基于可解释人工智能的生产业务流程超时预测方法
本发明涉及业务流程管理,具体涉及一种基于可解释人工智能的生产业务流程超时预测方法。
背景技术:
1、在当今的工业和商业环境中,生产业务流程的效率是企业竞争力的关键。随着全球化和技术革新的加速,市场需求的多变性要求企业必须具备快速响应的能力。生产业务流程的每一个环节,从原材料的采购到成品的交付,都需要精确的时间管理和流畅的运作协同。然而,不确定性因素如供应链中断、设备故障、人力资源短缺等,都可能导致生产流程的延迟,影响企业的交付能力和客户满意度。为了应对这些挑战,企业越来越依赖于先进的技术手段来提升生产流程的监控和优化能力。人工智能和大数据技术的发展,为生产流程的智能化管理提供了新的可能性。通过收集和分析大量的生产数据,企业能够更好地理解流程中的各种模式和趋势,预测潜在的风险,并实时调整资源分配和流程策略。在这一背景下,超时预测成为了生产流程管理的一个关键组成部分。超时预测能够帮助企业及时识别那些可能导致生产延迟的环节,从而采取预防或补救措施,减少损失。
2、机器学习模型,尤其是深度学习模型,因其强大的特征提取能力和高预测精度,在生产业务流程超时预测任务中得到了广泛应用。这些模型能够从复杂的生产数据中学习到隐含的模式,并做出较为准确的预测。然而,深度学习模型通常被认为是“黑盒”,其内部的决策逻辑对于业务专家是不透明的。这种缺乏可解释性的问题,使得业务专家难以理解模型的预测结果是如何得出的,也难以判断模型的预测是否可靠。在实际业务决策中,可解释性是至关重要的。业务专家需要理解模型预测背后的逻辑和推理,以便对模型的判断进行验证。如果模型预测某个生产流程可能会超时,业务专家需要知道这是由于供应链的问题、设备的不稳定,还是其他原因。只有这样,他们才能采取针对性的措施,如改进供应链管理、维护设备或优化作业流程。如果模型不能提供这些预测背后的逻辑和推理,它们的应用范围将受到限制。业务决策者可能不愿意根据不透明的模型输出来做出关键决策,因为这涉及到巨大的运营风险和潜在的经济损失。
3、因此,提高模型的可解释性对于获得业务专家的信任、促进模型在实际业务中的接受度和应用至关重要。一个可解释性好的超时预测模型,不仅能够帮助企业更有效地管理生产流程,还能够提升企业的决策质量和响应速度,增强企业的市场竞争力。
技术实现思路
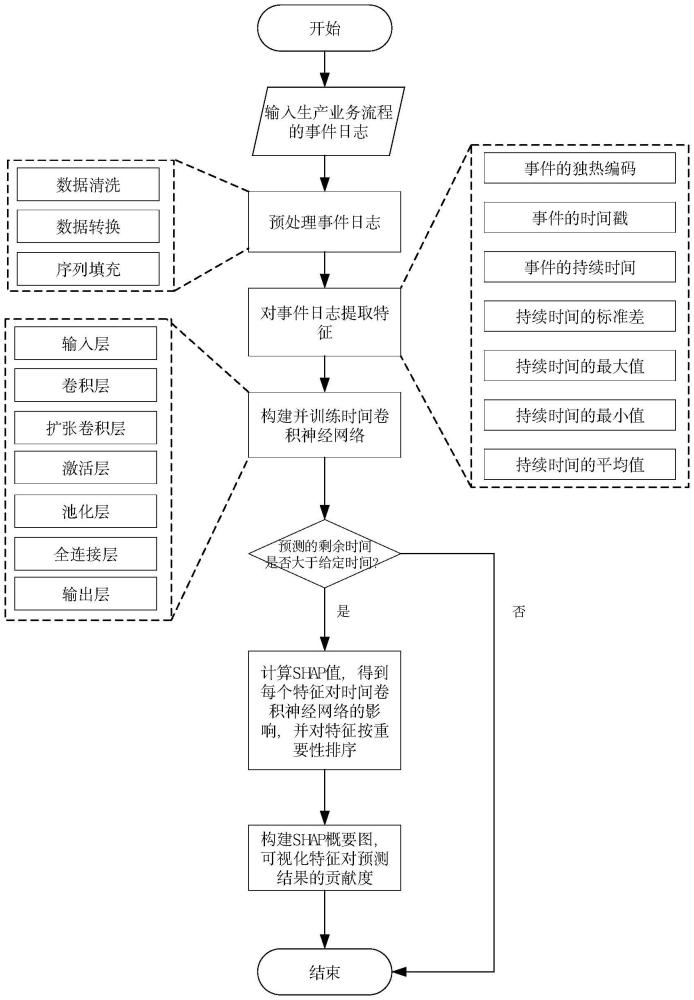
1、本发明提出了一种基于可解释人工智能的生产业务流程超时预测方法,旨在提供一种高效、准确且可解释的超时预测方法,以支持生产业务流程后续的优化。该方法首先涉及对生产业务流程的事件日志进行预处理,确保数据的质量和一致性。随后,从清洗后的数据中提取关键特征,这些特征能够反映生产流程的关键属性和模式。接着构建并训练一个时间卷积网络(temporal convolutional network,tcn)模型,该模型专门设计用于分析时间序列数据,并能准确预测生产业务流程的剩余执行时间,通过判断tcn模型的预测结果是否超过预设的超时阈值,可以及时识别潜在的延迟风险。进一步,为了提高tcn模型的可解释性,本发明采用了shap(shapleyadditive explanations)值分析,一种基于博弈论的解释方法,用以确定各特征对预测结果的具体贡献度。最终,本发明通过构建shap概要图将复杂的预测结果和特征贡献以可视化的方式展现出来,使得业务专家能够直观理解模型的预测逻辑,从而提高模型的可信度和决策支持的有效性。
2、一种基于可解释人工智能的生产业务流程超时预测方法,包括以下步骤:
3、(1)预处理生产业务流程的事件日志,为后续的特征提取、模型训练和预测提供准确的输入。生产业务流程的事件日志记录了流程中各个节点的详细活动、时间戳和资源等情况,预处理确保数据的清洁、一致和格式化,以满足模型训练的要求;
