基于深度强化学习的多标签分类方法、设备、介质及产品
本发明涉及分类,特别是涉及一种基于深度强化学习的多标签分类方法、设备、介质及产品。
背景技术:
1、近年来,随着机器学习、人工智能技术的发展,传统分类技术已趋于成熟。然而,现有分类模型往往假设数据是易获取的完整数据,实景场景中,这样的假设往往难以成立。例如,在医疗场景中,患者进入医院后进行的医疗检测往往需要花费一定的成本,由于患者本身的预算以及医疗条件的限制等因素,每个患者只能够进行有限的医疗检测,其医疗检测记录会有大量的缺失值存在,在特征不足的情况下直接进行疾病诊断通常难以得到准确的结果。在这种情况下,可以以一定的成本获取数据来进行进一步的诊断。在这个过程中,过多的医疗检测不仅给患者带来经济负担,还可能影响及时的治疗;而过少的医疗检测难以得到准确的疾病诊断。为此,如何学习一种策略,平衡数据获取成本和分类准确性具有重要的意义和价值。
2、在上述医疗场景中,每个患者都是一个独立的样本,医疗检测对应样本中的特征。在该问题中主要存在三个挑战。首先,由于成本预算或者技术条件的限制,无法对每个样本获取全部的特征数据,数据中存在大量缺失值,在训练模型时需要处理带有缺失值的数据,即能够处理不同长度特征值。其次,每个样本需要获取的特征并不相同,因此,需要为每个样本学习个性化的策略,在得到一些特征后,在平衡特征获取成本和分类效果的基础上选择合适的特征。最后,由于每个患者可能同时患有多种疾病,即每个样本可能同时属于多个标签,为此需要进行多标签分类。
3、现实中很多数据的获取需要消耗一定的成本,现有方法在动态特征获取领域进行了一些研究,采用的方法包括基于贝叶斯理论的方法、基于决策树的方法以及基于马尔科夫决策过程的方法等。
4、基于贝叶斯理论的方法是根据数据来估计概率分布,据此来选择合适的特征。这类方法的前提是:数据服从某一特定的概率分布,并且能够从数据中学习到这个概率分布。该类方法通过推断特征之间的依赖关系来达到特征获取成本和分类性能之间的平衡,通常适用于低维的数据。
5、基于决策树的方法是通过使用训练数据构建决策树来指导特征选择的过程,通常针对离散型的变量。如,freitas等人针对成本敏感的特征获取问题,以最小化特征获取成本和误分类成本为目标,提出了一种基于成本敏感的决策树来构建模型。在构建决策树的过程中,对每个节点,算法会启发式地选择最大化单位成本下收益的特征。该类方法可以直观地看到特征选择的过程,比较适合于分类型特征的数据,当特征状态较多时,方法的时间复杂度会很高。
6、基于马尔科夫决策过程的方法是将主动特征获取问题建模成马尔科夫决策过程(mdp)问题,并基于强化学习技术尝试学习最好的特征选择策略来最大化总体回报。dular-arnold等人为了平衡特征使用的稀疏型和分类准确性,提出了一种稀疏分类方法,目标是限制每个样本中特征的使用,用少量的特征完成分类任务。论文将特征选择和分类看作一个序列决策过程,基于马尔科夫决策过程构建模型,并采用近似的策略迭代方法来优化模型;ruckstiess等人将主动特征获取问题形式化为部分观测的马尔科夫决策过程(pomdp),并且采用fitted q-iteration(fqi)来学习pomdp;shim等人和janishch等人针对主动特征获取问题,以最小化分类误差和最小化成本为目标,将问题形式化为一个马尔科夫决策过程,采用q-learning的方法来训练模型。li等人将主动特征获取下的mdp过程重新定义为生成建模任务,提出一个产生式代理模型获取特征之间的依赖,评估特征获取带来的收益。
7、除了上述三类方法外,还有一些论文采用了其他的技术对这一问题进行了研究,如贝叶斯网络和模仿学习等。
8、当前方法从不同的技术角度研究了主动特征获取问题,但这些方法通常假设训练数据的完整性,并且主要针对简单的分类任务,未考虑分类的多标签特性,对于有大量缺失特征的数据难以做出准确的分类,难以适用于真实应用场景,如医疗的疾病诊断场景。
技术实现思路
1、本发明的目的是提供一种基于深度强化学习的多标签分类方法、设备、介质及产品,本发明既节省了特征获取成本,又保证了分类的准确性,同时可在不完整数据下进行个性化多标签分类。
2、为实现上述目的,本发明提供了如下方案:
3、第一方面,本发明提供了一种基于深度强化学习的多标签分类方法,所述基于深度强化学习的多标签分类方法包括:
