数据采集处理方法、电子设备、存储介质及程序产品与流程
本技术涉及数据处理,尤其涉及一种数据采集处理方法、电子设备、存储介质及程序产品。
背景技术:
1、数据采集是大数据处理中至关重要的关键环节,只有通过对各种数据进行全面、准确、高效的采集,才能提供可信的数据支持。故而提高数据同步效率是数据采集过程中一直追求的目标。
2、其中,影响数据采集效率也是有多个因素的,例如采集的数据量、采集任务并发数、服务器资源、网络资源,且多个因素之间相互约束影响,如何综合考量这多个因素以提高数据采集效率成为亟需解决的问题。
技术实现思路
1、本技术实施例提供数据采集处理方法、电子设备、存储介质及程序产品,综合考量多种影响因素下,提高数据采集效率。
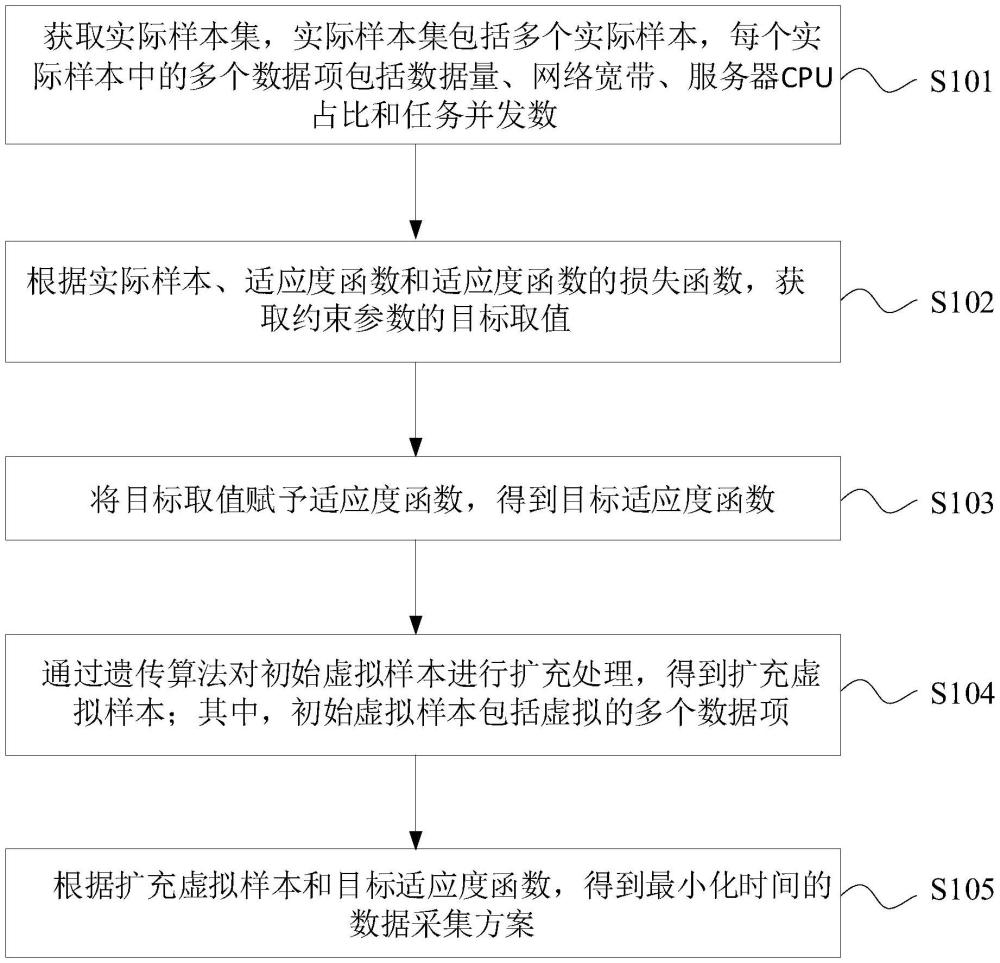
2、第一方面,本技术实施例提供一种数据采集处理方法,包括:获取实际样本集,所述实际样本集包括多个实际样本,每个所述实际样本中的多个数据项包括数据量、网络宽带、服务器cpu占比和任务并发数;
3、根据所述实际样本、适应度函数和所述适应度函数的损失函数,获取约束参数的目标取值,其中,在所述适应度函数中、每个数据项对应有各自的约束参数,所述适应度函数用于将每个所述实际样本作为输入变量,并输出数据采集的预测时长;所述损失函数是根据所述多个实际样本各自对应的预测时长和数据采集的实际时长确定的;
4、将所述目标取值赋予所述适应度函数,得到目标适应度函数;
5、通过遗传算法对初始虚拟样本进行扩充处理,得到扩充虚拟样本;其中,所述初始虚拟样本包括虚拟的所述多个数据项;
6、根据所述扩充虚拟样本和所述目标适应度函数,得到最小化时间的数据采集方案。
7、在一种可能的实施方式中,所述数据量与所述预测时长正相关,所述任务并发数、所述网络宽带与所述预测时长负相关,所述服务器cpu占比与预测时长呈自然指数关系。
8、在一种可能的实施方式中,所述适应度函数通过如下所述方式实现:
9、
10、其中,f为预测时长,d表示数据量、c表示任务并发数、n表示网络带宽、s表示服务器cpu占比、smax表示服务器cpu占比的最大阈值,所述w1、w2、w3、β为约束参数。
11、在一种可能的实施方式中,所述根据所述实际样本、适应度函数和所述适应度函数的损失函数,获取约束参数的目标取值,包括:
12、初始化所述适应度函数的约束参数,计算每个实际样本的数据采集的预测时长;
13、根据所述多个实际样本各自对应的预测时长和数据采集的实际时长确定损失函数的损失值,其中,所述损失函数为均方误差函数;
14、根据损失函数关于每个约束参数的偏导数,获取梯度方向,其中,所述梯度方向用于指示约束参数的增减方向;
15、根据梯度方向和学习率更新所述约束参数,并基于所述更新后的约束参数,获取新的损失函数的损失值,直至损失函数的损失值最小,停止更新所述约束参数,得到约束参数的目标取值。
16、在一种可能的实施方式中,所述通过遗传算法对初始虚拟样本进行扩充处理,得到扩充虚拟样本,包括:
17、根据所述初始虚拟样本和所述目标适应度函数获取适应度值,所述适应度值与所述适应度函数的输出呈反比;
18、基于所述初始虚拟样本和所述适应度值,通过遗传算法生成多个扩充虚拟样本。
19、在一种可能的实施方式中,所述根据所述初始虚拟样本和所述目标适应度函数获取适应度值,包括:
20、解码所述初始虚拟样本的基因组以得到数据项的值,其中,所述基因组为所述初始虚拟样本中各数据项的二进制编码;