4、(2)对事件日志提取特征,目标是从原始数据中识别出对预测任务最有帮助的信息,并将其转换为数值型特征,这些特征能够反映生产业务流程的关键属性和模式,具体如下:
5、事件的独热编码:将每个不同的事件类型转换为一个二进制向量,其中除了表示该事件类型的元素为1外,其余所有元素均为0;
6、事件的时间戳:事件发生的时间戳,直接从日志中提取;
7、事件的持续时间:直接从日志中提取;
8、持续时间的标准差:
9、
10、其中n是活动发生的次数,xi是当前案例中第i个活动的持续时间,μ是所有活动持续时间的平均值;
11、事件的独热编码:将每个不同的事件转换为一个二进制向量,其中除了表示该事件的元素为1外,其余所有元素均为0;
12、持续时间的最大值:max=max(x1,x2,…,xn);
13、持续时间的最小值:min=min(x1,x2,…,xn);
14、持续时间的平均值,即所有活动持续时间的总和除以活动个数:
15、
16、(3)构建并训练一个时间卷积网络模型(temporal convolutional network,tcn),利用该模型对生产业务流程的剩余执行时间进行准确预测;
17、(4)判断tcn预测的剩余执行时间是否大于给定时间,若是则判定为超时,执行步骤(5);
18、(5)计算预测结果的shap(shapleyadditive explanations)值。shap值是一种基于博弈论中shapley值的模型解释方法,用于解释机器学习模型的预测。在tcn模型预测剩余执行时间后,shap值帮助确定每个特征对预测结果的贡献度。shap值的核心思想是公平性,即所有特征的贡献度总和应该解释模型的整个预测变化;
19、(6)构建shap概要图,可视化展示每个特征对tcn模型预测结果的贡献度,进一步帮助理解哪些因素导致了生产业务流程的超时预测;
20、进一步,所述的步骤(1)由以下步骤组成:
21、(1.1)数据清洗,识别并处理缺失的数据,采用缺失值填充的方法,具体如下:
22、
23、其中,x′是填充值,xi是其他观测值,n是观测总数,j是缺失值的索引;
24、(1.2)数据转换,采用归一化方法,将不同量纲和范围的特征转换到相同的尺度,以消除规模差异的影响,具体如下:
25、
26、其中,xnorm是归一化后的特征值,xi是原始特征值,max(x)和min(x)分别是特征值的最大值和最小值;
27、(1.3)序列填充,对不同长度的序列进行填充或截断,以形成统一长度的输入,具体如下:
28、xpad={x1,x2,...,xl-1,xl,pad}
29、其中,xpad是填充后的序列,x1,...,xl是原始序列,pad是填充值;
30、进一步,所述的步骤(3)由以下步骤组成:
31、(3.1)tcn的网络结构如下:
32、输入层:用于接收特征矩阵其中n是批次大小,l是序列长度,d是特征维度;
33、一维卷积层:用于提取局部时序特征,一维卷积操作可以表示为:
34、
35、其中,k为卷积核的大小,yt是在时间步t的输出,wτ是卷积核权重,xt-τ是时间步t-τ的输入,b是偏置项;
36、因果扩张卷积层:用于增加感受野,定义为:
37、
38、其中,yt是输出序列在时间步t的值,τ是卷积核中的索引,用于遍历卷积核中的每个元素,wτ是卷积核在位置τ的权,k为卷积核的大小,d是扩张率,用于控制卷积核中元素的间隔,xt-d×τ是输入序列在时间步t-d×τ的值,在扩张卷积中,卷积核的中心位于t,而其他元素根据扩张率d间隔地分布在序列上;
39、权重归一化层:通过权重归一化处理,优化网络的训练过程,提高模型的泛化能力;
40、残差块:网络由多个残差块串联组成,每个残差块内部集成了复杂的特征提取和处理机制,残差连接帮助深层网络训练,通过跳过一层或多层直接相加:ot=at+xt
