一种基于数据驱动的井漏风险智能预警方法、装置、电子设备及存储介质
本发明涉及石油钻井工程领域,尤其是涉及一种基于数据驱动的井漏风险智能预警方法、装置、电子设备及存储介质。
背景技术:
1、在石油钻井过程中,井漏是一种高频性、高复杂性、高危害性的井下复杂情况。井漏的发生往往不是一蹴而就的,而是通过一段异常状况的累积逐渐形成的,这导致井漏的预测难度高,准确率低且缺乏科学依据。现有的井漏预警技术主要依靠专家经验和邻井资料,通过人工坐岗实时监测井下动态进行告警,需要投入大量的人力、物力、财力且预警效果不佳。目前,数据挖掘技术与人工智能技术已经在许多领域展现出良好的应用效果,若能将二者结合并赋能于井漏预警场景,将为井漏预警实现智能化提供一种可靠思路,对维护钻井安全,辅助堵漏决策具有积极意义。
2、钻井数据主要是从综合录井仪中测量获取的,但由于不同井口采用的综合录井仪的型号、精度、采集频率、测量参数都存在差异性,导致采集到的钻井数据质量良莠不齐,脏数据、死数据占比高,造成巨大的数据浪费。因此,亟需对海量的钻井大数据进行数据清洗,消除数据噪声,提高数据质量。有些学者采用滤波技术对数据进行平滑处理,这样虽然可以去除噪声,但也导致数据中的一些真实波动特征也随之流失,且部分滤波技术具有滞后性,不能及时反映数据变化特征规律。
3、在故障预警案例中,存在模型预警准确率虚高的情况,这是由正负样本失衡引起的。若多数类样本与少数类样本的数量差异过大,分类器会优先倾向投票给多数类样本,导致漏警率变高,模型的分类性能大大降低,导致无效预警。在井漏预警问题中,同样也存在着安全钻进数据数量远超于井漏数据的现象,因此,为提高井漏预警的有效性和可靠性,对样本进行类别均衡处理是十分有必要的。
技术实现思路
1、本发明的目的在于提供一种基于数据驱动的井漏风险智能预警方法、装置、电子设备及存储介质,通过对海量钻井数据进行数据清洗和数据预处理,采用lowess算法实现海量钻井数据的平滑降噪,利用borderline-smote方法调整井漏样本与安全钻进样本的类别权重系数,并结合机器学习框架lightgbm搭建井漏智能预警模型,以解决钻井工程中钻井数据可利用率不高、样本类别不平衡、井漏风险预警智能化程度不高的问题。
2、为实现上述目的,本发明提供了一种基于数据驱动的井漏风险智能预警方法,包括以下步骤:
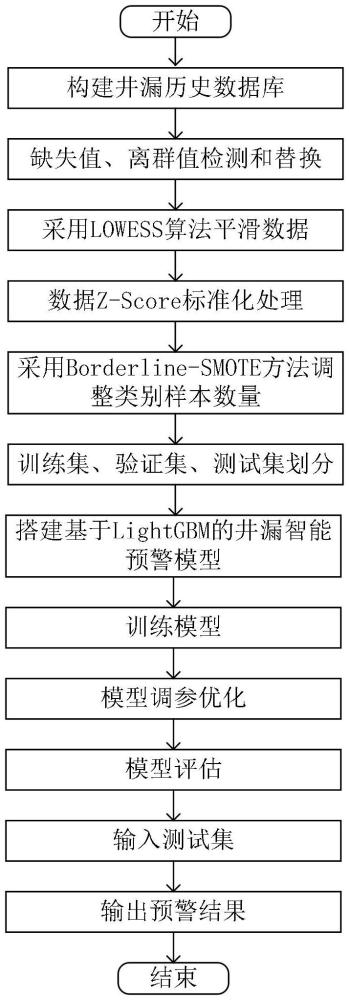
3、步骤1、获取不同井口的随钻历史数据,形成井漏历史数据库,对随钻历史数据进行预处理;预处理主要包括钻井数据的缺失值处理、离群值处理及平滑处理;
4、步骤2、对井漏历史数据库中的海量数据进行工况划分,制定标签规则并做标准化处理,构建安全钻进数据集与井漏征兆数据集;
5、步骤3、采用borderline-smote方法调整安全钻进数据集与井漏征兆数据集的类别权值,使安全钻进数据集与井漏征兆数据集的数据体量均衡;
6、步骤4、融合步骤2生成的数据集与步骤3生成的数据,将融合后的数据按照8:1:1的比例划分为训练集、验证集和测试集;
7、步骤5、搭建基于lightgbm的井漏智能预警模型,设置模型初始超参数,采用训练集进行模型训练;
8、步骤6、采用验证集进行井漏智能预警模型的优化与参数调整,选用混淆矩阵、roc曲线、特异性、马修斯相关系数评价模型性能;
9、步骤7、测试井漏智能预警模型性能及泛化能力,将测试集输入模型中,测试模型的有效性和可靠性,并输出模型预警结果。
10、优选的,在数据平滑处理,采用lowess算法实现海量钻井数据的平滑处理,具体步骤为:
11、针对所需平滑数据点附近的数据搭建lowess模型,采用三角核函数作为lowess模型的加权函数,计算每个邻近点的权值因子,根据邻近点对所需平滑点的影响程度进行局部加权回归,使用加权最小二乘法拟合lowess模型,从而得到整组数据的lowess曲线,实现平滑效果。
12、优选的,对井漏历史数据库中的海量数据进行工况划分,制定标签规则并做标准化处理,构建安全钻进数据集与井漏征兆数据集,具体为:
13、针对海量的钻井数据,根据钻井日报等随钻资料记载的施工信息,提取安全钻进工况数据与井漏复杂情况数据,在提取井漏复杂情况数据时,需结合数据特征分析手段,提取井漏事故发生前期含有井漏征兆的钻井数据;
14、对提取的安全钻进工况数据与井漏复杂情况数据制定标签规则,其中,安全钻进工况数据的标签为0,井漏复杂情况数据的标签为1,得到标签信息;
