一种基于正则化融合的多模态情绪识别方法及系统
本发明涉及情绪识别,具体涉及一种基于正则化融合的多模态情绪识别方法及系统。
背景技术:
1、情绪识别是一种人工智能技术,旨在识别和理解人类的情绪状态。情绪识别的依据可以分为内在生理信号和外部行为信息,对于内在生理信号,如脑电、肌电、皮肤电呼吸频率等,对于外部行为信息,如面部表情、语音文本、动态姿势等。随着人工智能技术的不断进步,情感识别在许多领域中得到了广泛的应用,如客户服务、医疗保健、教育等。因此,为了捕捉受试者的情绪状态,可以基于内在生理信号和外部行为信息进行情绪识别。
2、由于外部行为信息在数据采集方面更加方便快捷,所以目前的情绪识别方法多用外部行为信息来进行情绪识别,由于缺乏对内在生理信号的考虑,且受人为的控制干预,情绪预测结果可能无法准确地反映受试者的真实情绪状态;为了克服基于外部行为信息的情绪识别方法存在的缺陷,提出了多模态情绪识别方法,其是一种利用多种数据源来识别和理解人类情绪状态的技术,在该方法实现过程中,各模态之间的相关性和多样性对情绪识别的作用常常被忽略,导致进行多模态特征融合时存在信息缺失等情况,进一步造成情绪识别准确性低下的结果。
技术实现思路
1、为了解决上述现有情绪识别准确性低下的技术问题,本发明的目的在于提供一种基于正则化融合的多模态情绪识别方法及系统,所采用的技术方案具体如下:
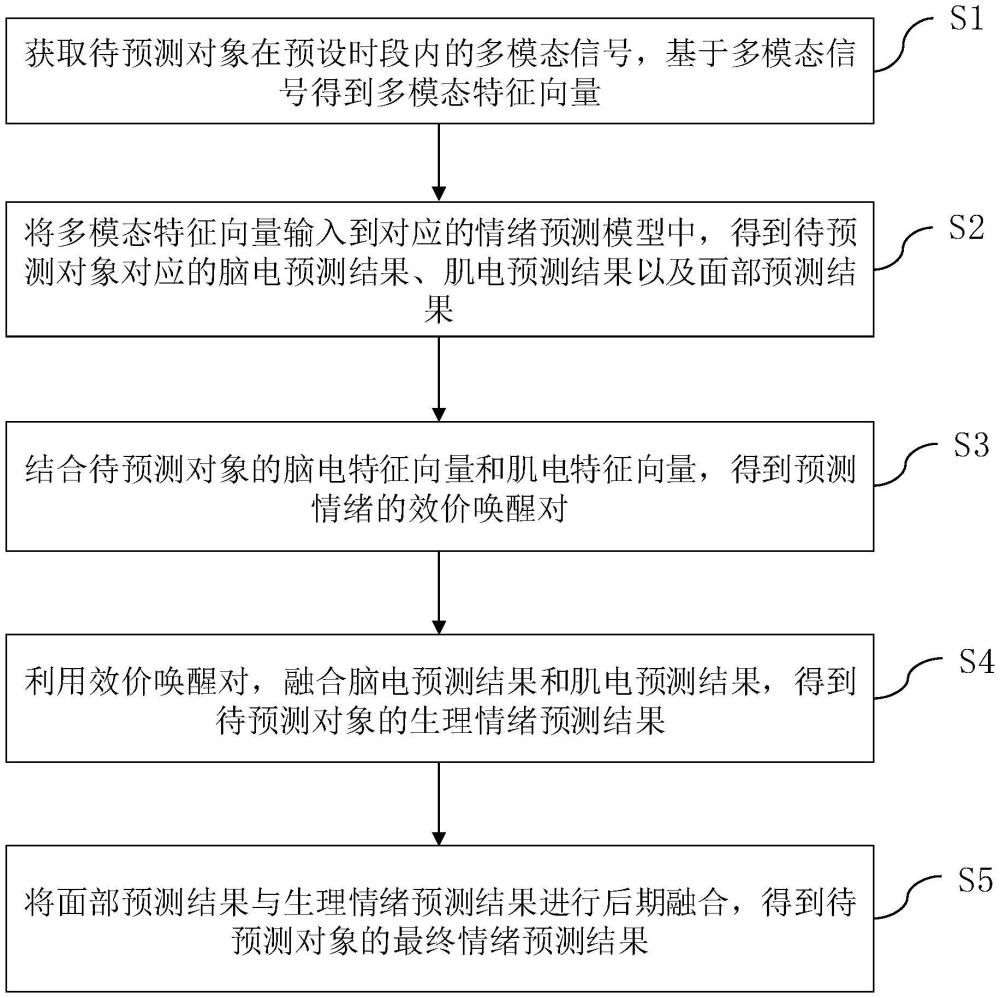
2、本发明一个实施例提供了一种基于正则化融合的多模态情绪识别方法,该方法包括以下步骤:
3、获取待预测对象在预设时段内的多模态信号,基于所述多模态信号得到多模态特征向量;所述多模态特征向量包括脑电特征向量、肌电特征向量以及面部特征向量;
4、将所述多模态特征向量输入到对应的情绪预测模型中,得到待预测对象对应的脑电预测结果、肌电预测结果以及面部预测结果;
5、结合待预测对象的脑电特征向量和肌电特征向量,得到预测情绪的效价唤醒对;其中,所述预测情绪包括脑电预测情绪和肌电预测情绪,所述效价唤醒对由一个效价值和一个唤醒度组成;
6、利用所述效价唤醒对,融合所述脑电预测结果和所述肌电预测结果,得到待预测对象的生理情绪预测结果;
7、将所述面部预测结果与所述生理情绪预测结果进行后期融合,得到待预测对象的最终情绪预测结果。
8、进一步地,所述基于所述多模态信号得到多模态特征向量,包括:
9、所述多模态信号包括脑电信号、肌电信号以及面部信号;利用离散小波变换,对所述脑电信号进行特征提取操作,得到脑电特征向量;
10、对所述肌电信号进行小波阈值变换降噪处理,得到肌电特征向量;
11、采用预训练好的efficientnet模型,从所述面部信号中提取面部特征向量。
12、进一步地,所述将所述多模态特征向量输入到对应的情绪预测模型中,得到待预测对象对应的脑电预测结果、肌电预测结果以及面部预测结果,包括:
13、根据所述脑电特征向量和所述肌电特征向量,利用lsims,得到待预测对象对应的脑电预测结果和肌电预测结果;
