一种基于连续动作强化学习的激光相干合成控制算法
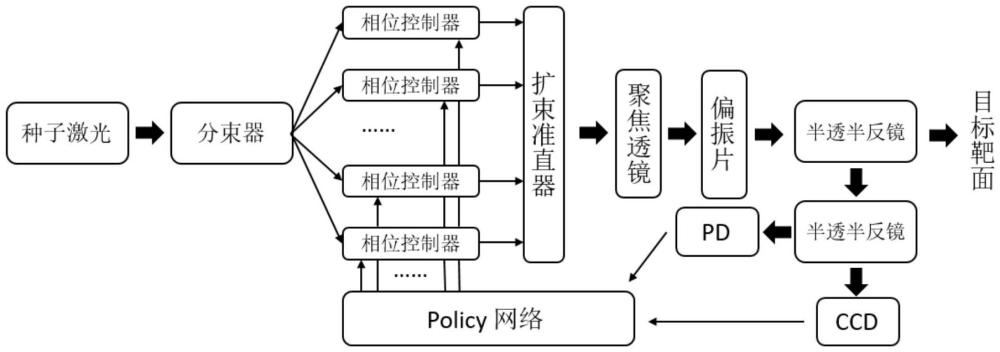
本发明涉及激光相干合成,具体涉及一种基于连续动作强化学习的激光相干合成控制算法。
背景技术:
1、激光相干合成技术通过调整多束激光的相位,使其达到同步,以实现高功率、高光束质量输出。激光的产生依赖于受激辐射的光放大,需要满足两个条件,即受激辐射的产生和放大,能够实现这一过程的设备称为激光器。激光器种类多样,其中光纤激光器应用较为广泛。随着激光在医疗、军事和工业加工等领域的广泛应用,人们的目标逐渐转向获得高功率、高光束质量和高亮度的激光输出。尽管当前的二极管泵浦激光放大器技术已经相当成熟,但由于光学元件能量阈值和激光器散热等物理限制,单台光纤激光器的输出功率受到限制。因此,要实现数十万瓦级的激光输出,需要通过激光相干合成技术,将多路激光合成为一束高功率激光。而相位控制技术则是实现多路激光相干合成的关键因素。
2、通常情况下,主动相位控制技术通过探测器提供的远场合成光斑信息,结合多种处理手段,对光束相位进行调节,以便将多个单元光束聚焦到特定目标表面。目前在光纤激光相干合成系统中,传统的主动相位控制方法包括外差法、抖动法和随机并行梯度下降算法(spgd),这些方法都能有效地校正各路光束的相位。然而,这些传统方法也存在一些难以克服的缺点:硬件系统要求高,且随着子波束数量的增加,控制带宽会显著减小。此外,尽管基于深度学习的相位控制方法在理想情况下可以通过单步迭代快速补偿光束间的相位差,但也存在明显的不足:训练一个良好的相位校正网络需要预先制作大量的标签。虽然在仿真系统中生成标签相对容易,但研究的最终目的是在实际系统中应用,这时在真实实验环境中收集大量标签数据会消耗大量时间和资源;另外,训练好的神经网络不会根据系统所处的环境进行参数调整,因此在面对不同噪声扰动和大气湍流等陌生环境时,无法达到预期的相干合成强度和效率。还有一部分基于强化学习的方法,虽然可以单步校正相位,但随着子波束数量的增加,网络的训练时间会急剧增加,难以在实际系统中应用。
技术实现思路
1、本发明的目的在于克服现有技术的不足,提供一种基于强化学习的激光相干合成的相位控制方法,该方法可以实时地修正相干合成系统中的相位,可以解决传统算法中对硬件刷新速度要求高以及离散动作强化学习系统中相位修正速度慢的问题,该方法中的神经网络可以实时修正系统中的相位的同时大大减少对硬件刷新速度的要求。
2、本发明解决上述技术问题的技术方案是:
3、一种基于连续动作强化学习的激光相干合成控制算法,包括以下步骤:
4、(s1)、将激光器的输出经过分束器分出m束后,分别送入m个相位调制器中对相位进行调制;
5、(s2)、对m束光进行相位调控后,光束被准直器扩束准直,然后输出至聚焦透镜进行m束光的聚焦;
6、(s3)、聚焦后的光束先通过偏振片,再通过显微物镜,最终输出至半透半反棱镜。一部分光透射至光电探测器ccd上,生成m束激光相干合成后的衍射图像a,另一部分光反射至光电探测器pd上以获取光强值;
7、(s4)、通过给相位控制器输入一组预先设计的固定相位扰动,再经过光学系统后得到一张添加了固定相位扰动的衍射图像b,将控制器复原至未添加扰动的状态。将衍射图像a和衍射图像b在通道维度上进行堆叠,然后送入已经训练好的policy网络,policy网络输出相位修正动作,将该修正动作送入控制器,矫正m束光的相位,实现高功率的激光相干合成输出;