15、采用z-score法对安全钻进工况数据与井漏复杂情况数据进行标准化处理;
16、将标签信息与标准化后的数据进行组合,形成安全钻进数据集与井漏征兆数据集。
17、优选的,采用borderline-smote方法调整安全钻进数据集与井漏征兆数据集的类别权值,使安全钻进数据集与井漏征兆数据集的数据体量均衡,具体为:
18、钻井数据集为s,s∈rn,安全钻进数据集为s1,井漏征兆数据集为s2,s=s1∪s2,其中安全钻进数据集s1为多数类样本,s2为少数类样本,将s2按照分为safe、danger、noise三类;
19、p为某个井漏数据点,p∈s2,选取与p点距离最近的k个样本点作为p的近邻样本集,p点的近邻样本集为sk,当p点属于safe类别;当p点属于danger类别;当|sk∩s1|=k,p点属于noise类别;
20、对danger样本使用插值方法合成新的井漏数据,新的井漏数据位于该danger样本与其近邻井漏样本的连线上。
21、优选的,根据安全钻进数据集和井漏征兆数据集的类别分布情况设置合适的c,在danger样本的近邻样本集中选取c个近邻井漏数据点,在danger样本和c个近邻井漏数据点之间合成c个新样本,具体公式为:
22、
23、其中,表示新生成的第i个样本;xd表示danger样本的值;xi表示xd的第i个近邻井漏样本的值;ri表示xi对应的随机系数,0<ri<1;
24、对s2中的每个danger样本都采用上述步骤生成新样本,s2中有n个danger样本,则最终获得c×n个新样本。
25、优选的,采用训练集进行模型训练,具体为:
26、在训练集中,将钻压、立管压力、钻时、池体积、泥浆溢漏、扭矩、转速、出口流量、入口流量、出口温度、入口温度、dczs的井漏关联参数作为模型输入,对基于lightgbm的井漏智能预警模型进行迭代训练。
27、一种基于数据驱动的井漏风险智能预警装置,包括
28、数据获取模块用于从综合录井仪中获取各区块不同井口的随钻历史数据,建立井漏历史数据库;
29、数据清洗模块:用于缺失值处理和利群处理;
30、数据增强模块用于采用lowess平滑数据和采用borderline-smote方法调整类别权值,使安全钻进数据集与井漏征兆数据集的数据体量均衡;
31、模型搭建模块用于融合步骤2生成的数据集与步骤3生成的数据,将融合后的数据按照8:1:1的比例划分为训练集、验证集和测试集,并且搭建基于lightgbm的井漏智能预警模型,设置模型初始超参数,采用训练集进行模型训练;
32、模型评估模块用于采用验证集进行井漏智能预警模型的优化与参数调整,选用混淆矩阵、roc曲线、特异性、马修斯相关系数评价模型性能。
33、一种电子设备,包括存储器和处理器,所述存储器中存储有计算机程序,所述处理器调用所述存储器中的计算机程序时实现一种基于数据驱动的井漏风险智能预警方法的步骤。
34、一种存储介质,所述存储介质中存储有计算机可执行指令,所述计算机可执行指令被处理器加载并执行时,实现一种基于数据驱动的井漏风险智能预警方法的步骤。
35、因此,本发明采用上述的一种基于数据驱动的井漏风险智能预警方法,技术效果如下:
36、(1)本发明针对仪器测量误差、施工环境噪声等原因导致的钻井数据不能确切地反映钻井状态及井下动态的问题,采用lowess算法构建局部加权拟合模型,充分考虑不同邻近点对该点拟合的贡献程度,根据贡献程度赋予相应的权值因子,绘制lowess曲线拟合原始数据,在保留原始数据特征的条件下剔除数据噪声,提高数据质量。
37、(2)本发明针对钻井数据中存在安全钻进工况数据与井漏复杂情况数据体量差异过大的问题,提出一种基于borderline-smote的类别均衡方法,通过挖掘井漏边界样本的内在特征,使生成的新数据满足原始数据的分布特性,提高扩充数据集的可靠性,在实现类别均衡的同时提高井漏数据识别效率。
38、(3)本发明针对目前井下复杂情况预警仍旧需要人工坐岗监测、极度依赖专家经验的现实难题,构建一种基于lightgbm的井漏智能预警模型,该模型通过采用单边梯度采样、leaf-wise生长策略及互斥特征捆绑算法实现快速的梯度提升,在运行速度、内存占用率、并行学习和处理大规模数据方面具有优异性能,能够实现及时、准确、智能化的井漏风险预警。
- 还没有人留言评论。精彩留言会获得点赞!