一种结合遥感影像和生境信息的农作物种植区提取方法
本发明涉及一种结合遥感影像和生境信息的农作物种植区提取方法,属于农作物识别。
背景技术:
1、获取大尺度农作物信息,能够监测田间农作物的种植区域和生长情况,对提高作物的产量和品质有重要作用。现有技术多依靠人工采样测量,这种传统的实地统计方法耗费时间与人力,存在效率低下、主观性强、特征单一等缺点,大范围的定期监测实现困难。实现一种快速监测的农作物监测技术,能够大范围、低成本地进行农作物种植区识别。可为农民提供科学、准确的农事活动指导与决策支持,在作物品种的选择与引进方面能提供有力的参考。通过实现农作物种植区的动态监测,农户能够更全面地了解种植状况,从而更好地应对不同季节和气候条件下的种植管理需求。这对于提高农作物产业的管理效益和决策水平具有积极的促进作用。
技术实现思路
1、本发明所要解决的技术问题是:提供一种结合遥感影像和生境信息的农作物种植区提取方法,将生态位模型与深度学习模型相结合,综合考虑光谱、地形、生长环境信息,提高了农作物种植区的提取精度。
2、本发明为解决上述技术问题采用以下技术方案:
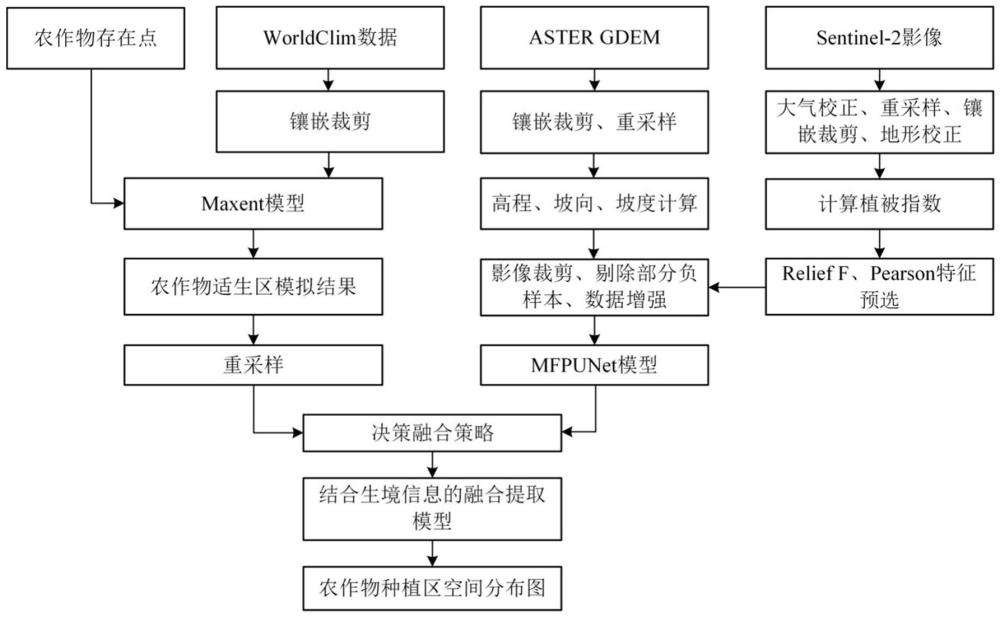
3、一种结合遥感影像和生境信息的农作物种植区提取方法,包括如下步骤:
4、步骤1,获取目标区域的sentinel-2多光谱影像数据、aster gdem数据和worldclim气候数据,将目标区域划分为训练区域和测试区域;
5、步骤2,对目标区域的sentinel-2多光谱影像数据进行预处理,得到预处理后的多光谱影像数据,在训练区域随机选取农作物、森林、裸地和草地4类样本点并打标签,计算各样本点的植被指数;
6、步骤3,根据relief-f特征筛选算法和pearson相关系数,从各样本点的所有植被指数中选择重要性最高的3个植被指数;
7、步骤4,剔除sentinel-2中与地物分类无关的波段,将剩余波段与重要性最高的3个植被指数一起作为光谱特征;
8、步骤5,基于aster gdem数据计算坡度和坡向,并重采样至10m,将重采样后的海拔、坡度和坡向作为地形特征;
9、步骤6,根据光谱特征和地形特征构建整个目标区域的数据集,并将训练区域的数据集划分为训练集和验证集,构建mfpunet模型,mfpunet模型包括光谱编码器、地形编码器和解码器,利用训练集和验证集对mfpunet模型进行训练和验证;利用训练好的mfpunet模型对测试区域进行预测;
10、步骤7,从所有农作物样本点中选取相互之间距离大于1.5km的农作物样本点作为农作物存在点,利用农作物存在点和worldclim气候数据训练maxent模型,采用十折交叉验证,选择auc值最大的一次运算结果模拟,预测测试区域农作物适生区概率分布并重采样至10m;
11、步骤8,利用融合目标函数对mfpunet模型和maxent模型的预测结果作决策融合处理,根据决策融合结果预测测试区域的农作物分布。
12、作为本发明的一种优选方案,步骤2所述对目标区域的sentinel-2多光谱影像数据进行预处理,包括:将sentinel-2的l1c级数据转换为l2a级数据,并对所有波段重采样至10m,利用地形校正模型teillet对重采样后的影像进行地形校正,将灰度值转换为光谱反射率。