14、将所述面部特征向量输入到轻量级的efficientnet模型中,得到待预测对象对应的面部预测结果。
15、进一步地,所述根据所述脑电特征向量和所述肌电特征向量,利用lsims,得到待预测对象对应的脑电预测结果和肌电预测结果,包括:
16、采用k-means对所述lsims进行初始化处理,得到初始化后的lsims;
17、将所述脑电特征向量或所述肌电特征向量称为用于预测的生理情绪特征向量,根据所述用于预测的生理情绪特征向量和所述初始化后的lsims,得到每个通道在每个时刻上的初始生理情绪预测结果;
18、对所述每个通道在每个时刻上的初始生理情绪预测结果进行融合,得到待预测对象对应的生理情绪预测结果,所述生理情绪预测结果包括脑电预测结果或肌电预测结果。
19、进一步地,所述根据所述用于预测的生理情绪特征向量和所述初始化后的lsims,得到每个通道在每个时刻上的初始生理情绪预测结果,包括:
20、获取用于训练的生理情绪特征向量集合,将所述用于训练的生理情绪特征向量集合依次输入到所述初始化后的lsims中,并计算所述初始化后的lsims下的前向概率和后向概率;
21、采用em算法,结合所述前向概率和后向概率,得到更新后的lsims,通过循环更新lsims,得到迭代后的模型;
22、通过维特比算法和所述迭代后的模型,结合所述用于预测的生理情绪特征向量,得到每个通道在每个时刻上的初始生理情绪预测结果。
23、进一步地,所述结合待预测对象的脑电特征向量和肌电特征向量,得到预测情绪的效价唤醒对,包括:
24、将所述待预测对象的脑电特征向量和肌电特征向量输入到adaboost模型中,得到预测情绪的效价唤醒对。
25、进一步地,所述adaboost模型的获取步骤包括:
26、定义所述用于训练的生理情绪特征向量集合中每个训练样本的初始权重;
27、结合每个训练样本的初始权重,对若干个基本分类器进行迭代训练,得到各个基本分类器的权重;
28、根据所述各个基本分类器的权重,利用加权多数表决方法将所有基本分类器组合成一个强分类器,将所述强分类器作为adaboost模型。
29、进一步地,所述利用所述效价唤醒对,融合所述脑电预测结果和所述肌电预测结果,得到待预测对象的生理情绪预测结果,包括:
30、设置若干个情绪的效价唤醒对指标,并对所述效价唤醒对指标进行程度划分,得到所述预测情绪的效价程度和唤醒程度以及离散情绪状态的情绪模型图;其中,所述效价唤醒对指标包括效价指标和唤醒度指标;
31、基于所述预测情绪的效价程度、唤醒程度、效价唤醒对以及生理情绪预测结果的效价唤醒对,得到融合效价值和融合唤醒度;
32、根据所述融合效价值和融合唤醒度,在所述离散情绪状态的情绪模型图中得到待预测对象的生理情绪预测结果。
33、进一步地,所述基于所述预测情绪的效价程度、唤醒程度、效价唤醒对以及生理情绪预测结果的效价唤醒对,得到融合效价值和融合唤醒度,包括:
34、v′=kvvee+(1-kv)vem;
