基于特征增强和融合的弱监督视频异常检测方法及系统
本发明涉及视频异常检测,尤其涉及一种基于特征增强和融合的弱监督视频异常检测方法及系统。
背景技术:
1、本部分的陈述仅仅是提供了与本发明相关的背景技术信息,不必然构成在先技术。
2、监控摄像头的一个重要的职能就是通过实时监测来及时发现和记录任何可能发生的异常情况,视频异常检测就是用来解决这个问题的计算机视觉任务。视频异常检测的目的是使用算法和模型来替代人工对视频序列进行分析,将与正常行为明显不同的异常事件进行自动地检测和标识。这些异常可能包括突发事件、异常行为、不寻常的物体或者环境的剧烈变化等。视频异常检测在公共安全、考场监控以及交通管理等许多领域都发挥着提高效率和准确度的重要作用。
3、根据视频异常检测的训练数据类别及其标签情况可将其分为基于半监督学习的方法和基于弱监督学习的方法这两大类。基于半监督学习的算法使用“非正即异”的假设,仅使用未经标注的正常视频作为训练输入,将与学到的正常特征显著偏离的数据检测为异常。尽管无需人工标记减少了前期工作量,然而“非正即异”假设中固有的缺陷注定半监督算法无法投入实际应用。现实中并不存在能够囊括所有正常事件特征的样本空间,因此新的、未被学习过的正常事件极有可能被误检。仅学习正常事件的特征表示无法针对异常事件的漏检或误检进行优化,导致此类方法在实际应用中的异常检测准确性也相对较低。
4、在基于弱监督学习的视频异常检测框架中,训练集包含了正常和异常的视频样本,但是仅提供了视频级别的标签信息,无法获知异常事件发生的具体起止时间。弱监督方法在减少对人工精细标注依赖的前提下,仍能有效保证异常检测的精度。
5、尽管已经有一些弱监督视频异常检测方法,但是它们存在以下不足:
6、(1)没有充分利用时序信息。视频异常检测中的特征辨识度是一个关键问题,在实际应用中,正常与异常之间的边界模糊不清,这要求模型需要具备高度区分性的表征学习能力。之前的一些方法仅从当前孤立的视频片段中提取特征来判断异常,忽略了时序动态建模的重要性。
7、(2)未能充分利用跨模态关系。在特征提取方面,大多数现有方法仅依赖于单一模态即视觉信息的处理,忽视了其他信息源例如语言信息的作用。
8、(3)忽视了数据不平衡问题。数据分布的不平衡是异常检测的一个显著特征,正常示例的数量通常远超异常示例,这导致模型在训练过程中倾向于过拟合正常而对异常事件的识别能力不足。
9、许多现有的方法没能充分挖掘和利用所有可能携带异常信息的样本,由于缺乏针对性的设计而在异常模式的识别上存在遗漏。
技术实现思路
