一种辅助安全驾驶的多任务驾驶员视线估计方法及系统
本发明涉及智能交通领域,尤其一种辅助安全驾驶的多任务驾驶员视线估计方法及系统。
背景技术:
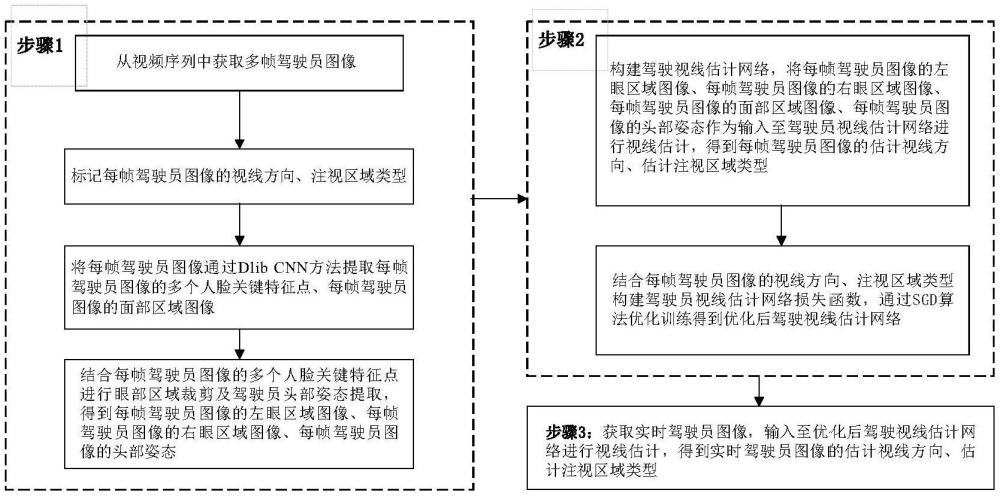
1、驾驶员注意力监测是智能交通领域的研究热点。通过驾驶员视线分析其注视行为,对于驾驶员视觉盲区判断、驾驶行为分析、提高安全驾驶具有重要意义。现有的基于视觉的驾驶员注视区域估计方法根据其使用的特征信息可以分为三类,包括基于头部姿态的方法[1]、基于面部模态的方法[2]以及头部姿态和面部模态相结合的方法[3]。
2、基于头部姿态特征的方法:lee等人[4]提出了一种基于驾驶员头部姿态欧拉角(包括偏航角和俯仰角)的实时驾驶员注视区域估计模型。该模型只需输入简单的面部特征即可计算驾驶员注视区域,并能适应白天和夜间的不同光照条件。lundgren等人[5]利用头部姿态来表示驾驶员的注视方向,提出使用贝叶斯分类器来实现驾驶员在每个视线区域的概率映射。实验结果表明,这种方法在估计部分注视区域时具有一定的优越性,而在一些特定的注视区域(如仪表盘区域)估计精度较低。fridman等人[6]提出了一种人脸面部关键点信息与人脸delaunay三角位置信息相结合的算法。但当驾驶员头部偏转角度过大导致面部信息丢失时,该类依赖人脸面部关键点信息的方法会产生误差。tawari等人[7]提出了一种分布式相机结构,该结构使用头部姿态动力学来估计驾驶员视线区域,即使头部姿态变化很大,框架也能稳定连续运行。由于头部姿态与视线方向之间的关系不是一一对应的,仅使用头部姿态表征驾驶员视线方向在一些场景中存在较大的误差。
3、基于面部特征提取的方法:vora等人[8,9]采用cnn结构训练驾驶员面部特征。他们的实验结果表明,采用半脸区域图像可以取得较好的估计效果。在此基础上,akshay等人[10]进一步提出了一种基于gan网络的驾驶员眼镜摘除模型,他们使用gan网络在视线区域估计之前处理眼镜的遮挡问题。choi等人[2]使用给定的人脸图像对视线区域进行分类,并判断驾驶员的疲劳、注意力集中或分心状态。ghosh等人[11]提出了结合光照鲁棒层的cnn模型来解决人脸图像受光照影响的问题。lollett等人[12]提出一种单相机框架注视区域分类器,该分类器能够在非均匀照明、非正面人脸姿势以及人脸被暂时或永久遮挡的情况下也能稳健地运行。此外,针对驾驶时驾驶员面部可能存在的遮挡、照明或面部距离变化的情况,lollett等人[13]使用三维卷积神经网络模型提取多个相邻帧中驾驶员的视觉特征,这些特征可以表达运动特征,帮助缓解由于缺乏上下文信息而导致的每帧识别系统的缺陷。
4、头部姿态特征与面部特征结合的方法:由于头部姿态与视线并不是一一对应的关系,且头部姿态对驾驶员视线区域的影响较大,因此将头部姿态特征与眼部特征结合的方法有助于提高驾驶员视线。例如,tawari等人[14]通过同时使用眼部图像特征(瞳孔位置信息)及头部姿态进行驾驶员视线区域估计,并对比了单独使用头部姿态、单独使用眼部特征,以及两者结合后视线区域估计的精度,研究结果表明,将头部姿态特征和注视估计任务结合起来有助于提升驾驶员视线区域估计精度。yu等人[15]研究表明,基于头眼特征融合的方法可以通过提取头姿、眼部区域、面部特征以及关键点的位置等多种信息来提升驾驶员注视区域分类的准确率。wang等人[16]提出用一个单独的cnn网络分支来检测头部姿态隐藏特征,然后将隐藏特征与人眼特征融合,最后通过分类器实现驾驶员视线区域估计任务。与其他端到端的方法相比,他们的方法也获得了良好的表现性能。dari等人[17]提出了一种驾驶员视线估计方法,通过结合眼睛关键点位置和头部姿态特征来表征注视方向,然而,驾驶员由于头部偏转过大而导致人眼关键点位置信息的缺失会影响算法的后续处理。