13、作为本发明的一种优选方案,所述步骤3的具体过程如下:
14、3.1,采用relief f-pearson特征筛选算法,将每个植被指数经过t次迭代得到的权重的平均作为最终权重,即:
15、
16、其中,ω(fi)表示第i个植被指数的权重,k为最近邻样本的数量,∑h∈h∣ri-hi∣是样本点r与所选k个同类样本点在第i个植被指数上的最近邻距离总和,ri表示样本点r的第i个植被指数,hi表示与样本点r同一个类别的样本点h的第i个植被指数,h表示与样本点r同一个类别的样本点集合,∑m∈m∣ri-mi∣表示样本点r与k个不同类型样本点在第i个植被指数上的最近邻距离总和,mi表示与样本点r不同类别的样本点m的第i个植被指数,m表示与样本点r不同类别的样本点集合;
17、3.2,对于所有植被指数,计算两两之间的pearson相关系数,即:
18、
19、其中,rpearson表示pearson相关系数,xj和yj分别表示第j个样本点的植被指数x和y,x表示所有样本点植被指数x的均值,y表示所有样本点植被指数y的均值,x和y表示两个不同的植被指数;
20、3.3,将所有植被指数的最终权重按从大到小的顺序排序,从最终权重最大的开始选择3个植被指数,选出的3个植被指数满足两两之间的pearson相关系数小于0.6。
21、作为本发明的一种优选方案,步骤4所述剩余波段包括蓝波段、绿波段、红波段、三个植被红边波段、近红外波段以及两个短波红外波段。
22、作为本发明的一种优选方案,步骤6所述根据光谱特征和地形特征构建整个目标区域的数据集,并将训练区域的数据集划分为训练集和验证集,具体为:按照50%的重叠率,将整个目标区域的光谱特征、地形特征和标签裁剪为256×256大小的影像块,剔除训练区域的部分负样本,使正负样本的比例为1:1,使用几何变换进行数据增强,得到训练区域的数据集,将数据集按8:2的比例划分为训练集和验证集。
23、作为本发明的一种优选方案,步骤6所述mfpunet模型以unet架构作为基线,引入多头编码器和后融合策略,多头编码器分为两个部分:第一部分是多尺度金字塔结构的三层resnet50编码器,用于学习光谱特征;第二部分是三层resnet34编码器,用于学习地形特征;
24、光谱编码器对输入的光谱特征进行第一至第四次下采样,同时将输入的光谱特征裁剪为四个相同的子块,对每个子块进行第一至第四次下采样,同时将每个子块裁剪为四个相同的小子块,对每个小子块进行第一至第四次下采样;地形编码器对输入的地形特征进行第一至第四次下采样;
25、光谱特征第四次下采样得到的结果依次经空洞空间卷积池化金字塔和卷积层后,得到结果a1;将四个子块第四次下采样的结果合并,得到结果b11,将十六个小子块第四次下采样的结果合并,得到结果b12,b11和b12拼接后再经过卷积层,得到结果b1;地形特征第四次下采样得到的结果与a1和b1拼接后再上采样,得到结果d1;
26、将四个子块第三次下采样的结果合并,得到结果b2;将十六个小子块第三次下采样的结果合并,得到结果c2;光谱特征第三次下采样得到的结果与b2、c2、d1以及地形特征第三次下采样得到的结果拼接后再上采样,得到结果d2;
