本发明涉及及机器学习,尤其涉及一种逻辑回归模型的训练方法、联邦训练方法。
背景技术:
1、金融、通信等领域的企业通常都拥有大量的数据,企业都将自己的数据作为核心资产进行保护防止泄露,企业常常根据用户数据,预测用户是否会发生某种行为,例如,金融企业根据用户画像,预测用户的违约风险。目前,企业通常采用各种预测模型来实现对用户行为的预测,其中逻辑回归模型是一种应用面很广泛的预测模型。
2、目前,一般采用梯度下降法对逻辑回归模型进行训练,该方法为:先进行前向传播,利用数据特征的权重求出预测值,再反向传播,利用预测值求解梯度,循环迭代直到训练结束得到最优模型权重。梯度下降法的关键在于向着梯度下降的方向更新数据特征的权重,而梯度是通过逻辑回归模型的预测值求解出的,因此需要给逻辑回归模型的数据特征权重进行初始化。传统的逻辑回归模型的数据特征权重的初始化是随机初始化,随机初始化会导致逻辑回归模型首次迭代得到的梯度的方向是随机的,因此在训练迭代的过程中需要更多的迭代次数调整数据特征权重,导致模型训练不能快速收敛,训练时间很长。
技术实现思路
1、本发明为了解决上述技术问题,提供了一种逻辑回归模型的训练方法、联邦训练方法,其根据数据特征的iv值排序初始化逻辑回归模型的数据特征权重,使得逻辑回归模型首次迭代得到的梯度符合梯度下降方向,从而加速模型训练收敛,减少训练时间。
2、为了解决上述问题,本发明采用以下技术方案予以实现:
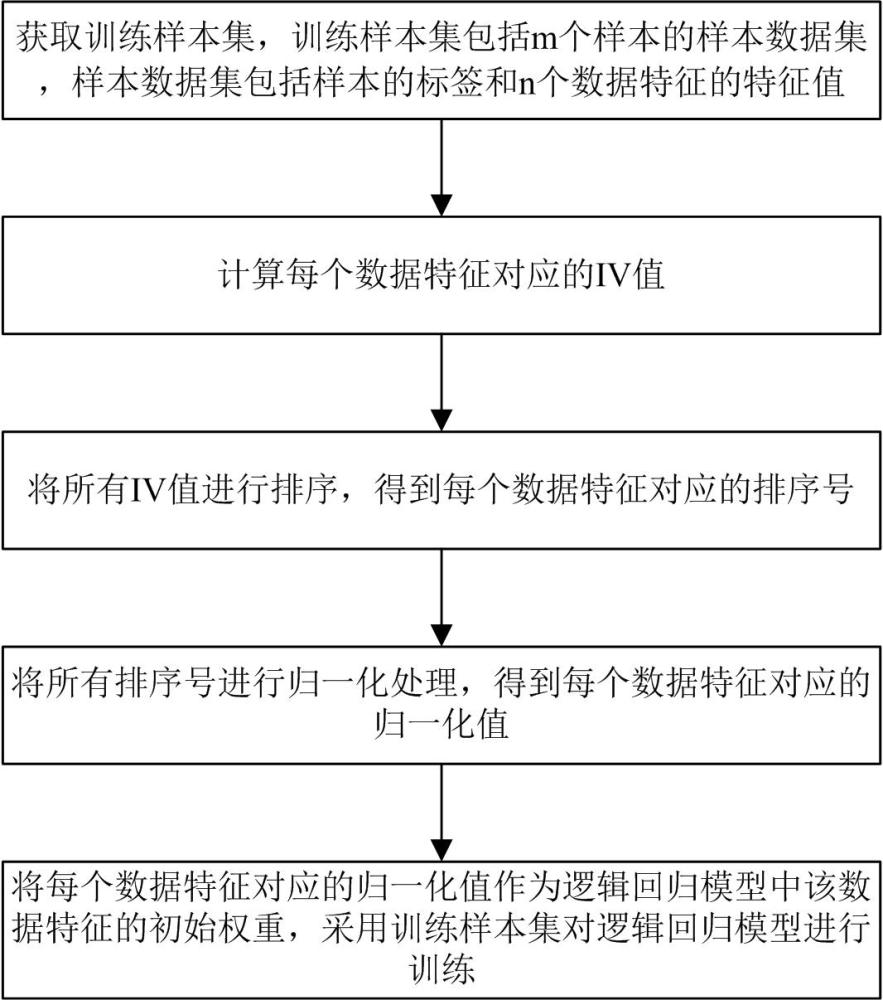
3、本发明的一种逻辑回归模型的训练方法,包括以下步骤:
4、s1:获取训练样本集,所述训练样本集包括m个样本的样本数据集,所述样本数据集包括样本的标签和n个数据特征的特征值;
5、s2:计算每个数据特征对应的iv值;
6、s3:将所有iv值进行排序,得到每个数据特征对应的排序号;
7、s4:将所有排序号进行归一化处理,得到每个数据特征对应的归一化值;
8、s5:将每个数据特征对应的归一化值作为逻辑回归模型中该数据特征的初始权重,采用训练样本集对逻辑回归模型进行训练。
9、在本方案中,先计算每个数据特征对应的iv值,再将iv值对应的排序号归一化处理后得到的归一化值作为逻辑回归模型中数据特征的初始权重。由于数据特征对应的iv值可以用来衡量数据特征在逻辑回归模型中的预测能力,即表示数据特征对逻辑回归模型的重要性程度,所以利用数据特征的iv值排序初始化逻辑回归模型的数据特征权重,使得逻辑回归模型首次迭代得到的梯度不是随机的,而是符合梯度下降方向,从而减少模型权重的调整迭代次数,收敛更快,加快训练速度。
10、作为优选,将第i个样本的样本数据集记为di={x1(i),x2(i),……xn(i), y(i)},其中,xj(i)为第i个样本的第j个数据特征的特征值,y(i)为第i个样本的标签,1≤i≤m,1≤j≤n;
11、所述步骤s2中计算第j个数据特征对应的iv值的方法包括以下步骤:
12、n1:对m个样本的第j个数据特征的特征值进行分箱,并统计每个分箱中正样本的数量和负样本的数量;
13、n2:根据每个分箱中正样本的数量和负样本的数量计算出每个分箱的iv值;
14、n3:将所有分箱的iv值相加,得到第j个数据特征对应的iv值。
15、作为优选,所述步骤n2中计算出第q个分箱的iv值的公式如下:
16、,
17、其中,为第q个分箱的iv值,badq为第j个数据特征的特征值位于第q个分箱中的负样本的数量,goodq为第j个数据特征的特征值位于第q个分箱中的正样本的数量,badt为训练样本集中所有负样本的数量,goodq为训练样本集中所有正样本的数量,1≤q≤k,k为第j个数据特征的分箱数量。
