一种基于改进unet网络的联邦持续学习方法与流程
本发明涉及联邦学习领域,涉及一种基于改进unet网络的联邦持续学习方法,目标是保护数据隐私并且减轻遗忘历史知识。
背景技术:
1、联邦学习fl中的每个客户端在本地保留数据,并仅将训练更新传输到中央服务器进行聚合。传统的fl假设客户端拥有的数据是静态的,但实际上随着时间的推移,客户端可能出现新的数据类别。例如,在移动边缘计算(mec)网络中,边缘设备(ue)不断生成数据集,出现新的数据类别。
2、基于这种场景,在联邦框架中引入了持续学习的概念,联邦持续学习(fcl)允许本地客户端不断收集新的数据,并且随时动态添加新类。由于数据隐私、本地客户端存储有限和任务差异,过去网络的知识将被遗忘。并且,fl中客户端之间的数据分布不平衡会加剧了灾难性的遗忘问题。显然,这种遗忘不利于fl的进步。因此如何让设备在新的环境中参与联邦学习,同时保留旧的知识是一个有待研究的问题。
3、目前联邦学习解决上述挑战的手段主要是利用额外的数据集或先前的任务数据。但是这在某些数据敏感的场景中难以获得且无法捕获原始数据的全部复杂性。考虑使用一个生成器来合成历史数据集,旨在模拟每个客户端上数据的全局分布。然而,模型在一系列冗长的任务上进行训练时,存在生成数据质量恶化的潜在风险。最大限度地维护和保留当前任务中旧任务数据的表示,成为了重要问题。针对上述问题,一种既能保证合成历史数据集图像质量,又能高效聚合客户端知识的研究方法,具有重要研究意义。
技术实现思路
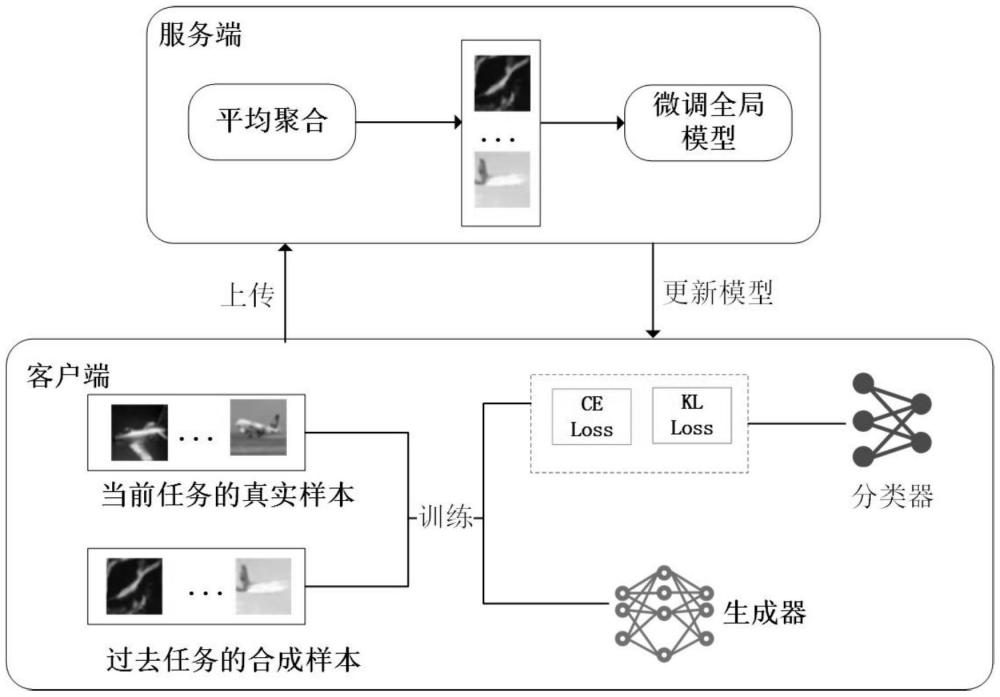
1、本发明目的在于数据隐私敏感场景下,如何在不存储客户端的本地私有数据或任何额外数据集的情况下有效地缓解fcl中的灾难性遗忘问题,提出了一种利用扩散模型作为生成模型的联邦持续学习方法,基于unet网络特点,新增“分类器”模块,赋予了unet标签分类的额外功能。因此,不需要其他的分类器,例如alexnet,减小模型大小,优化服务器内存资源。
2、本发明提供了一种基于改进unet模型的联邦持续学习方法,具体训练方法包括如下步骤:
3、步骤1、服务器分发unet网络所有参数至各个客户端。
4、步骤2、客户端将本地真实数据按一定比例分割为训练集和验证集,并更新unet网络参数,本地训练开始;
5、步骤3、若当前任务是初始任务,则冻结unet网络“解码器”模块参数,以仅包含本地真实数据的训练集为基础,使用交叉熵损失,训练本地分类器,特别是unet的“分类器”参数,之后转至步骤6;
6、若当前任务不是初始任务,客户端冻结unet“分类器”模块参数,使用基于unet网络去噪的扩散模型作为生成器,用本地历史任务的标签,在本地上个任务的unet分类器梯度指导下合成样本;
7、步骤4、将合成样本分割为训练集和验证集,加入本地训练集中,本地训练集由仅包含真实数据更新为真实数据和合成样本的混合,验证集同理;
8、步骤5、冻结unet网络“解码器”模块参数,先以包含本地真实数据和合成样本的本地训练集为基础,使用交叉熵损失,训练本地分类器;再以本地合成样本为基础,以服务端模型作为教师模型,使用kl散度,训练本地分类器;
9、步骤6、用本地验证集测试,保存最优的本地分类器参数;
10、步骤7、本地训练生成器。初次通信时,冻结unet的“分类器”模块,用本地真实数据训练扩散模型,特别是unet的“解码器”参数。若当前不是初始任务,也使用合成样本训练;
11、步骤8、客户端本轮训练结束,将unet网络所有参数,包括分类器参数和生成器参数上传到服务器。若当前不是初始任务,也上传步骤3得到的本地合成样本;