27、将四个子块第二次下采样的结果合并,得到结果b3;将十六个小子块第二次下采样的结果合并,得到结果c3;光谱特征第二次下采样得到的结果与b3、c3、d2以及地形特征第二次下采样得到的结果拼接后再上采样,得到结果d3;
28、将四个子块第一次下采样的结果合并,得到结果b4;将十六个小子块第一次下采样的结果合并,得到结果c4;光谱特征第一次下采样得到的结果与b4、c4、d3以及地形特征第一次下采样得到的结果拼接后再上采样,得到结果d4;对d4进行降维处理,得到模型的输出。
29、作为本发明的一种优选方案,步骤6所述mfpunet模型,在训练时采用adam优化器用于模型训练,设置模型的初始学习率为1×10-4,批次大小为4,总训练epoch数为80,定义学习率衰减因子为0.1,每25个epoch学习率下降;
30、选择加权类别交叉熵损失评价模型训练效果,即:
31、
32、式中,l表示加权类别交叉熵损失,n为类别数量,wn为类别n的权重,yn表示只有1和0元素的独热向量,pn表示包含类别n的预测概率的向量,βn表示类别n的出现频率。
33、作为本发明的一种优选方案,步骤8所述融合目标函数具体如下:
34、
35、其中,s是像素位置的集合,表示由模型mk预测的像素s属于类别ys的概率,wk是模型mk的权重,a(modelk)表示模型mk的目标类精度。
36、一种计算机设备,包括存储器、处理器,以及存储在所述存储器中并能够在所述处理器上运行的计算机程序,所述处理器执行所述计算机程序时实现所述的结合遥感影像和生境信息的农作物种植区提取方法的步骤。
37、一种计算机可读存储介质,所述计算机可读存储介质存储有计算机程序,所述计算机程序被处理器执行时实现所述的结合遥感影像和生境信息的农作物种植区提取方法的步骤。
38、本发明采用以上技术方案与现有技术相比,具有以下技术效果:
39、1、本发明结合生态位模型与深度学习模型,综合考虑了光谱、地形、生长环境信息,这些信息能够提供更全面、多角度的地物特征,帮助提高分类的准确性。本发明方法有望为农作物产业的管理与发展、土地规划提供参考,有助于决策者和农业从业者更有效地进行种植规划和资源分配。
40、2、本发明利用sentinel-2影像、dem和worldclim数据实现大尺度农作物分布及变化信息的快速获取,减少了人力物力的消耗,极大地节约了监测成本。
41、3、本发明构建的mfpunet的多头编码器有两个关键部分:第一部分是多尺度金字塔结构的编码器,该结构能够从不同尺度上捕捉图像的空间信息,从而有效地提取出光谱和空间特征。第二部分是利用预训练的三层resnet34作为地形特征的特征学习器。该架构设计旨在分别从不同数据源学习特征,解决从不同数据中捕获的信息之间的固有差异。
42、4、本发明利用融合目标函数协同深度学习模型和生态位模型的预测结果,生境数据的低分辨率通常不能真正描述作物的空间分布,本发明以一种有效的方式集成maxent模型与深度学习模型,获得了更完整和清晰的农作物提取结果。
- 还没有人留言评论。精彩留言会获得点赞!