5、另外,实验结果表明,人眼视线不仅与眼部外观特征相关,同时与面部其他特征也存在较大的关系[18,19],因此一些学者探索将全脸特征与头部姿态信息相结合估计驾驶员视线区域。vicente等人[3]提出了一种基于视觉的模型,将头部姿态特征和视线估计任务结合起来,以检测驾驶员视线分布在道路以外区域上的情况。wang等人[20]提出了一种基于icp点云迭代模板匹配的驾驶员头部姿态检测方法。他们使用深度图来获取头部姿态信息,并采用rgb图像来研究驾驶员的视线信息,然后将驾驶员在每个视线区域的初始头部姿态作为点云的模板,并进一步将估计得到的头部姿态与视线进行融合确定驾驶员注视区域。总的来说,驾驶员视线及注视区域与驾驶员的头部姿态、眼部区域特征及全脸图像特征都有较大的关联性,综合多种语义信息对驾驶员视线进行追踪监测,可以提高模型的鲁棒性及准确度,对于辅助安全驾驶具有重要意义。
6、参考文献
7、[1]borghi g,gasparini r,vezzani r,et al.embedded recurrent networkfor head pose estimation in car[z].ieee,20171503-1508.
8、[2]choi i,hong s k,kim y.real-time categorization of driver's gazezone using the deep learning techniques[z].2016143-148.
9、[3]vicente f,huang z,xiong x,et al.driver gaze tracking and eyes offthe road detection system[j].ieee transactions on intelligent transportationsystems.2015,16(4):2014-2027.
10、[4]lee s j,jo j,jung h g,et al.real-time gaze estimator based ondriver's head orientation for forward collision warning system[j].ieeetransactions on intelligent transportation systems.2011,12(1):254-267.
11、[5]lundgren m,hammarstrand l,mckelvey t.driver-gaze zone estimationusing bayesian filtering and gaussian processes[j].ieee transactions onintelligent transportation systems.2016,17(10):2739-2750.
12、[6]fridman l,langhans p,lee j,et al.driver gaze region estimationwithout use of eye movement[j].ieee intelligent systems.2016,31(3):49-56.
13、[7]tawari a,trivedi m m.robust and continuous estimation of drivergaze zone by dynamic analysis of multiple face videos[z].2014344-349.
14、[8]vora s,rangesh a,trivedi m m.driver gaze zone estimation usingconvolutional neural networks:a general framework and ablative analysis[j].ieee transactions on intelligent vehicles.2018,3(3):254-265.
