基于AI大模型的智能化对话场景分析方法与流程
本发明涉及人工智能,尤其涉及一种基于ai大模型的智能化对话场景分析方法。
背景技术:
1、随着人工智能和互联网信息技术的发展,智能化对话系统已经广泛应用于智能客服、智能音箱、智能车载、智能物联网、智能工业服务等众多场景。
2、中国专利申请公开号为cn116662511a的专利文献公开了一种采用ai模型识别的智能化对话场景分析方法及ai对话系统,通过获取目标用户在当前智能化对话场景产生的服务交互对话文本,并采用ai模型识别策略对服务交互对话文本进行兴趣挖掘,生成至少一个兴趣对话分句聚类簇,将兴趣对话分句数量大于设定数量的兴趣对话分句聚类簇所对应的兴趣标签确定为目标兴趣标签,基于目标兴趣标签向目标用户所在的智能化对话场景页面加载对应的对话反馈页面内容,从而在智能化对话场景中结合了不同兴趣标签的兴趣对话分句数量对目标用户进行兴趣挖掘。
3、现有技术中虽然通过ai模型识别策略可以对用户的兴趣进行挖掘,但对于用户口音的不同,现有技术往往无法准确地进行语音转化,导致对话信息的丢失或误解,从而无法给出精准的回答。
技术实现思路
1、为此,本发明提供一种基于ai大模型的智能化对话场景分析方法,通过深入分析用户的语音口音和文本信息,结合对话场景的特征可以解决ai大模型的智能化对话结果不准确的问题。
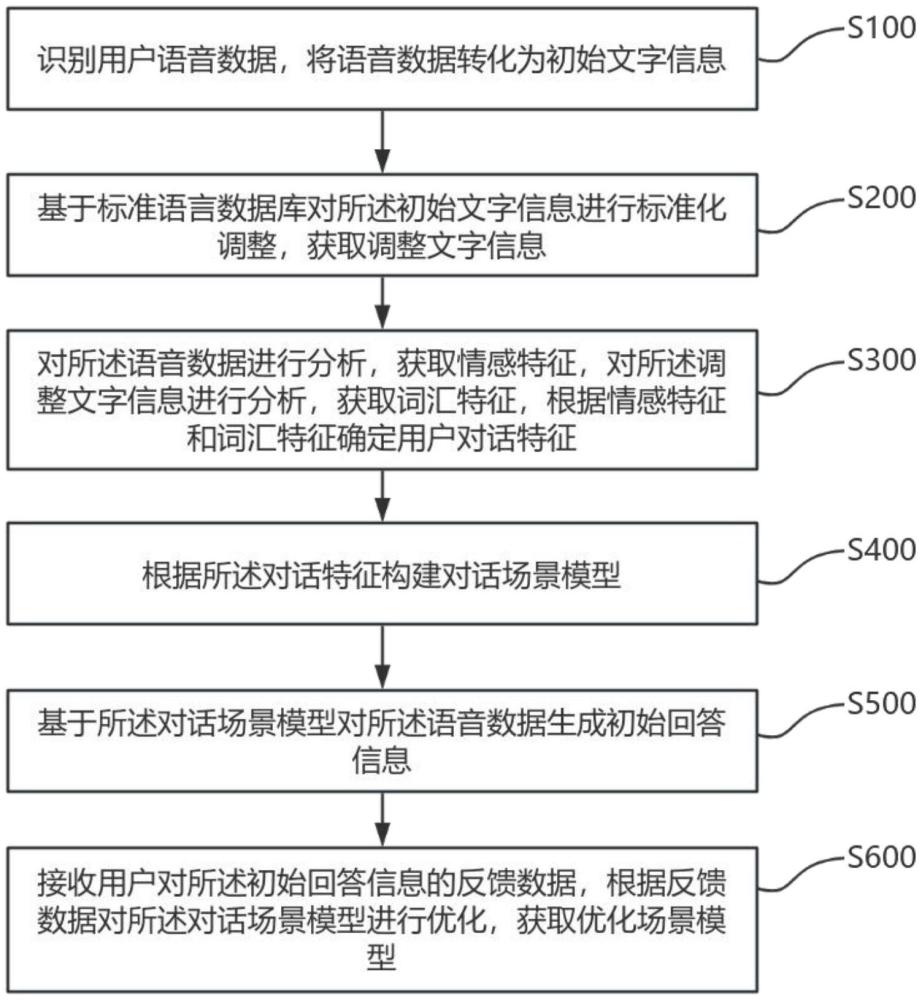
2、为实现上述目的,本发明提供一种基于ai大模型的智能化对话场景分析方法,该方法包括:识别用户语音数据,将语音数据转化为初始文字信息;
3、基于标准语言数据库对所述初始文字信息进行标准化调整,获取调整文字信息;
4、对所述语音数据进行分析,获取情感特征,对所述调整文字信息进行分析,获取词汇特征,根据情感特征和词汇特征确定用户对话特征;
5、根据所述对话特征构建对话场景模型;
6、基于所述对话场景模型对所述语音数据生成初始回答信息;
7、接收用户对所述初始回答信息的反馈数据,根据反馈数据对所述对话场景模型进行优化,获取优化场景模型。
8、进一步地,所述将语音数据转化为初始文字信息的步骤包括:
9、识别所述语音数据中的背景噪声和语音口音;
10、对所述背景噪声进行过滤处理;
11、根据语音转化模型对处理后的所述语音数据进行转化;
12、对所述语音口音进行识别,根据识别结果调整所述语音转化模型中的初始转化参数,获取调整转化参数;
13、根据所述调整转化参数对所述语音数据进行转化,获取初始文字信息。
14、进一步地,所述根据识别结果调整所述语音转化模型中的初始转化参数的步骤包括:
15、基于口音识别模型分析所述语音数据中的所述语音口音的口音类型;
16、基于所述口音类型对所述语音数据的口音程度进行分析,获取实际口音程度;
17、根据所述实际口音程度判断其对语音转化标准的影响程度;
18、基于所述影响程度调整所述初始转化参数,获取调整转化参数。
19、进一步地,所述根据所述实际口音程度判断其对语音转化标准的影响程度的步骤包括:
20、将所述语音数据与标准语音数据进行相似度比较,根据相似度比较结果确定语音数据与标准语音数据的语音偏差,将所述语音偏差作为所述实际口音程度;
21、将所述语音偏差与预设偏差进行比较,根据比较结果确定所述影响程度。
