案:一种医疗检验单的数据信息提取分析方法,包括以下步骤:
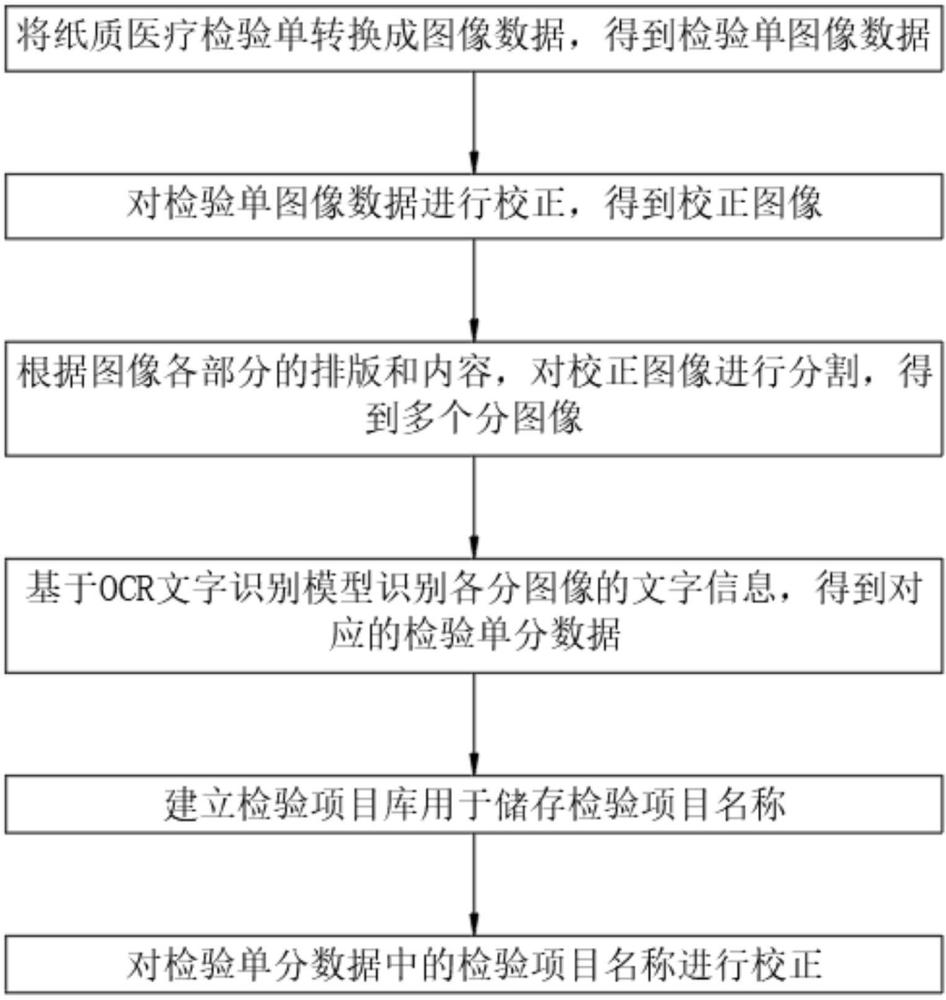
3、将纸质医疗检验单转换成图像数据,得到检验单图像数据,例如可通过扫描、拍照等方式将纸质的医疗检验单转换检验单图像数据;
4、若是采用拍照的方式得到检验单图像数据,则存在不能保证拍摄的角度与纸质医疗检验单垂直,即拍摄的角度会存在一定的倾斜角度,导致得到的检验单图像存在一定倾斜和畸变,因此需要对所述检验单图像数据进行校正,得到校正图像,其中对图像进行校正为现有技术,且在此作无更改直接应用,因此在该技术方案中不做具体赘述,且基于本领域下不会对该技术方案造成困扰,例如可利用透视变换的方法对畸变图像进行校正;
5、根据图像各部分的排版和内容,对所述校正图像进行分割,得到多个分图像,因为医疗检验单中包括如患者信息、检验信息、医院信息等多种类型的信息,经过实际的文字识别的测试可知,对医疗检验单整体进行检测会提高检测的难度,降低文字识别的精度,对将图像分割后再进行识别,精确度就会高很多,因此需要在进行文字识别前对图像进行分割;
6、基于ocr文字识别模型识别各所述分图像的文字信息,得到对应的检验单分数据,利用ocr文字识别模型为现有技术下的公知常识,且在此作无更改直接应用,因此在该技术方案中不做具体赘述,且基于本领域下不会对该技术方案造成困扰;
7、建立检验项目库,所述检验项目库用于储存检验项目名称,检验项目名称例如:白细胞、中性粒细胞计数、中性粒细胞百分比等;
8、将所述检验单分数据中的检验项目名称与检验项目库中的检验项目名称对比,基于最高相似度判断检验单分数据中的检验项目名称是否准确,若否则通过与检验单分数据中的检验项目名称相似度最高的检验项目库中的检验项目名称,对检验单分数据中的检验项目名称进行校正;
9、根据图像各部分的排版和内容,对所述校正图像进行分割,得到多个分图像,具体包括以下步骤:
10、根据校正图像各部分的排版和内容,编辑多个分割模板;
11、人工选择与校正图像对应的分割模板,并对所述分割模板进行调整;
12、使用调整后的分割模板对校正图像进行分割,得到多个分图像,并将校正图像及其对应的分图像储存到分割样本库中;
13、将使用相同分割模板的校正图像分为一类,得到多个模板组,并将模板组与对应的分割模板关联;
14、将分割样本库中的校正图像及其对应的分图像进行向量化,得到校正图像向量和分图像向量;
15、将需要分割的校正图像向量化,并通过计算向量距离,得到与需要分割的校正图像相似的分割样本库中的校正图像及其对应的模板组;
16、对得到的模板组关联的分割模板进行调整,使用调整后的分割模板对需要分割的校正图像进行预分割,得到若干组预分割图像,即进行多次调整,每次调整均得到一组对应的预分割图像;
17、通过计算向量距离,计算每组预分割图像与得到的模板组的校正图像对应的分图像的相似度;
18、选择使得相似度最高的一组预分割图像作为需要分割的校正图像的分图像。
19、进一步的,根据图像各部分的排版和内容,对所述校正图像进行分割,得到多个分图像,具体包括以下步骤:
20、人工对校正图像进行分割,得到多个分图像,并将校正图像及其对应的分图像储存到分割样本库中;