8、优选的,在步骤(s4)中,固定相位扰动经过挑选,使得在保证可以打破相位简并的同时使得pib下降最小:具体实现是通过使得相邻光束的相位扰动值不相同,并且沿中心对称轴对应的光束相位扰动值相同。
9、优选的,在步骤(s4)中,固定的相位扰动直接由控制器硬件施加:具体实现是通过在控制器中写入对应程序,在送入相位修正动作后控制器触发相机和pd采集衍射图像和光强值,然后控制器自动添加固定相位扰动并触发相机和复原,最后控制器将堆叠后的衍射图像以及光强值送入网络并等待下一个相位修正动作,重复该过程。
10、优选的,在步骤(s4)中,policy网络可以在fpga上实现,以减少时延和推理耗时,增加系统的控制频率:具体实现是在fpga上实现policy网络对应的网络结构,在policy网络训练完成后,将policy网络权重直接下发到fpga中,然后在运行过程中将控制器的输出直接输入到fpga中,fpga进行运算后直接将计算出的相位修正动作输出到控制器。
11、优选的,在步骤(s4)中,训练好的policy网络的获取包括以下步骤:
12、(s4-1)、搭建一个神经网络policy网络,一个神经网络q值网络。policy网络的输入为在通道维度上堆叠的两张衍射图像,输出为一组相位修正动作的分布;q值网络的输入为在通道维度上堆叠的两张衍射图像以及对应的相位修正动作,输出为当前状态以及修正动作的优势值。
13、(s4-2)、m束光经过光学系统后得到了一张衍射图像,然后在控制器上实施一个固定相位扰动,经过光学系统后得到另一张衍射图像,复原控制器。将两张衍射图像在通道维度上进行堆叠,并将其输入到policy网络中,policy网络输出动作的概率分布,算法从该概率分布中采样到具体的相位修正动作,将该校正动作送入控制器上对m束光的相位进行校正,通过光学系统得到对应的衍射图样,并从光电探测器pd中获取光强值以进行奖励值的计算,然后将输入的堆叠衍射图、相位校正后的堆叠衍射图、相位校正动作以及计算所得的奖励值加入回放缓冲区中。
14、(s4-3)、在每次推理后,算法从回放缓冲区中随机采样n个校正前的堆叠衍射图像、相位校正后的堆叠衍射图像、相位校正动作以及奖励值。将相位校正前的堆叠衍射图像与相位校正动作送入q值网络,计算出当前的优势值,同时将相位修正后的堆叠衍射图像送入policy网络,计算出下一步的相位修正动作,将修正后的堆叠图像与修正动作送入q值网络,计算出下一步的优势值,将这两个值结合,与奖励值一起计算出q值网络的损失值,并使用反向传播算法优化q值网络;将堆叠衍射图像送入policy网络,生成修正动作后将其与堆叠衍射图像送入q值网络,对q值网络的输出进行梯度上升以优化policy网络。
15、优选的,在步骤(s4-1)中,policy网络是由两层全连接层以及激活函数组建而成的网络。首先将输入的图片压成一维的向量,然后依次经过两层全连接层以及对应的激活函数层:第一次经过激活函数为relu的激活函数层,第二次分别经过激活函数为tanh的激活函数层以及经过relu的激活函数层。