15、[9]vora s,rangesh a,trivedi m m.on generalizing driver gaze zoneestimation using convolutional neural networks[z].ieee,2017849-854.
16、[10]rangesh a,zhang b,trivedi m m.gaze preserving cyclegans foreyeglass removal and persistent gaze estimation[j].ieee transactions onintelligent vehicles.2022,7(2):377-386.
17、[11]ghosh s,dhall a,sharma g,et al.speak2label:using domain knowledgefor creating a large scale driver gaze zone estimation dataset[z].montreal,bc,canada:2021.
18、[12]lollett c,kamezaki m,sugano s.towards a driver's gaze zoneclassifier using a single camera robust to temporal and permanent faceocclusions[c].2021.ieee,2021:578-585.
19、[13]lollett c,kamezaki m,sugano s.single camera face position-invariant driver's gaze zone classifier based on frame-sequence recognitionusing 3dconvolutional neural networks[j].sensors.2022,22(15):5857.
20、[14]tawari a,chen k h,trivedi m m.where is the driver looking:analysis of head,eye and iris for robust gaze zone estimation[c].2014.ieee,2014:988-994.
21、[15]yu z,huang x,zhang x,et al.a multi-modal approach for driver gazeprediction to remove identity bias[z].new york,ny,usa:2020768-776.
22、[16]wang z,zhao j,lu c,et al.learning to detect head movement inunconstrained remote gaze estimation in the wild[z].20203432-3441.
23、[17]dari s,kadrileev n,hüllermeier e.a neural network-based drivergaze classification system with vehicle signals[z].20201-7.
24、[18]krafka k,khosla a,kellnhofer p,et al.eye tracking for everyone[z].20162176-2184.
25、[19]xucong z,yusuke s,mario f,et al.it's written all over your face:full-face appearance-based gaze estimation[z].2017.
