在线文字识别模型训练方法、在线文字识别方法及装置
本技术涉及深度学习,尤其涉及一种在线文字识别模型训练方法、在线文字识别方法及装置。
背景技术:
1、在线文字识别,又称为动态手写识别或实时手写识别,侧重于对书写过程中的笔迹动态信息进行捕捉和分析,以实现对文字的识别。与静态文字识别不同,它不仅关注文字的最终形态,还关注书写过程中的笔顺、速度、压力等动态特征。在线文字识别可以提供更自然、直观的人机交互方式,如智能笔记本、电子白板等,这些设备能够实时将用户的手写输入转换成电子文本,极大地提高了用户体验和工作效率。
2、当我们考虑通过上传不同书写者的书写数据到服务器来进行集中式训练一个机器学习模型时,必须认识到这样做潜在地涉及到隐私泄漏的风险。首先,书写数据往往包含了个人的书写习惯、风格甚至可能包括敏感信息,如个人签名、笔记内容等,这些都是个人隐私的一部分。一旦这些数据被上传到服务器,就存在着被未授权访问或滥用的可能性。在集中训练过程中,服务器需要收集和存储大量的书写样本,以便构建一个有效的书写识别模型。然而,如果服务器的安全措施不够完善,或者数据传输过程中没有得到充分加密,那么恶意攻击者就可能截取到这些数据,从而侵犯用户的个人隐私。
3、目前,一般通过联邦学习的方式对有可能涉及隐私泄漏的模型进行训练,以尽量避免隐私泄漏。然而,通过联邦学习对在线文字识别模型进行训练的过程中,由于在线文字识别的所处理的数据量较大,模型收敛需要消耗较多的时间成本和计算资源。因此,在保障用户的隐私安全的前提下,在线文字识别模型的训练效率和识别精度较低,从而影响了在线文字识别的精确度。
技术实现思路
1、本技术的目的旨在至少能解决上述的技术缺陷之一,特别是现有技术中在保障用户的隐私安全的前提下,在线文字识别模型的训练效率和识别精度较低的技术缺陷。
2、第一方面,本技术提供了一种在线文字识别模型训练方法,应用于联邦学习系统,所述联邦学习系统包括一个服务端和多个客户端;所述方法包括:
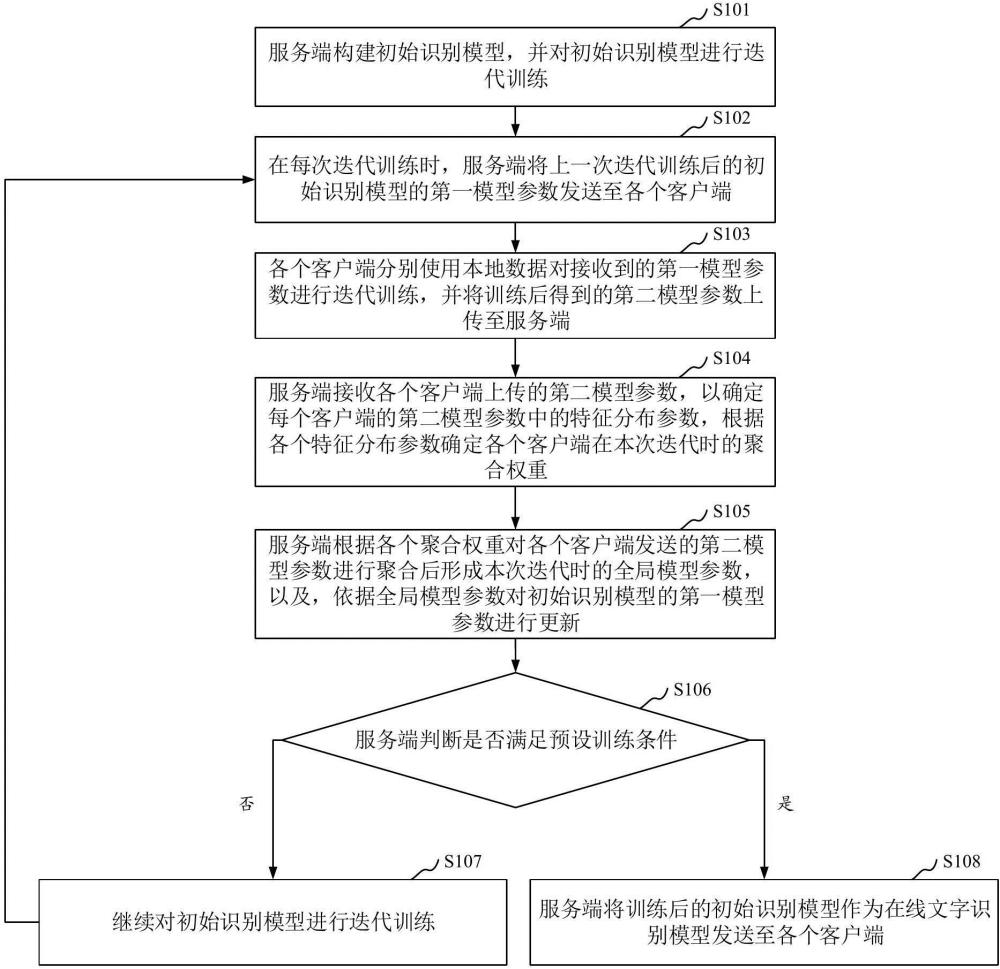
3、所述服务端构建初始识别模型,并对所述初始识别模型进行迭代训练,在每次迭代训练时,将上一次迭代训练后的初始识别模型的第一模型参数发送至各个客户端;
4、各个客户端分别使用本地数据对接收到的第一模型参数进行迭代训练,并将训练后得到的第二模型参数上传至所述服务端;
5、所述服务端接收各个客户端上传的第二模型参数,以确定每个客户端的第二模型参数中的特征分布参数,根据各个特征分布参数确定各个客户端在本次迭代时的聚合权重,并根据各个聚合权重对各个客户端发送的第二模型参数进行聚合后形成本次迭代时的全局模型参数,以及,依据所述全局模型参数对所述初始识别模型的第一模型参数进行更新后,继续对所述初始识别模型进行迭代训练,直到满足预设训练条件时为止,将训练后的初始识别模型作为在线文字识别模型发送至各个客户端;其中,所述特征分布参数用于衡量其对应的本地数据的数据质量。