12、步骤9、服务端对unet模型所有参数进行全局平均聚合。若当前不是初始任务,再用得到的所有本地合成样本,用交叉熵损失函数训练分类器参数;
13、步骤10、联邦训练结束,输出最终预测模型。
14、作为优选,所述服务器分发至客户端的是全局模型的参数。
15、作为优选,所示全局模型的主干网络为unet网络,在unet网络的中间层后添加分类器标签输出层。目前unet网络在扩散模型采样过程中负责预测噪音,本发明基于unet网络特点,更新模型结构,赋予了unet标签分类的额外功能。因此,不需要其他的分类模型,例如alexnet,减小模型大小,优化服务器内存资源。设计新的unet模型,满足了预测噪音和标签分类需要,减少了需要训练的参数数量,从而降低了模型的复杂度和内存需求。
16、作为优选,所述分类器标签输出层包括依次连接的归一化层、silu激活函数、attentionpool2d层、全连接层。
17、作为优选,所述步骤3中的本地分类器的训练方法为:
18、
19、其中,ωi是第i个客户端轮次更新的模型参数,是客户端i的本地真实数据,是数据对应的真实标签类别,是模型预测标签类别,两者使用交叉熵公式计算损失。
20、作为优选,所述步骤5中本地分类器的训练方法为:先在真实数据和合成样本上用公式(2)训练本地分类器,学习新的知识;之后用本地合成样本和公式(3),限制本地模型偏离初始的全局模型,更好地利用全局知识:
21、
22、其中,xi是客户端i本地训练集数据,包括真实数据和合成样本;公式(3)是kl散度,是客户端i的本地合成样本,是上一轮通信聚合的全局模型对当前客户端本地合成样本的预测输出类别。
23、作为优选,所述步骤6中,训练扩散模型的步骤是:
24、①在给定时间步长l和原始图像x0上添加噪声,生成xl。
25、②计算损失:使用当前unet网络参数预测噪声,计算预测噪声与实际添加噪声之间的损失,即其中,∈θ是unet网络除“分类器”模块外的参数;xl是在步数l加噪后的图像,y是类别标签。
26、③反向传播和更新参数:通过反向传播计算梯度,并使用优化器更新网络参数。
27、④重复以上步骤1-3,直到达到预定的训练轮数。目标是优化unet网络的预测噪音能力,学习图像更丰富的特征表示。
28、作为优选,所述步骤9中,全局平均聚合参照公式(4),用所有本地合成样本和交叉熵损失函数训练分类器参数参照公式(5):
29、
30、公式(4)中,ωg是全局分类器模型,是任务t时客户端i的“分类器”参数;∈是扩散模型,具体是unet网络除“分类器”模块外的参数。nt,i是任务t时客户端i的真实数据数目,是任务t时所有客户端的真实数据量;公式(5)中,ce是交叉熵损失,表示所有的本地合成数据。
31、作为优选,所述步骤2-9为联邦训练迭代周期。
32、作为优选,联邦训练迭代周期数为联邦学习设定的通信轮次。
33、作为优选,所述的方法目标是最小化全局损失函数:
34、
35、其中,表示客户端i的“分类器”模型对所有任务数据的损失,目标使得各个客户端的模型性能在所有的任务上达到极值。
36、进一步地说,所述的方法设计新的unet模型,满足了预测噪音和标签分类需要,有效减小模型大小。
37、本发明的有益效果:
38、1、在不违背数据隐私安全前提下,使用扩散模型作为历史数据的生成重放模型,改善生成图像质量,降低生成器模式崩溃风险。
39、2、通过更新后的unet网络同时进行图像生成和分类,简化训练和推理过程中的计算和资源开销,联合这两个任务也可以让模型学习到更全面、更丰富的特征表示。
40、3、在联邦学习的服务器端,使用小批量的合成样本来训练分类器和生成器,可以更有效地学习全局知识,并减轻遗忘的风险。
- 还没有人留言评论。精彩留言会获得点赞!