26、[20]wang y,yuan g,mi z,et al.continuous driver's gaze zone estimationusing rgb-d camera[j].sensors.2019,19(6).
技术实现思路
1、为了解决上述技术问题,本发明提出了一种辅助安全驾驶的多任务驾驶员视线估计方法及系统,使用基于注意力机制的网络分别提取驾驶员全脸图像特征和左右眼图像特征,能够帮助提取全局及局部更细粒度的图像特征信息,实现驾驶员视线及视区估计两种任务。
2、本发明方法的技术方案为一种辅助安全驾驶的多任务驾驶员视线估计方法,包括如下步骤:
3、步骤1:从视频序列中获取多帧驾驶员图像,标记每帧驾驶员图像的视线方向、注视区域类型,将每帧驾驶员图像通过dlib cnn方法提取每帧驾驶员图像的多个人脸关键特征点、每帧驾驶员图像的面部区域图像,结合每帧驾驶员图像的多个人脸关键特征点进行眼部区域裁剪及驾驶员头部姿态提取,得到每帧驾驶员图像的左眼区域图像、每帧驾驶员图像的右眼区域图像、每帧驾驶员图像的头部姿态;
4、步骤2:构建驾驶视线估计网络,将每帧驾驶员图像的左眼区域图像、每帧驾驶员图像的右眼区域图像、每帧驾驶员图像的面部区域图像、每帧驾驶员图像的头部姿态作为输入至驾驶员视线估计网络进行视线估计,得到每帧驾驶员图像的估计视线方向、估计注视区域类型,结合每帧驾驶员图像的视线方向、注视区域类型构建驾驶员视线估计网络损失函数,通过sgd算法优化训练得到优化后驾驶视线估计网络;
5、步骤3:获取实时驾驶员图像,输入至优化后驾驶视线估计网络进行视线估计,得到实时驾驶员图像的估计视线方向、估计注视区域类型。
6、作为优选,步骤1所述结合每帧驾驶员图像的多个人脸关键特征点进行眼部区域裁剪,得到每帧驾驶员图像的左眼区域图像、每帧驾驶员图像的右眼区域图像,具体如下:
7、根据步骤1中所述每帧驾驶员图像的多个人脸关键特征点中的左眼左侧眼角关键点、左眼右侧关键点计算左眼中心点位置和左眼眼角间的距离,左眼裁剪区域的边长为左眼眼角间距离的一定倍数,依据中心与边长确定左眼裁剪矩形框,进而得到每帧驾驶员图像的左眼区域图像;
8、根据步骤1中所述每帧驾驶员图像的多个人脸关键特征点中的右眼左侧眼角关键点、右眼右侧关键点计算右眼中心点位置和右眼眼角间的距离,右眼裁剪区域的边长为右眼眼角间距离的一定倍数,依据中心与边长确定右眼裁剪矩形框,进而得到每帧驾驶员图像的右眼区域图像;
9、作为优选,步骤1所述结合每帧驾驶员图像的多个人脸关键特征点进行驾驶员头部姿态提取,具体提取过程如下:
10、通过人脸关键点检测算法提取每帧驾驶员图像的多个人脸关键特征点像素坐标;
11、根据每帧驾驶员图像的多个人脸关键特征点像素坐标与标准人脸3d模型中对应的关键点坐标值,使用经典的perspective-n-point算法计算3d人脸坐标系到相机坐标系之间的旋转矩阵及平移矩阵;
12、将所述旋转矩阵作为头部姿态向量,所述头部姿态向量包括:头部姿态的俯仰角、头部姿态的偏航角以及头部姿态的滚转角;
13、通过头部姿态的俯仰角、头部姿态的偏航角以及头部姿态的滚转角构建所述头部姿态向量;
14、作为优选,步骤2所述驾驶视线估计网络,包括:
15、左眼ee-net网络模型、右眼ee-net网络模型、全局面部特征卷积神经网络、第一视线回归全连接层、第二视线回归全连接层、注视区域1×1卷积层、注视区域平均池化层、注视区域线性回归层、注视区域logsoftmax激活层;
16、所述左眼ee-net网络模型,用于输入每帧驾驶员图像的左眼区域图像,进行左眼特征提取得到每帧驾驶员图像的左眼特征;
17、所述左眼ee-net网络模型由第一左眼卷积层、第一左眼激活层、第一左眼扩展卷积层、第一左眼扩展激活层、第一左眼最大池化层、第二左眼卷积层、第二左眼激活层、第二左眼扩展卷积层、第二左眼扩展激活层、第二左眼最大池化层、第三左眼卷积层、第三左眼激活层、第三左眼扩展卷积层、第三左眼扩展激活层、第四左眼卷积层、第四左眼激活层、第四左眼扩展卷积层、第四左眼扩展激活层依次级联构成;