6、在其中一个实施例中,所述根据各个特征分布参数确定各个客户端在本次迭代时的聚合权重的步骤,包括:
7、所述服务端对各个特征分布参数进行平均求和,以确定全局特征分布参数,并根据各个特征分布参数和所述全局特征分布参数,分别确定每个客户端对应的聚合权重;其中,所述特征分布参数为对应的第二模型参数中的各个层归一化层的可学习参数的均值。
8、在其中一个实施例中,所述服务端根据各个特征分布参数和所述全局特征分布参数,按照以下表达式分别确定每个客户端对应的聚合权重:
9、
10、式中,表示第个客户端对应的聚合权重,表示第个客户端对应的聚合权重向量,表示第个客户端对应的聚合权重向量中的第个元素,表示第个客户端对应的聚合权重向量的特征维度,其中,的表达式如下:
11、
12、式中,、均为第个客户端的特征分布参数,、均为全局特征分布参数。
13、在其中一个实施例中,所述根据各个聚合权重对各个客户端发送的第二模型参数进行聚合后形成本次迭代时的全局模型参数的步骤,包括:
14、所述服务端确定第一目标值,并根据所述第一目标值,确定每个客户端对应的目标比值;其中,所述第一目标值为各个客户端的聚合权重之和,所述目标比值为对应的客户端的聚合权重与所述第一目标值之间的比值;
15、所述服务端分别将每个客户端的目标比值与该客户端的第二模型参数之间的乘积确定为该客户端的第二目标值,并对每个客户端的第二目标值进行求和,以得到所述全局模型参数。
16、在其中一个实施例中,所述构建初始识别模型的步骤,包括:
17、所述服务端获取笔迹点数据集,以及确定预设的目标通用模型,根据所述笔迹点数据集对所述目标通用模型进行迭代训练,以将训练完成时得到的目标通用模型确定为初始识别模型;
18、其中,所述目标通用模型包括升维映射层、序列特征编码模块和预测层;所述升维映射层用于提取所述笔迹点数据集中的笔迹点升维特征;所述序列特征编码模块用于根据所述笔迹点升维特征确定笔迹点编码特征序列;所述预测层用于根据所述笔迹点编码特征序列确定文字识别概率向量,并更新所述目标通用模型的可学习参数。
19、在其中一个实施例中,各个客户端分别使用本地数据对接收到的第一模型参数进行迭代训练的步骤,包括:
20、各个客户端在每次迭代训练中分别从其对应的本地数据中进行采样得到笔迹点序列和字符识别标签,并分别根据各自采样到的笔迹点序列和字符识别标签确定识别损失函数;各个客户端分别对各自的识别损失函数进行反向传播,以对当前的第一模型参数进行更新,直至满足预设条件时,将最新的第一模型参数确定为第二模型参数。
21、第二方面,本技术提供了一种在线文字识别方法,应用于联邦学习系统中的任意一个客户端,所述联邦学习系统包括一个服务端和多个客户端;所述方法包括:
22、获取用户输入的待识别的笔迹点数据,以及获取服务端发送的在线文字识别模型;
23、将所述笔迹点数据输入至所述在线文字识别模型中,得到与所述笔迹点数据对应的文字数据,以完成在线文字识别。
24、第三方面,本技术提供了一种在线文字识别模型训练装置,应用于联邦学习系统,所述联邦学习系统包括一个服务端和多个客户端;所述装置包括:
25、迭代训练模块,用于所述服务端构建初始识别模型,并对所述初始识别模型进行迭代训练,在每次迭代训练时,将上一次迭代训练后的初始识别模型的第一模型参数发送至各个客户端;
26、本地训练模块,用于各个客户端分别使用本地数据对接收到的第一模型参数进行迭代训练,并将训练后得到的第二模型参数上传至所述服务端;
27、参数聚合模块,用于所述服务端接收各个客户端上传的第二模型参数,以确定每个客户端的第二模型参数中的特征分布参数,根据各个特征分布参数确定各个客户端在本次迭代时的聚合权重,并根据各个聚合权重对各个客户端发送的第二模型参数进行聚合后形成本次迭代时的全局模型参数,以及,依据所述全局模型参数对所述初始识别模型的第一模型参数进行更新后,继续对所述初始识别模型进行迭代训练,直到满足预设训练条件时为止,将训练后的初始识别模型作为在线文字识别模型发送至各个客户端;其中,所述特征分布参数用于衡量其对应的本地数据的数据质量。
28、第四方面,本技术提供了一种在线文字识别装置,应用于联邦学习系统中的任意一个客户端,所述联邦学习系统包括一个服务端和多个客户端;所述装置包括:
29、数据获取模块,用于获取用户输入的待识别的笔迹点数据,以及获取服务端发送的在线文字识别模型;
30、文字识别模块,用于将所述笔迹点数据输入至所述在线文字识别模型中,得到与所述笔迹点数据对应的文字数据,以完成在线文字识别。
31、第五方面,本技术提供了一种计算机设备,包括:一个或多个处理器,以及存储器;
32、所述存储器中存储有计算机可读指令,所述一个或多个处理器执行时所述计算机可读指令时,执行如上述任一项实施例所述方法的步骤。
33、从以上技术方案可以看出,本技术实施例具有以下优点:
34、本技术提供的在线文字识别模型训练方法、在线文字识别方法及装置,所述模型训练方法包括:服务端对初始识别模型进行选代训练,在每次迭代训练时,将上一次选代训练后的初始识别模型的第一模型参数发送至各个客户端;各个客户端分别使用本地数据对接收到的第一模型参数进行迭代训练,并将训练后得到的第二模型参数上传至服务端。这样不需要将各个客户端的本地数据上传给服务端进行训练,而是在各个客户端的本地进行训练,进而将训练后的第二模型参数上传到服务端即可,以尽量避免数据泄漏。接着,服务端接收各个客户端上传的第二模型参数,以确定每个客户端的第二模型参数中的特征分布参数,根据各个特征分布参数确定各个客户端在本次迭代时的聚合权重,并根据各个聚合权重对各个客户端发送的第二模型参数进行聚合后形成本次迭代时的全局模型参数,以对初始识别模型的第一模型参数进行更新。其中的特征分布参数用于衡量其对应的本地数据的数据质量。如此,通过特征分布参数可以量化各个客户端所拥有的数据的质量,进而以特征分布参数为依据确定聚合权重,使得训练的初始识别模型更关注质量高的数据,加速模型的收敛过程,同时也能提高初始识别模型的精度。进而在保障用户的隐私安全的前提下提高识别模型的训练效率和识别精度。
- 还没有人留言评论。精彩留言会获得点赞!