22、进一步地,所述基于标准语言数据库对所述初始文字信息进行标准化调整的步骤包括:
23、对所述初始文字信息进行预处理,包括去除多余的空格和标点符号标准化;
24、通过所述标准语言数据库中标准词汇对所述初始文字信息进行逐一比对,根据比对结果将初始文字信息中词语转换为标准词语;
25、通过所述标准语言数据库中标准语法规则对所述初始文字信息中语法进行识别,根据识别结果确定错误语法并修正。
26、进一步地,所述对所述语音数据进行分析的步骤包括:
27、基于所述语音数据提取音色特征和语速特征;
28、基于所述音色特征和所述语速特征构建语音特征向量;
29、基于所述语音特征向量和语音情感分类模型确定所述情感特征。
30、进一步地,所述对所述调整文字信息进行分析的步骤包括:
31、对所述调整文字信息进行分词处理,获取词汇序列;
32、基于所述词汇序列构建词汇向量;
33、利用词汇向量和预设特征提取模型,提取所述调整文字信息的词汇特征。
34、进一步地,所述根据所述对话特征构建对话场景模型的步骤包括:
35、基于所述情感特征和所述词汇特征构建对话特征向量;
36、利用所述对话特征向量和预设场景分类模型,对所述对话场景进行分类;
37、根据分类结果确定对应的对话场景标签;
38、根据所述对话场景标签和预设场景模板,构建所述对话场景模型。
39、进一步地,所述基于所述对话场景模型对所述语音数据生成初始回答信息的步骤包括:
40、基于所述对话场景模型确定所述语音数据所属的目标对话场景;
41、根据所述目标对话场景和预设场景回复策略,生成初始回答信息;
42、其中,所述预设场景回复策略包括不同对话场景下的回复模板和回复内容。
43、具体而言,本发明实施例根据目标对话场景的不同,回复模板和回复内容也会有所区别,以更好地适应不同对话场景的需求。
44、进一步地,所述根据反馈数据对所述对话场景模型进行优化的步骤包括:
45、收集用户对于初始回答信息的反馈数据,包括满意度评分和回复内容评价;
46、提取所述回复内容评价中关键词,对关键词进行分析,根据分析结果确定文本满意度;
47、根据所述满意度评分和文本满意度确定实际满意度;
48、当所述实际满意度小于预设满意度时,基于所述关键词和预设回答优化规则,对所述初始回答信息进行优化处理;
49、其中,所述预设回答优化规则包括回答长度限制和关键词替换规则。
50、与现有技术相比,本发明的有益效果在于,通过将用户语音数据转化为初始文字信息,并基于标准语言数据库进行标准化调整,确保了对话内容的准确性和一致性,结合对语音数据的情感特征分析和对调整文字信息的词汇特征分析,能够更准确地理解用户的意图和需求,从而提高对话的准确性,根据用户对话特征构建对话场景模型,并基于该模型生成初始回答信息,使对话更加自然、流畅,通过接收用户对初始回答信息的反馈数据,并据此优化对话场景模型,系统能够持续学习和改进,以提供更加个性化的对话服务,借助ai大模型的强大计算能力和处理能力,该方法能够处理更多的数据,适应不同的对话场景和需求,ai大模型在更短的时间内能够得出更准确的结果,使得对话系统能够迅速响应用户的查询和需求,提高了处理效率,通过对用户反馈数据的收集和分析,系统能够识别出存在的问题和改进的方向,实现数据驱动的持续优化,有助于提升对话系统的性能。
- 还没有人留言评论。精彩留言会获得点赞!