35、
36、a′=kaaee+(1-ka)aem;
37、
38、式中,v′表示融合效价值,kv表示效价融合权重,vee表示脑电预测结果的效价值,vem表示肌电预测结果的效价值,ve表示脑电预测情绪的效价值,vee′表示脑电预测情绪的效价程度,vem′表示肌电预测情绪的效价程度;a′表示融合唤醒度,ka表示唤醒融合权重,aee表示脑电预测结果的唤醒度,aem表示肌电预测结果的唤醒度,ae表示脑电预测情绪的唤醒度,aee′表示脑电预测情绪的唤醒程度,vem′表示肌电预测情绪的唤醒程度。
39、进一步地,所述将所述面部预测结果与所述生理情绪预测结果进行后期融合,得到待预测对象的最终情绪预测结果,包括:
40、确定所述面部预测结果的效价唤醒对,计算所述面部预测结果的效价唤醒对与所述生理情绪预测结果的效价唤醒对之间的距离;
41、若所述距离大于距离阈值,则将面部预测结果作为最终情绪预测结果;
42、若所述距离不大于距离阈值,则根据所述面部预测结果的效价唤醒对与所述生理情绪预测结果的效价唤醒对,对效价唤醒对进行相加取平均,得到新的效价唤醒对;
43、确定所述新的效价唤醒对与所述情绪模型图中距离最近的离散情绪,将所述距离最近的离散情绪作为最终情绪预测结果。
44、本发明一个实施例还提供了一种基于正则化融合的多模态情绪识别系统,该系统包括:
45、向量获取模块,用于获取待预测对象在预设时段内的多模态信号,基于所述多模态信号得到多模态特征向量;所述多模态特征向量包括脑电特征向量、肌电特征向量以及面部特征向量;
46、第一得到模块,用于将所述多模态特征向量输入到对应的情绪预测模型中,得到待预测对象对应的脑电预测结果、肌电预测结果以及面部预测结果;
47、第二得到模块,用于结合待预测对象的脑电特征向量和肌电特征向量,得到预测情绪的效价唤醒对;其中,所述预测情绪包括脑电预测情绪和肌电预测情绪,所述效价唤醒对由一个效价值和一个唤醒度组成;
48、第三得到模块,用于利用所述效价唤醒对,融合所述脑电预测结果和所述肌电预测结果,得到待预测对象的生理情绪预测结果;
49、第四得到模块,用于将所述面部预测结果与所述生理情绪预测结果进行后期融合,得到待预测对象的最终情绪预测结果。
50、本发明具有如下有益效果:
51、本发明提供了一种基于正则化融合的多模态情绪识别方法及系统,其充分考虑不同模态之间的相关性,可以避免进行多模态特征融合时存在信息缺失等情况,有效提高了情绪识别准确性;融合脑电和肌电两方面的内在生理信号,采用两种内在生理信号,运用内在生理信号丰富的空间和时间信息,可以提高情绪预测的准确率;通过脑电和肌电的特征信息指导脑电和肌电的融合,最大限度的保存脑电和肌电的模态信息,得到准确性更高的生理情绪预测结果,进一步增强最终情绪预测结果的可靠程度;对内在生理信号和外部表征信息进行后期融合,结合内在生理信号和外部表征信息两方面信息的优势,提高了情绪预测的准确率和查全率。
- 还没有人留言评论。精彩留言会获得点赞!