一种基于提示式对比学习的骨架动作识别方法及存储介质
本发明涉及骨架动作识别,尤其是涉及一种基于提示式对比学习的骨架动作识别方法及存储介质。
背景技术:
1、基于骨架的动作识别任务旨在利用三维骨架表示预测人类动作的类别。由于其轻量化设计和隐私保护特性,基于骨架的动作识别在人机交互、视频内容分析和智能视频监控领域引起了广泛关注。通常,大多数基于骨架的动作识别方法采用图卷积网络并训练离散化标签。然而,这些方法受限于单一模态的骨架数据。与此同时,随着对比学习跨模态学习范式,如对比语言-图像预训练(contrastive language-image pre-training,clip)的兴起,此类方法允许利用多个模态(包括视觉和文本数据)增强人类动作的表示能力。通过利用不同模态中丰富的信息,跨模态对比学习有潜力提升基于骨架的动作识别系统的性能和鲁棒性。
2、对比文件cn118196888a公开了一种基于跨模态知识对齐的细粒度动作识别方法,该方法提出了一个通用的跨模态知识对齐框架,通过从预先训练的vlm和基于姿势的识别模型中传输知识,以提高细粒度动作识别性能。但是两个模态并不能完全对齐。尽管大型预训练视觉-语言模型取得了显著成功,但基于骨架的动作识别仍面临两大挑战。首先,像clip这样的对比学习方法成功的关键在于通过大规模预训练利用丰富的文本和图像样本,如图3(a)所示。然而,在基于骨架的动作识别中,骨架数据与文本描述之间存在显著的模态差距,如图3(b)所示。在这一任务中利用跨模态对比学习具有挑战性,因为这些模态是在特定领域内进行预训练,然后在有限数量的骨架-文本对上进行联合训练。同时,在基于骨架的动作识别中,如何通过语言提示引导模型解释骨架结构中的动作也是一个具有挑战性的问题。
技术实现思路
1、本发明的目的就是为了提供一种提高特征的对齐度和表征能力以提高识别精度的基于提示式对比学习的骨架动作识别方法及存储介质。
2、本发明的目的可以通过以下技术方案来实现:
3、一种基于提示式对比学习的骨架动作识别方法,包括以下步骤:
4、获取待识别的视频帧,输入预先训练好的骨架动作识别模型中进行识别,输出动作识别结果,其中所述骨架动作识别模型包括骨架编码器、文本编码器、感知模块和跨模态注意力块;
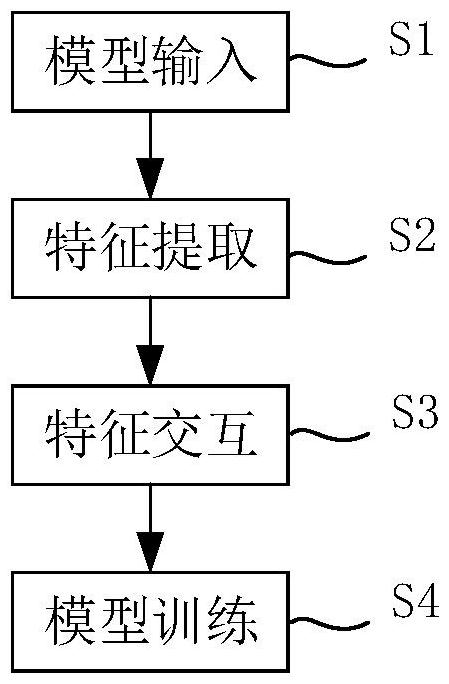
5、训练所述骨架动作识别模型的步骤包括:
6、模型输入:获取视频帧并提取视频帧中的关节坐标,生成骨架数据;
7、特征提取:采用所述骨架编码器对所述骨架数据进行编码,提取骨架特征,并构建包含可学习向量的文本提示,采用所述文本编码器对所述文本提示进行编码,提取文本特征;
8、特征交互:基于所述骨架特征和文本特征,采用所述感知模块和跨模态注意力块进行特征交互,生成融合特征;
9、训练损失:基于所述融合特征、骨架特征以及文本特征构建交叉熵损失函数、骨架-文本对比损失函数和双向三元组排序损失函数,对骨架动作识别模型进行训练,优化参数直至训练结束。
10、进一步地,所述生成骨架数据的步骤包括:
11、采用运动捕捉设备或姿态估计算法从所述视频帧中提取关节坐标,生成关节节点作为顶点、骨骼作为边的图g=(j,e),将图g作为骨架数据,其中j={j1,j2,…,jn}为n个关节节点的顶点集合,e是骨骼的边集合。
12、进一步地,所述骨架编码器为可训练的图卷积网络,所述提取骨架特征的过程表示为:
13、se=encs(g)
14、其中,se为骨架特征,encs(·)为骨架编码,g为图形式表示的骨架数据。
15、进一步地,所述文本编码器为冻结权重的预训练clip文本编码器。
16、进一步地,所述提取文本特征的过程表示为:
17、tf=enct(t)
18、t={v1;v2;…;vi;…;vm;[标签]}