1、为了解决上述问题,本发明提出了一种基于特征增强和融合的弱监督视频异常检测方法及系统,通过时序特征增强网络从局部和全局学习时序依赖关系,同时引入视觉-语言知识关联机制,实现了视频数据的时空结构信息和语义标签的语言信息的深层次理解和融合,进而提升异常检测的准确性。
2、在一些实施方式中,采用如下技术方案:
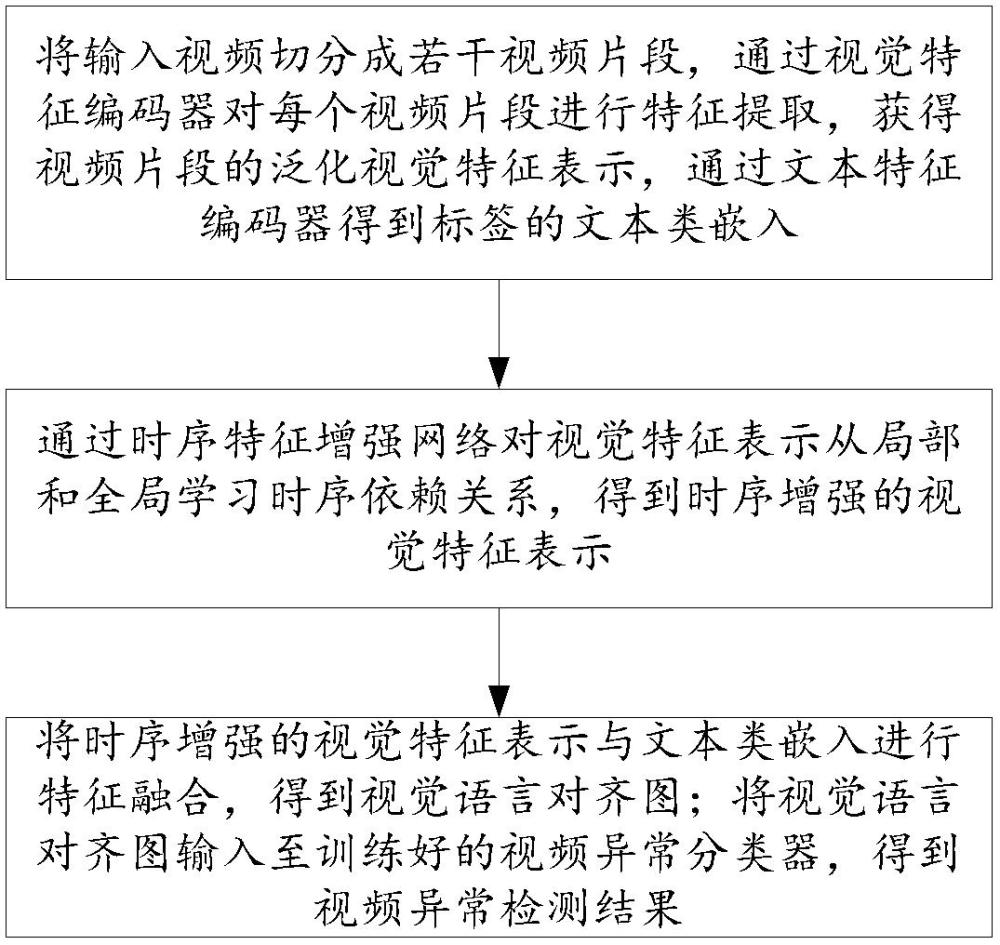
3、一种基于特征增强和融合的弱监督视频异常检测方法,包括:
4、将输入视频切分成若干视频片段,通过视觉特征编码器对每个视频片段进行特征提取,获得视频片段的泛化视觉特征表示,通过文本特征编码器得到标签的文本类嵌入;
5、通过时序特征增强网络对视觉特征表示从局部和全局学习时序依赖关系,得到时序增强的视觉特征表示;
6、将时序增强的视觉特征表示与文本类嵌入进行特征融合,得到视觉语言对齐图;将视觉语言对齐图输入至训练好的视频异常分类器,得到视频异常检测结果。
7、作为可选的方案,使用clip模型作为特征提取器,所述clip模型包括视觉特征编码器和文本特征编码器;
8、将视频类别标签通过clip分词器得到原始的词元,然后将包含 m个上下文词元的可学习提示加入到原始词元的前方和后方形成一个完整的词元;将组装好的完整词元和位置向量相加,送入文本特征编码器中得到文本类嵌入。
9、作为可选的方案,通过时序特征增强网络对视觉特征表示从局部和全局学习时序依赖关系,具体为:
10、将视觉特征表示在时间维度上分割为等长且重叠的窗口,在每个窗口内进行局部自注意力计算,得到局部时间特征表达;
11、利用图卷积网络从特征相似性和相对距离的角度对全局时间依赖进行建模学习,得到时序增强的视觉特征表示;其中,计算两个视频片段视觉特征表示之间的相似度,生成图卷积网络的视频特征相似矩阵;计算两视频帧之间的距离,生成图卷积网络的视频帧位置距离矩阵。
12、作为可选的方案,将时序增强的视觉特征表示与文本类嵌入进行特征融合,得到视觉语言对齐图,具体为:
13、将时序增强的视觉特征表示输入到全连接神经网络中获取视觉特征的异常分数,基于异常分数和时序增强的视觉特征表示得到视觉提示,所述视觉提示与文本类嵌入相加后输入至前馈神经网络,得到视觉语言对齐图。
14、其中,所述全连接神经网络由带有残差连接的前馈神经网络ffn、一个全连接层fc以及sigmoid激活函数组成。
15、基于异常分数和时序增强的视觉特征表示得到视觉提示,具体为:通过异常分数和时序增强的视觉特征表示的点积得到视觉提示,然后对点积进行归一化。
16、作为可选的方案,计算视频样本中每个视频片段的异常分数,对所有异常分数由大到小进行排序,选取前 k个异常分数对应的视频片段对视频异常分类器进行训练。