18、所述进行左眼特征提取得到每帧驾驶员图像的左眼特征,具体如下:
19、每帧驾驶员图像的左眼区域图像依次通过第一左眼卷积层进行卷积特征提取、第一左眼激活层进行特征激活、第一左眼扩展卷积层进行模型通道数扩展、第一左眼扩展激活层进行特征激活、第一左眼最大池化层处理、第二左眼卷积层进行卷积特征提取、第二左眼激活层进行特征激活、第二左眼扩展卷积层进行模型通道数扩展、第二左眼扩展激活层进行特征激活、第二左眼最大池化层处理、第三左眼卷积层进行卷积特征提取、第三左眼激活层进行特征激活、第三左眼扩展卷积层进行模型通道数扩展、第三左眼扩展激活层进行特征激活、第四左眼卷积层进行卷积特征提取、第四左眼激活层进行特征激活、第四左眼扩展卷积层进行模型通道数扩展、第四左眼扩展激活层进行特征激活、,得到每帧驾驶员图像的左眼特征;
20、所述右眼ee-net网络模型,用于输入每帧驾驶员图像的右眼区域图像,进行右眼特征提取得到每帧驾驶员图像的右眼特征;
21、所述右眼ee-net网络模型由第一右眼卷积层、第一右眼激活层、第一右眼扩展卷积层、第一右眼扩展激活层、第一右眼最大池化层、第二右眼卷积层、第二右眼激活层、第二右眼扩展卷积层、第二右眼扩展激活层、第二右眼最大池化层、第三右眼卷积层、第三右眼激活层、第三右眼扩展卷积层、第三右眼扩展激活层、第四右眼卷积层、第四右眼激活层、第四右眼扩展卷积层、第四右眼扩展激活层依次级联构成;
22、所述进行右眼特征提取得到每帧驾驶员图像的右眼特征,具体如下:
23、每帧驾驶员图像的右眼区域图像依次通过第一右眼卷积层进行卷积特征提取、第一右眼激活层进行特征激活、第一右眼扩展卷积层进行模型通道数扩展、第一右眼扩展激活层进行特征激活、第一右眼卷积最大池化层处理、第二右眼卷积层进行卷积特征提取、第二右眼激活层进行特征激活、第二右眼扩展卷积层进行模型通道数扩展、第二右眼扩展激活层进行特征激活、第二右眼卷积最大池化层处理、第三右眼卷积层进行卷积特征提取、第三右眼激活层进行特征激活、第三右眼扩展卷积层进行模型通道数扩展、第三右眼扩展激活层进行特征激活、第四右眼卷积层进行卷积特征提取、第四右眼激活层、第四右眼扩展卷积层进行模型通道数扩展、第四右眼扩展激活层进行特征激活、进行特征激活,得到每帧驾驶员图像的右眼特征;
24、所述全局面部特征卷积神经网络,用于输入每幅驾驶员图像的面部区域图像,进行面部特征提取得到每幅驾驶员图像的面部特征;
25、所述全局面部特征卷积神经网络包括:
26、第一阶段全局面部卷积模块、第二阶段全局面部卷积模块、第三阶段全局面部卷积模块、第四阶段全局面部卷积模块、第五阶段全局面部卷积模块、第六阶段全局面部卷积模块、第七阶段全局面部卷积模块、第八阶段全局面部卷积模块、第九阶段全局面部卷积模块;
27、所述第一阶段全局面部卷积模块,包括:第一全局卷积层;
28、所述第二阶段全局面部卷积模块,包括:第二阶段第一全局移动翻转瓶颈卷积层、第二阶段第一全局通道注意力模块;
29、所述第三阶段全局面部卷积模块,包括:第三阶段第一全局移动翻转瓶颈卷积层、第三阶段第一全局通道注意力模块、第三阶段第二全局移动翻转瓶颈卷积、第三阶段第二全局通道注意力模块;
30、所述第四阶段全局面部卷积模块,包括:第四阶段第一全局移动翻转瓶颈卷积层、第四阶段第一全局通道注意力模块、第四阶段第一全局空间注意力模块、第四阶段第二全局移动翻转瓶颈卷积层、第四阶段第二全局通道注意力模块、第四阶段第二全局空间注意力模块;
31、所述第五阶段全局面部卷积模块,包括:第五阶段第一全局移动翻转瓶颈卷积层、第五阶段第一全局通道注意力模块、第五阶段第一全局空间注意力模块、第五阶段第二全局移动翻转瓶颈卷积层、第五阶段第二全局通道注意力模块、第五阶段第二全局空间注意力模块、第五阶段第三全局移动翻转瓶颈卷积层、第五阶段第三全局通道注意力模块、第五阶段第三全局空间注意力模块;