21、基于分割样本库中的校正图像和分图像,训练深度卷积神经网络模型,得到图像分割模型;本技术并不限制具体的深度卷积神经网络模型,可根据需要进行选择,例如可使用r-cnn模型。
22、将需要分割的校正图像,输入图像分割模型,输出该校正图像的分图像。
23、进一步的,所述深度卷积神经网络模型使用u-net模型,使用relu激活函数,损失计算选择交叉熵损失函数,relu激活函数如下式:
24、f(u)=max(0,u),
25、其中,u为输入的数据,f(u)为relu激活函数的输出,用于把大于0的数据都保留,而小于0的数据直接清零;
26、交叉熵损失函数,基于softmax函数:
27、,
28、其中,为样本中的第i 个元素,为第j个神经网络输出,n为输出个数即分类类别数;
29、则损失函数e为:
30、,
31、其中,a表示各个分量,p与q分别表示真实分布与预测分布,e(p,q) != e(q,p)。
32、进一步的,所述分割模板包括边框、分割线;
33、所述边框与校正图像的边缘重合,用于在分割时确定分割模板的位置,即给分割模板定位;
34、所述分割线至少有一条,所述分割线的端点与边框或其他分割线连接;且所述分割线水平或竖直。
35、进一步的,所述方法还包括对分割模板进行调整,具体包括以下步骤:
36、a、选择一条分割线沿水平或竖直方向移动;
37、b、当分割线的数量大于一条,且存在分割线与选择的分割线连接时,与选择的分割线连接的分割线,随选择分割线的移动进行相应伸缩;
38、c、更换选择的分割线返回步骤a,直至调整完成。
39、进一步的,所述方法还包括建立检验项目名称与对应的检验结果、检验参考范围、单位所在位置的关联关系,用于通过建立关联关系的其中一项检索到与该项建立关联关系的其他项,检索时首先定位输入项的位置,再通过关联关系检索到与输入项的位置关联的其他位置,最后确定其他位置中的内容。
40、进一步的,对检验单分数据中的检验项目名称进行校正,还包括以下步骤:
41、基于所述关联关系,检索与校正后的项目名称的位置关联的检验参考范围和单位的位置,得到检验参考范围和单位的位置对应的检验参考范围和单位;
42、对比得到的检验参考范围和单位与校正后的检验项目名称是否匹配,对比是否匹配时同理,可通过关联关系在历史数据中检索,得到与校正后的项目名称的位置关联的位置的检测参考范围和单位,进行对比;
43、若不匹配,则排除该校正后的检验项目名称,重新通过与检验单分数据中的检验项目名称相似度最高的检验项目库中的检验项目名称,对检验单分数据中的检验项目名称进行校正。
44、1、与现有技术相比,本发明提供的一种医疗检验单的数据信息提取分析方法,通过图像校正,和基于深度卷积神经网络模型,训练得到图像分割模型,和通过设置分割模板,基于向量化的相似度分析,可按检验单图像的内容和排版特征,对图像进行自动分割,使得在进行文字识别时,避免对检验单的完整图像进行识别,可对分割后的图像分别进行识别,提高了检验单识别的精度。
45、2、与现有技术相比,本发明提供的一种医疗检验单的数据信息提取分析方法,通过建立检测项目名称库和检验项目名称与对应的检验结果、检验参考范围、单位所在位置的关联关系,实现在检验项目名称出现错误或误差时,进行自动校正,进一步提高了识别出的检验单数据的精度。
- 还没有人留言评论。精彩留言会获得点赞!