16、优选的,在步骤(s4-1)中policy网络输出的动作分布为分布的均值和方差参数,然后在分布上进行重参数化采样:具体实现是policy网络输出分布的均值和方差,然后从一个单位高斯分布进行采样,将采样值乘以标准差后加上均值,就等价于从指定均值和方差的高斯分布中进行采样,同时输出和损失函数仍然可导。
17、优选的,在步骤(s4-2)中,所述的奖励值的计算表达式如下:
18、rt=α·pibt+β·(pibt-pibt-1)+η·∈(pibt-threshold)
19、其中,α、β和η为可调参数,pibt为当前时刻的归一化桶中功率,pibt-1为上一时刻的归一化桶中功率值,∈为阶跃函数,threshold为算法达到成功锁定时pib的阈值。
20、优选的,在步骤(s4-2)中,所述的回放缓冲区具体细节如下:回放缓冲区为一个有固定大小上限,可随机访问的队列,这个队列中的每一个元素都分别包括输入的堆叠衍射图、相位校正后的堆叠衍射图、相位校正动作以及计算所得的奖励。在队列填满后,最先放入的元素会被自动丢弃。
21、优选的,在步骤(s4-3)中,所述的从回放缓冲区中随机采样的具体细节如下:算法首先生成n个范围在0至回放缓冲区元素数量上限的随机整数作为被采样元素索引,然后随机访问缓冲区队列,使用n个生成的随机索引收集n个元素以供后续训练使用。
22、优选的,在步骤(s4-3)中,所述的q值网络的损失计算具体细节如下:
23、
24、其中ai+1~πθ(·|si+1),γ、α为可调节参数,qω-为两个q网络之中q值较小的网络,计算损失函数l后,使用梯度下降法更新q网络的参数。
25、优选的,在步骤(s4-3)中,所述的policy网络的损失计算具体细节如下:
26、
27、其中,为用重参数化技巧采样出的动作,为参数为θ的policy网络,参数θ的更新通过对损失函数lπ(θ)进行梯度下降来完成。
28、本发明与现有技术相比具有以下的有益效果:
29、1、本发明的网络较为适合在硬件上实现,结构较为简单:整个网络仅使用了两个全连接层,激活函数也仅为基本的relu函数,硬件实现简单;整个网络的参数量很少,即使在较为廉价的硬件上,也可以最大程度的将网络并行化,提高整个系统的控制速度。
30、2、本发明的一种基于强化学习的激光相干合成控制方法相比于现有的深度学习方法在适应性与部署的简便性上更有优势,当本发明部署到实际系统中时,该专利中陈述的算法可以自动适应实际系统的各种参数,不需要人工进行干预。同时算法可以动态地适应环境中的放大器噪声、机械振动、湍流等干扰因素,自动地调整policy网络的参数,使控制系统在不同配置、不同环境下都能接近最优的控制效率,避免了传统深度学习方法需要手动收集大量不准确的标签,在环境发生变化时网络会失效,需要重新手动收集标签以及重新训练的过程。
31、3、本发明相较于其他强化学习算法,最大的优势是相位修正速度快:训练完成的policy网络理论上可以单步将任意相位状态修正到理想状态,在实际有噪声的真实系统中,训练完成的policy网络也可以平均在两步内完成相位修正,且由于policy网络输出的相位修正动作是连续的,避免了离散动作强化学习中由于动作幅度固定导致修正过程的缓慢以及在pib较高时pib值出现震荡的情况,使得算法在连续控制时效果明显优于离散动作强化学习算法。
- 还没有人留言评论。精彩留言会获得点赞!