32、所述第六阶段全局面部卷积模块,包括:第六阶段第一全局移动翻转瓶颈卷积层、第六阶段第一全局通道注意力模块、第六阶段第一全局空间注意力模块、第六阶段第二全局移动翻转瓶颈卷积层、第六阶段第二全局通道注意力模块、第六阶段第二全局空间注意力模块、第六阶段第三全局移动翻转瓶颈卷积层、第六阶段第三全局通道注意力模块、第六阶段第三全局空间注意力模块;
33、所述第七阶段全局面部卷积模块,包括:第七阶段第一全局移动翻转瓶颈卷积层、第七阶段第一全局通道注意力模块、第七阶段第一全局空间注意力模块、第七阶段第二全局移动翻转瓶颈卷积层、第七阶段第二全局通道注意力模块、第七阶段第二全局空间注意力模块、第七阶段第三全局移动翻转瓶颈卷积层、第七阶段第三全局通道注意力模块、第七阶段第三全局空间注意力模块、第七阶段第四全局移动翻转瓶颈卷积层、第七阶段第四全局通道注意力模块、第七阶段第四全局空间注意力模块;
34、所述第八阶段全局面部卷积模块,包括:第八阶段第一全局移动翻转瓶颈卷积层、第八阶段第一全局通道注意力模块、第八阶段第一全局空间注意力模块;
35、所述第九阶段全局面部卷积模块,包括:第九全局卷积层、第九全局激活层;
36、所述的第二阶段第一全局移动翻转瓶颈卷积层、第三阶段第一全局移动翻转瓶颈卷积层、第三阶段第二全局移动翻转瓶颈卷积、第四阶段第一全局移动翻转瓶颈卷积层、第四阶段第二全局移动翻转瓶颈卷积层、第五阶段第一全局移动翻转瓶颈卷积层、第五阶段第二全局移动翻转瓶颈卷积层、第五阶段第三全局移动翻转瓶颈卷积层、第六阶段第一全局移动翻转瓶颈卷积层、第六阶段第二全局移动翻转瓶颈卷积层、第六阶段第三全局移动翻转瓶颈卷积层、第七阶段第一全局移动翻转瓶颈卷积层、第七阶段第一全局通道注意力模块、第七阶段第二全局移动翻转瓶颈卷积层、第七阶段第三全局移动翻转瓶颈卷积层、第七阶段第四全局移动翻转瓶颈卷积层、第八阶段第一全局移动翻转瓶颈卷积层,均包括:
37、1×1升维卷积层、深度可分离卷积层、1×1降维卷积层、dropout层;
38、所述的第二阶段第一全局通道注意力模块、第三阶段第一全局通道注意力模块、第三阶段第二全局通道注意力模块、第四阶段第一全局通道注意力模块、第四阶段第二全局通道注意力模块、第五阶段第一全局通道注意力模块、第五阶段第二全局通道注意力模块、第五阶段第三全局通道注意力模块、第六阶段第一全局通道注意力模块、第六阶段第二全局通道注意力模块、第六阶段第三全局通道注意力模块、第七阶段第一全局通道注意力模块、第七阶段第二全局通道注意力模块、第七阶段第三全局通道注意力模块、第七阶段第四全局通道注意力模块、第八阶段第一全局通道注意力模块,均包括:
39、最大池化层、平均池化层、1×1卷积层、silu激活层、1×1卷积层、加权层、sigmoid激活层;
40、所述的第四阶段第一全局空间注意力模块、第四阶段第二全局空间注意力模块、第五阶段第一全局空间注意力模块、第五阶段第二全局空间注意力模块、第五阶段第三全局空间注意力模块、第六阶段第一全局空间注意力模块、第六阶段第二全局空间注意力模块、第六阶段第三全局空间注意力模块、第七阶段第一全局空间注意力模块、第七阶段第二全局空间注意力模块、第七阶段第三全局空间注意力模块、第七阶段第四全局空间注意力模块、第八阶段第一全局空间注意力模块,均包括:
41、最大池化层、平均池化层、7×7卷积层、sigmoid激活层;
42、所述全局面部特征卷积神经网络各网络层是按照efficientnet网络模型内部网络层的方式进行级联;
43、所述第一视线回归全连接层,用于输入每帧驾驶员图像的左眼特征、每帧驾驶员图像的右眼特征、每帧驾驶员图像的面部特征、头部姿态向量,进行回归处理,得到每帧驾驶员图像的第一融合特征;
44、所述第二视线回归全连接层,用于输入每帧驾驶员图像的第一融合特征,进行回归处理,得到每帧驾驶员图像的估计视线方向;