21、根据数据项的值和所述目标适应度函数获取适应度值。
22、在一种可能的实施方式中,所述基于所述初始虚拟样本和所述适应度值,通过遗传算法生成多个扩充虚拟样本,包括:
23、根据虚拟样本的概率构建轮盘赌,通过重复次的选择操作获得多个父代样本,其中,所述概率为目标虚拟样本与所有虚拟样本的适应度比例,所述虚拟样本中包括初始虚拟样本;
24、根据父代样本的基因编码依序进行交叉操作和变异操作,以生成新的虚拟样本,并直至虚拟样本的适应度值趋于收敛,得到扩充虚拟样本,其中,所述交叉操作用于对同一数据项对应的不同二进制编码进行交叉处理,所述变异操作用于随机选择多个二进制数进行翻转处理。
25、第二方面,本技术实施例提供一种数据采集处理装置,包括:包括:
26、样本集合模块,用于获取实际样本集,所述实际样本集包括多个实际样本,每个所述实际样本中的多个数据项包括数据量、网络宽带、服务器cpu占比和任务并发数;
27、系数确定模块,用于根据所述实际样本、适应度函数和所述适应度函数的损失函数,获取约束参数的目标取值,其中,在所述适应度函数中、每个数据项对应有各自的约束参数,所述适应度函数用于将每个所述实际样本作为输入变量,并输出数据采集的预测时长;所述损失函数是根据所述多个实际样本各自对应的预测时长和数据采集的实际时长确定的;
28、函数生成模块,用于将所述目标取值赋予所述适应度函数,得到目标适应度函数;
29、数据扩充模块,用于通过遗传算法对初始虚拟样本进行扩充处理,得到扩充虚拟样本;其中,所述初始虚拟样本包括虚拟的所述多个数据项;
30、方案确定模块,用于根据所述扩充虚拟样本和所述目标适应度函数,得到最小化时间的数据采集方案。
31、第三方面,本技术实施例提供一种数据采集处理设备,包括:存储器,处理器;
32、所述存储器存储计算机执行指令;
33、所述处理器执行所述存储器存储的计算机执行指令,使得所述处理器执行如上第一方面和/或第一方面各种可能的实施方式。
34、第四方面,本技术实施例提供一种计算机可读存储介质,所述计算机可读存储介质中存储有计算机执行指令,所述计算机执行指令被处理器执行时用于实现如上第一方面和/或第一方面各种可能的实施方式。
35、第五方面,本技术实施例提供一种计算机程序产品,包括计算机程序,该计算机程序被处理器执行时实现如上第一方面和/或第一方面各种可能的实施方式。
36、本技术实施例提供的数据采集处理方法、电子设备、存储介质及程序产品,通过建立以多个数据项为输入变量、以数据采集的预测时长为输出的适应度函数,根据实际样本集和适应度函数的损失函数确定约束参数的目标取值,通过采集的实际样本中多个数据项和对应采集时长的关系,可较全面和准确的体现约束参数的取值,并且通过损失函数可以评估实际样本集在不同约束参数时预测时长和实际的采集时长之间的差异,从而根据约束参数的变化情况确定最优的约束参数,以使得将约束参数赋值于适应度函数生成目标适应度函数时的模型准确性和鲁棒性;由于目标适应度函数中仅包含多个数据项的输入变量,通过遗传算法对初始虚拟样本进行数据扩充得到扩充虚拟样本,将扩充虚拟样本分别代入目标适应度函数以获得多个关于采集时长的采集方案,并从中可得到最小化时间的数据采集方案,通过遗传算法进行初始虚拟样本的扩充处理,使得扩充后的扩充虚拟样本具有更高的数据多样性,从而使得数据采集方案更加全面,进而使得最终得到的最小化时间的数据采集方案在数据采集过程中具有更高的采集效率。
- 还没有人留言评论。精彩留言会获得点赞!