19、式中,tf为文本特征,enct(·)为文本编码器,t为可学习向量的文本提示,vi(i∈1,…,m)为与词嵌入具有相同维度的可学习向量,m为可学习向量的数量,[标签]为可替代的类别标签。
20、进一步地,所述特征交互步骤包括:
21、对所述骨架特征se和文本特征tf进行归一化;
22、采用所述感知器模块在查询向量q和归一化后的骨架特征se之间进行:
23、s′f=perceiver(se,q)
24、式中,s′f为未池化的骨架特征,perceiver(·)为感知器模块;
25、沿时间维度对s′f进行池化,获得池化后的骨架特征sf;
26、将所述池化后的骨架特征sf={s1;…;sb}和归一化后的文本特征tf={t1;…;tb}进行特征交互,得到混合特征c,其中b是训练批量大小;
27、采用所述跨模态注意力模块捕获混合特征c中的交互,生成融合特征oc,所述融合特征oc表示为:
28、oc=multi-attn(qc,kc,vc)
29、
30、式中,multi-attn(·)为多头注意力机制,qc为查询,kc为键,vc为值,xc为查询qc,键kc或值vc,为权重矩阵。
31、进一步地,所述双向三元组排序损失函数的表达式为:
32、
33、
34、式中,为双向三元组排序损失,m是三元组损失的边距参数,d(s,t)为(sf,tf)和(sc,tc)两个模态之间的距离,s和t为训练批次中的正样本,sf为池化后的骨架特征,tf为文本特征,sc,tc为融合特征oc分成的两个尺寸相同的特征,为s和之间的距离,(sf,tf)∈(sf,tf)和(sc,tc)∈(sc,tc)代表骨架-文本特征对,α是平衡在骨架-语言交互过程前后获取的特征贡献的超参数,和是训练批次中的困难负样本,argmax(·)是一个最大值函数,x和y是训练批次内的骨架和文本特征,d(x,t)为x和t之间的距离,d(s,y)为s和y之间的距离。
35、进一步地,所述交叉熵损失函数的表达式为:
36、
37、式中,为交叉熵损失,yi为动作标签,为第i个骨架特征,p(·)代表预测的概率分布。
38、进一步地,所述骨架-文本对比损失函数的表达式为:
39、
40、
41、
42、式中,为骨架-文本对比损失,为期望运算符,kl为散度损失,gs2t(se)和gt2s(tf)表示骨架到文本和文本到骨架的真实相似度,ps2t(se)和pt2s(tf)为骨架到文本和文本到骨架的相似度,sim(·,·)为余弦相似度函数,b是训练批量大小,exp(·)代表指数函数,τ是可学习的温度参数,为第i个文本特征,为第i个骨架特征,tf为文本特征,se为骨架特征。
43、本发明还提供一种算机可读存储介质,包括供电子设备的一个或多个处理器执行的一个或多个程序,所述一个或多个程序包括用于执行如上述所述基于提示式对比学习的骨架动作识别方法的指令。
44、与现有技术相比,本发明具有以下有益效果:
45、(1)跨模态特征融合:传统的基于骨架的动作识别方法主要依赖于单一模态的骨架数据,而本发明引入了提示式对比学习框架,允许骨架数据与文本描述进行深度交互。通过骨架特征和文本特征的交互,有效减少了模态差距,提高了特征的对齐度和表征能力,从而提高了识别结果的精度。
46、(2)自适应提示生成:本发明采用了提示式对比学习,构建包含可学习向量的文本提示,该文本提示能够自适应地生成更适合动作识别任务的提示语。与传统的基于大型语言模型的提示生成相比,自适应生成文本提示提供了更优化和精准的提示,有助于模型在学习过程中更有效地引导动作解释。
47、(3)通用性强:本发明在多个权威数据集(包括ntu rgb+d、ntu rgb+d120)上达到了业界领先的性能水平,与传统的基于图卷积网络的方法相比,本方法能够更全面地捕捉动作的多模态特征,从而显著提升了动作识别的准确性和鲁棒性。
- 还没有人留言评论。精彩留言会获得点赞!