45、将每帧驾驶员图像的面部特征依次通过注视区域1×1卷积层进行卷积特征提取、注视区域平均池化层进行池化处理、注视区域线性回归层进行线性回归、注视区域logsoftmax激活层进行特征激活,得到每帧驾驶员图像的每种注视区域类型的概率,在每帧驾驶员图像的所有注视区域类型的概率中选择概率的注视区域类型作为每幅驾驶员图像的估计注视区域类型;
46、作为优选,步骤2所述驾驶员视线估计网络损失函数,包括:驾驶员视线方向估计损失函数、驾驶员注视区域估计损失函数;
47、所述驾驶员视线方向估计损失函数用于约束所述每帧驾驶员图像的估计视线方向,定义如下:
48、使用均方误差mse作为驾驶员视线方向估计损失函数lg,可被定义为:
49、
50、其中,n表示驾驶员图像数量,i表示每帧驾驶员图像的索引,为第i帧驾驶员图像的估计视线方向,gi为第i帧驾驶员图像的视线方向;
51、所述驾驶员注视区域估计损失函数用于约束每帧驾驶员图像的估计注视区域,驾驶员注视区域估计损失函数lz包括交叉熵损失函数lce、中心损失函数lc;
52、所述交叉熵损失函数lce可以定义为:
53、
54、其中,i表示每帧驾驶员图像的索引,zi是第i帧驾驶员图像的注视区类型,是第i帧驾驶员图像的估计注视区域类型。交叉熵损失函数lce用于衡量每帧驾驶员图像的每种注视区域类型预测概率值与每帧驾驶员图像的注视区域真实值之间的差异。它可以有效地增加类间离散度,但在区分类内离散度方面存在局限性,导致类间距离相对较大;
55、所述中心损失函数lc可以减少类内的间距,可被定义为:
56、
57、其中,n表示驾驶员图像数量,fi是第i帧驾驶员图像的特征向量,是第i帧驾驶员图像注视区域的中心;
58、所述驾驶员注视区域估计的损失函数可被定义为:
59、
60、其中,表示中心损失函数的权重,用于调整类内紧凑性。越大,类内紧凑性越低,相反,越小,类内紧凑性越高。
61、本发明还提供了一种辅助安全驾驶的多任务驾驶员视线估计系统,包括:
62、驾驶员图像及姿态提取模块,用于从视频序列中获取多帧驾驶员图像,标记每帧驾驶员图像的视线方向、注视区域类型,将每帧驾驶员图像通过dlib cnn方法提取每帧驾驶员图像的多个人脸关键特征点、每帧驾驶员图像的面部区域图像,结合每帧驾驶员图像的多个人脸关键特征点进行眼部区域裁剪及驾驶员头部姿态提取,得到每帧驾驶员图像的左眼区域图像、每帧驾驶员图像的右眼区域图像、每帧驾驶员图像的头部姿态;
63、驾驶视线估计网络训练模块,用于构建驾驶视线估计网络,将每帧驾驶员图像的左眼区域图像、每帧驾驶员图像的右眼区域图像、每帧驾驶员图像的面部区域图像、每帧驾驶员图像的头部姿态作为输入至驾驶员视线估计网络进行视线估计,得到每帧驾驶员图像的估计视线方向、估计注视区域类型,结合每帧驾驶员图像的视线方向、注视区域类型构建驾驶员视线估计网络损失函数,通过sgd算法优化训练得到优化后驾驶视线估计网络;
64、实时驾驶员图像估计模块,用于获取实时驾驶员图像,输入至优化后驾驶视线估计网络进行视线估计,得到实时驾驶员图像的估计视线方向、估计注视区域类型。
65、本发明的有益效果为:
66、驾驶员视线及视区估计模型使用同一个网络结构能够同时估计驾驶员驾驶中的视线方向及其在驾驶舱内的注视区域,帮助实时监测驾驶员的视线方向及注视区域信息,判断驾驶视线盲区,辅助驾驶员安全驾驶;
67、使用普通相机作为图像采集设备,与其他头戴式视线跟踪设备相比,该模型不会在驾驶过程中对驾驶员造成干扰,具有测量方法更灵活、设备操作简单、价格低廉,方法普适性较高等优点;
68、与其他驾驶员视区估计方法相比,本发明所述模型采用轻量化的主干网络进行特征提取,并使用预训练-微调的策略对网络模型进行训练,在减少网络计算量及模型参数的同时,提高视区估计的精度;
69、所述全局面部特征提取网络——gcnn在网络模型的不同卷积阶段嵌入了通道和空间注意模块,使得网络在早期阶段捕获整体通用特征,并在后期阶段学习局部判别性特征,经验证,注意力模块的嵌入将注视区域估计提高了15%。
- 还没有人留言评论。精彩留言会获得点赞!