18、作为优选,所述步骤n1中采用有监督分箱方法或无监督分箱方法对m个样本的第j个数据特征的特征值进行分箱。
19、作为优选,所述步骤s3包括以下步骤:
20、n个数据特征对应的n个iv值组成向量f={iv1,iv2,……ivn},将向量f内的n个iv值进行排序,得到排序号向量g={rank1,rank2,……rankn},其中,ivj为第j个数据特征对应的iv值,rankj为第j个数据特征对应的排序号,1≤j≤n。
21、本发明的一种逻辑回归模型的联邦训练方法,包括以下步骤:
22、s1:发起方读取发起方训练样本集,参与方读取参与方训练样本集,所述发起方训练样本集包括m个样本的样本数据集xa,所述参与方训练样本集包括同样m个样本的样本数据集xb,所述样本数据集xa包括样本的标签和n1个数据特征的特征值,所述样本数据集xb包括样本的n2个数据特征的特征值;
23、s2:发起方计算发起方训练样本集中每个数据特征对应的iv值,参与方在发起方的配合下计算出参与方训练样本集中每个数据特征对应的iv值,参与方将计算出的n2个数据特征对应的n2个iv值发送给发起方;
24、s3:发起方将自身计算出的n1个iv值与参与方发送的n2个iv值统一进行排序,得到每个数据特征对应的排序号;
25、s4:将所有排序号进行归一化处理,得到每个数据特征对应的归一化值,将参与方训练样本集中的数据特征对应的归一化值发送给参与方;
26、s5:发起方将发起方训练样本集中的数据特征对应的归一化值作为逻辑回归模型中该数据特征的初始权重,参与方将参与方训练样本集中的数据特征对应的归一化值作为逻辑回归模型中该数据特征的初始权重,发起方采用发起方训练样本集、参与方采用参与方训练样本集对逻辑回归模型进行联邦训练。
27、作为优选,所述步骤s2中参与方在发起方的配合下计算出参与方训练样本集中每个数据特征对应的iv值的方法如下:
28、m1:参与方对参与方训练样本集中每个数据特征的m个特征值进行无监督分箱;
29、m2:参与方在发起方的配合下计算出每个分箱中正样本的数量和负样本的数量;
30、m3:参与方根据每个分箱中正样本的数量和负样本的数量计算出每个分箱对应的iv值;
31、m4:参与方将每个数据特征对应的所有分箱的iv值相加,得到每个数据特征对应的iv值。
32、作为优选,所述步骤m2中参与方、发起方采用隐私计算方法计算出每个分箱中正样本的数量和负样本的数量,参与方得到明文结果。
33、作为优选,所述步骤s2中参与方在发起方的配合下计算出参与方训练样本集中每个数据特征对应的iv值的方法如下:
34、m1:参与方、发起方采用联邦分箱算法对参与方训练样本集中每个数据特征的m个特征值进行有监督分箱,参与方得到每个分箱中正样本的数量和负样本的数量;
35、m2:参与方根据每个分箱中正样本的数量和负样本的数量计算出每个分箱对应的iv值;
36、m3:参与方将每个数据特征对应的所有分箱的iv值相加,得到每个数据特征对应的iv值。
37、作为优选,所述步骤s3包括以下步骤:
38、发起方将自身计算出的n1个iv值与参与方发送的n2个iv值组成向量h={iv1,iv2,……ivn1+n2},将向量h内的n1+n2个iv值进行排序,得到排序号向量q={rank1,rank2,……rankn1+n2},其中,ivp为第p个数据特征对应的iv值,rankp为第p个数据特征对应的排序号,1≤p≤n1+n2。
39、本发明的有益效果是:根据数据特征的iv值排序初始化逻辑回归模型的数据特征权重,使得逻辑回归模型首次迭代得到的梯度不是随机的,而是符合梯度下降方向,从而减少模型权重的调整迭代次数,收敛更快,加快训练速度。