4、获取医疗特征值集合;所述医疗特征值集合为病人若干个时刻的医疗检测记录。
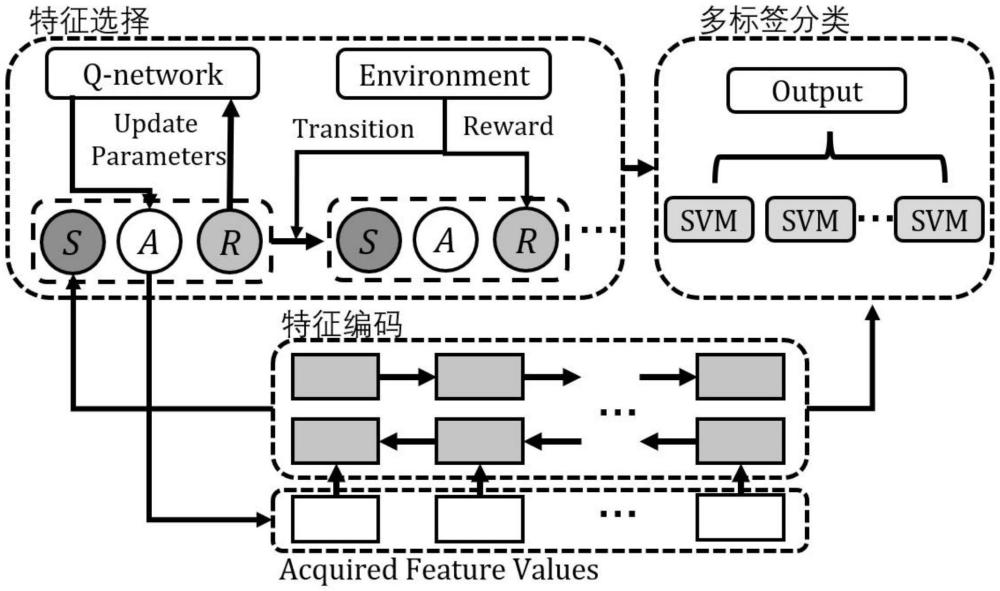
5、确定医疗特征值集合中初始时刻的医疗特征值的状态;所述医疗特征值的状态为智能体所处的状态。
6、将所述初始时刻的医疗特征值的状态输入特征编码器进行编码,得到状态编码;所述特征编码器用于将状态编码成定长向量的集合编码。
7、将所述状态编码输入特征选择器,得到具有最大q函数值的动作;所述特征选择器为dueling网络;所述动作包括:分类动作和特征。
8、判断所述具有最大q函数值的动作是否为分类动作。
9、若否,则进行状态转移,将下一时刻的医疗特征值的状态进行编码,并返回步骤“将所述状态编码输入特征选择器,得到具有最大q函数值的动作”。
10、若是,则将所述状态编码输入多标签分类器,得到最终的分类结果;所述多标签分类器为支持向量机作为基础的二元分类器。
11、可选地,所述特征编码器包括:多层感知机、lstm网络和注意力机制。
12、可选地,将所述状态编码输入特征选择器,得到具有最大q函数值的动作,具体包括:
13、根据所述状态编码,采用∈-greedy策略,得到具有最大q函数值的动作。
14、可选地,所述特征选择器的确定过程,具体包括:
15、将所述状态编码输入所述dueling网络,得到所述dueling网络的预测输出;所述dueling网络的预测输出为根据状态价值函数和动作优势函数确定的值。
16、根据所述dueling网络的预测输出和确定的第一目标函数,确定第一损失值。
17、根据所述第一损失值对所述dueling网络的网络参数进行优化,得到特征选择器。
18、可选地,所述第一目标函数的表达式为:
19、
20、其中,为第一目标损失函数,τ为轨迹,rt为奖励,γ为折扣因子,为目标网络,st+1为新的状态,qθ(st+1,a)为st+1对应的a动作下的q函数值,qθ(st,at)为st对应的at动作下的q函数值。
21、可选地,所述多标签分类器的确定过程,具体包括:
22、将所述状态编码输入所述二元分类器,得到所述二元分类器的分类输出。
23、根据所述二元分类器的分类输出和确定的第二目标函数,确定第二损失值。
24、根据所述第二损失值对所述二元分类器的网络参数进行优化,得到多标签分类器。
25、可选地,所述第二目标函数的表达式为:
26、
27、其中,l为第二目标函数,β为常数,d+为正样本集合,d-为负样本集合,hθ(v)为二元分类器模型。
28、第二方面,本发明提供了一种计算机设备,包括:存储器、处理器以及存储在存储器上并可在处理器上运行的计算机程序,所述处理器执行所述计算机程序以实现上述中任一项所述的基于深度强化学习的多标签分类方法的步骤。
29、第三方面,本发明提供了一种计算机可读存储介质,其上存储有计算机程序,该计算机程序被处理器执行时实现上述中任一项所述的基于深度强化学习的多标签分类方法的步骤。
30、第四方面,本发明提供了一种计算机程序产品,包括计算机程序,该计算机程序被处理器执行时实现上述中任一项所述的基于深度强化学习的多标签分类方法的步骤。
31、根据本发明提供的具体实施例,本发明公开了以下技术效果:
32、本发明提供了一种基于深度强化学习的多标签分类方法、设备、介质及产品,所述基于深度强化学习的多标签分类方法通过将医疗特征值集合中的医疗特征值的状态输入特征编码器,将状态编码成了定长向量的状态编码;由于每个样本中存在大量缺失值,并且在特征获取过程中,每个样本中已获取特征数量各不相同,具有个性化的特征,不定长的特征值数据无法直接输入到特征选择器和多标签分类器中,因此本发明采用集合编码的方法将不定长的特征值数据编码成定长的数据输入到后续的特征选择器和多标签分类器中;通过将状态编码输入特征选择器,得到具有最大q函数值的动作,特征选择器在马尔科夫决策过程中根据当前状态选择一个剩余的特征,实现了平衡特征获取成本和分类的准确性;最后通过多标签分类器可以给出分类结果。本发明充分考虑了特征获取的成本和分类的准确性,这种综合考虑能够更好地满足实际应用中的需求,既节省了特征获取成本,又保证了分类的准确性。同时本发明可在不完整数据下进行个性化多标签分类。
- 还没有人留言评论。精彩留言会获得点赞!