17、作为可选的方案,所述视频异常分类器的损失函数具体为:分类损失、对比损失、时间平滑损失以及稀疏损失的加权和。
18、在另一些实施方式中,采用如下技术方案:
19、一种基于特征增强和融合的弱监督视频异常检测系统,包括:
20、特征提取模块,用于将输入视频切分成若干视频片段,通过视觉特征编码器对每个视频片段进行特征提取,获得视频片段的泛化视觉特征表示,通过文本特征编码器得到标签的文本类嵌入;
21、特征增强模块,用于通过时序特征增强网络对视觉特征表示从局部和全局学习时序依赖关系,得到时序增强的视觉特征表示;
22、异常检测模块,用于将时序增强的视觉特征表示与文本类嵌入进行特征融合,得到视觉语言对齐图;将视觉语言对齐图输入至训练好的视频异常分类器,得到视频异常检测结果。
23、在另一些实施方式中,采用如下技术方案:
24、一种终端设备,其包括处理器和存储器,处理器用于实现指令;存储器用于存储多条指令,所述指令适于由处理器加载并执行上述的基于特征增强和融合的弱监督视频异常检测方法。
25、与现有技术相比,本发明的有益效果是:
26、(1)本发明创新性的提出了局部-全局时序关系增强模块,使得各个视频片段的特征能够与相邻及远程片段的特征进行深度关联,在短周期内能够捕捉到局部动作的时间连续性变化,在长周期上能够学习到全局行为的时间相关模式;
27、(2)本发明创新性的提出了视觉语言融合模块来对齐视觉和语言特征,引入视觉-语言知识关联机制,使得视觉和语言两种模态更好地进行融合以促进模型在视觉与语言层面上对异常达成准确一致的理解和表征;从而实现对视频数据的时空结构信息和语义标签的语言信息的深层次理解和融合,进而提升异常事件检测的准确性。
28、(3)本发明对传统的多示例学习进行了改进,让每个视频样本中异常分数值较大的视频片段参与视频异常分类器的训练,让异常视频包中更多的异常示例参与到模型的训练过程中,在一定程度上缓解了正负样本数量间的差距,提升了模型对异常检测的敏感性和准确性,使得分类器能够更全面地捕获不同视频包内异常行为的多样性和复杂性。
29、(4)本发明创新性的提出了一种新的多对的对比损失,它不仅强调正常样本应当在特征空间中与各类异常样本形成显著地分离,而且还考虑到不同类型的异常事件之间也应该保持足够的区分度。这样既能强化模型对正常行为的表征,又能确保模型可以有效区分各种异常行为,从而提升了基于弱监督学习的视频异常检测的性能。
30、本发明的其他特征和附加方面的优点将在下面的描述中部分给出,部分将从下面的描述中变得明显,或通过本方面的实践了解到。
- 还没有人留言评论。精彩留言会获得点赞!