41、其中,ot是残差连接的输出,at是经过激活函数的卷积层输出,xt是输入;
42、随机失活层dropout:通过随机失活部分神经元,防止模型过拟合,提高模型的鲁棒性;
43、激活层:采用relu激活函数,用于引入非线性:at=relu(ot)=max(0,ot),其中,ot是残差连接的输出,at是经过激活函数的卷积层输出;
44、全连接层:将特征从时序数据转换为最终的预测输出:f=w′o+b′,其中和分别是全连接层的权重和偏置,m是输出维度,h是全连接层的输入维度;
45、输出层:是一个具有单个神经元的全连接层,用于预测剩余执行时间y=w″f+b″,其中f是全连接层的输出,和是输出层的权重和偏置;
46、(3.2)tcn的损失函数如下:
47、
48、其中,yi是模型预测的第i个样本的剩余执行时间,yi是实际的剩余执行时间;
49、(3.3)tcn使用adam优化器来更新网络权重,具体优化算法如下:
50、
51、其中,η是学习率,moment1和moment2是adam优化器计算的一阶和二阶矩估计,∈是一个很小的数值以保证数值稳定性;
52、(3.4)训练tcn,目标是最小化预测输出和实际剩余执行时间之间的差异,tcn的训练过程如下:首先初始化网络参数;然后对于每个训练批次:a.执行前向传播计算预测输出,b.计算步骤(3.2)中的损失函数,c.执行反向传播计算梯度,d.更新网络参数;接着在验证集上评估模型性能并调整超参数;最后在测试集上评估最终模型性能;
53、进一步,所述的步骤(5)由以下步骤组成:
54、(5.1)shap值计算每个特征对tcn模型输出的影响。若tcn模型的预测函数为f,特征集合为x,特征集合x中的第i个特征为xi,特征集合x中所有可能的特征子集的集合为m,则第i个样本在第j个特征的shap值φij可以计算为:
55、
56、其中,s为每个样本中任意多个特征形成的子集,∣s∣是集合s的大小,∣m∣是特征总数,f(s)为集合s中所包括的特征共同作用所产生的贡献,f(s∪{xi})-f(s)为特征xi为该共同作用带来的贡献;
57、(5.2)特征重要性排序。根据shap值对特征进行排序,以确定哪些特征对模型的预测结果有最大的影响,具体步骤如下:计算所有样本中每个特征i的shap值的总和shapi:
58、
59、其中,n是样本数量;然后对shap值的总和进行从高到低排序,以确定特征的重要性。
60、本发明的技术构思是:首先涉及对生产业务流程的事件日志进行预处理,确保数据的质量和一致性。随后,从清洗后的数据中提取关键特征,这些特征能够反映生产流程的关键属性和模式。接着构建并训练一个时间卷积网络(temporal convolutional network,tcn)模型,该模型专门设计用于分析时间序列数据,并能准确预测生产业务流程的剩余执行时间,通过判断tcn模型的预测结果是否超过预设的超时阈值,可以及时识别潜在的延迟风险。进一步,为了提高tcn模型的可解释性,本发明采用了shap值分析,一种基于博弈论的解释方法,用以确定各特征对预测结果的具体贡献度。最终,本发明通过构建shap概要图将复杂的预测结果和特征贡献以可视化的方式展现出来,使得业务专家能够直观理解模型的预测逻辑,从而提高模型的可信度和决策支持的有效性。
61、本发明的优点是:
62、(1)利用时间卷积网络(tcn)对生产业务流程的事件日志数据进行深入分析,能够捕捉生产业务流程中的细微模式和长期依赖性,从而提供精确的剩余执行时间预测;
63、(2)通过shap值分析来解释tcn模型的预测结果,使业务专家能够理解各个特征如何影响最终的预测,增加了模型的可信度;
64、(3)通过shap概要图提供一种直观的方式来展示不同特征对tcn预测结果的重要性,使得非技术用户也能轻松理解模型的预测逻辑。
- 还没有人留言评论。精彩留言会获得点赞!