一种基于Transformer多模态融合策略的行人意图预测方法
本发明涉及基于transformer的行人穿行意图预测领域,通过transformer和多模态融合技术来解决推荐相关的问题。
背景技术:
1、在日常生活中,汽车是不可缺少的交通工具之一,并且随着科学技术的不断发展,自动驾驶技术、自动驾驶汽车也逐渐出现在大众视野中,那么保证交通场景中道路使用者的自身安全是自动驾驶车辆被普及应用的前提条件。
2、准确预测行人行为不仅可以预防潜在的碰撞,确保安全,还能优化路线规划和车速调整,缓解交通拥堵。在汽车行驶过程中,当路旁的行人打算穿越马路到达对面时,他们会展示出一系列行为特征。例如,他们可能会暂停行走,转过身来观察过往的车辆,等待车辆远离或出现安全的穿越机会。在确认安全之后,行人可能会开始行走,甚至做出加速穿越的动作。
3、常见的行人轨迹模型是基于循环神经网络(rnn)的模型。这种模型通常会以行人的历史位置信息作为输入,然后通过rnn网络学习行人的运动模式,并预测行人的未来位置。而在自动驾驶汽车中的行人意图识别技术中,大量的研究都聚焦于lstm、gru等的模型。例如pcpa、sf-gru、ipvo-lstm和social lstm,其中pcpa通过利用lstm编码器-解码器架构,通过分析当前和历史的边界框数据来预测行人的未来行为;sf-gru通过堆叠gru处理不同模态来预测行人穿行。
4、尽管传统的基于rnn的模型在序列数据处理方面表现出色,但它们存在梯度消失或爆炸的问题,且难以并行处理数据,限制了计算效率。lstm模型在行人轨迹预测中也存在一些挑战。例如,对于输入数据的微小变化,lstm模型可能表现出敏感性,这可能导致其在具有挑战性的环境中的预测性能下降。此外,lstm模型可能需要大量的计算资源和时间来训练和推理,这可能限制了其在一些实时应用中的使用。
5、自从2017年transformer模型诞生以来,研究者们基于其推出了大量衍生研究。相比于循环神经网络(rnn)模型,transformer模型在处理序列数据时具有不少的优势,强大的并行计算能力,采用了自注意力机制,可以在不依赖于序列顺序的情况下对输入进行并行处理。更好的全局信息捕捉,由于transformer模型的自注意力机制可以捕捉到输入序列中的长距离依赖关系,因此可以更好地捕捉全局信息。还有更高的建模能力和更容易的优化和调参等优势。将transformer模型运用到行人穿行意图识别中,提高对多种模态的注意力计算,使其更加接近人类驾驶员对行人意图的判断。因此也开始有研究开始研究基于transformer的行人穿行意图预测方法,就有如pit和intformer。
技术实现思路
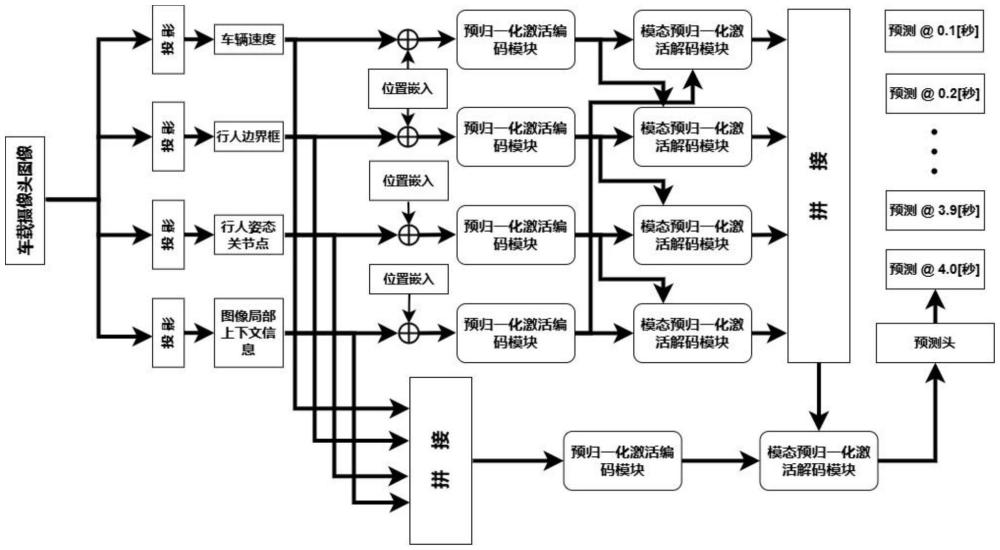
1、本发明针对现有解决方案的局限性和挑战,提出一种基于transformer多模态融合策略的行人意图预测方法,通过引入了前置归一化技术和在注意力层后额外的激活函数来改进transformer模型,处理和融合不同的数据模态,旨在提供一种全面且鲁棒的行人行为理解方式。前置归一化激活编码模块对每个模态的输入信息进行预处理和编码,模态前置归一化激活解码模块则进一步处理模态信息,学习模态间的关联性。采用了一种与传统transformer模型不同的前置归一化方法,在行人意图预测任务上,有助于稳定训练过程,并提高模型的泛化能力。在前向反馈网络(feed forward network,ffn)层之前加入了额外激活函数,捕捉到更复杂的特征和模式,改善了梯度流动。
2、本发明的一种基于transformer多模态融合策略的行人意图预测方法,包含以下步骤:
3、s1:前置归一化激活编码模块
4、s2:模态前置归一化激活解码模块
5、s3:行人穿行意图预测模块
6、s4:模型训练
7、进一步地,所述s1的具体步骤为:
8、s11、transformer模型输入的向量维度为一维,因此将得到不同模态的数据投影到一维向量空间,降维并提取特征,然后结合位置嵌入(positional embedding)来保留时间序列信息:
9、xm,p=xm+p
10、其中,m为不同模态,例如行人姿态、行人边界框,p为位置嵌入;
11、s12、通过s11得到的进行了位置嵌入的不同模态向量,先经过层归一化,在通道维度上对神经元的输出进行归一化处理,使得同一层中的激活值具有相同的分布,在进行残差连接后通过注意力机制捕捉序列间的依赖,关注输入数据的特定部分,动态地关注输入的不同部分,从而增强了模态本身之间的关联性:
12、z′m,e=attention(layernorm(xm,p)+xm,p)
13、其中,attentention()为注意力机制,layernorm()为层归一化;
14、s13、完成注意力机制的处理后,数据再次通过一个层归一化(layernorm)层,以调整和稳定随后的网络层输入;随后,数据进入一个激活和添加(activation&add)模块,这里可能涉及非线性激活函数,为模型引入非线性特性,并通过残差连接(add)将输出加回到前一层的输出上,以增强模型的学习能力:
15、z″m,e=layernorm(gelu(layernorm(z′m,e))+z′m,e)
16、其中,gelu()为非线性激活函数,高斯误差线性单元激活函数;
17、s14、最后,数据流经一个前馈网络(feed forward network,ffn)和另一个层归一化(layernorm)层;前馈网络包含多个全连接层,用于进一步提取特征和学习复杂的函数映射。最终,经过层归一化后的数据完成了该流程的一个完整周期,可以继续进入下一个周期或阶段的处理:
18、zm,e=layernorm(ffn(z″m,e)+z″m,e)
19、其中,ffn为前馈网络。
20、进一步地,所述s2的具体步骤为:
21、s21、每个模态经过前置归一化编码模块之后,得到了各模态对应的zm,e,将各个模态进行两两组合;
22、具体来说,首先两个模态zm,e分别同时通过的层归一化(layernorm)层,这一步有助于控制训练过程中的数值稳定性,并允许每层学习到合适的隐藏表示;接着,这两个归一化后的输入流通过一个交叉注意力(cross attention)模块;在交叉注意力机制中,一个输入流的元素作为查询(queries),而另一个输入流的元素作为键(keys)和值(values);这种机制允许模型在处理一个输入流时,能够关注另一个输入流中相关的信息;
23、
24、其中,crossattention()为交叉注意力机制;
25、s22、完成交叉注意力的处理后,得到的输出通过一个层归一化(layernorm)层,以进一步稳定网络的激活值;然后,数据进入一个激活和添加(activation&add)模块,这里可能包含一个非线性激活函数,为网络提供非线性变换的能力;残差连接(add)将当前层的输出与其输入相加,这样可以帮助梯度流动并减少训练过程中的消失问题:
26、z″m,d=layernorm(gelu(layernorm(z′m,d))+z′m,d)
27、s23、最后,数据通过一个前馈网络(feedforwardnetwork,ffn)和另一个层归一化(layernorm)层;前馈网络通常由密集层组成,用于提取更高层次的特征表示:
28、zm,d=layernorm(ffn(z″m,d)+z″m,d)。
29、进一步地,所述s3的具体步骤为:
30、s31、在模态前置归一化激活解码模块得到各模态的zm,d,将所有模态的zm,d进行拼接(concatenate)起来后,得到zd:
31、
32、其中,concate[……]为拼接向量操作;
33、然后,将每个模态进行投影(project)成一维向量后的xm也进行concatenate,并且将其输入到前置归一化激活解码模块之后得到zq:
34、z′q,e=attention(layernorm(xm)+xm)
35、z″q,e=layernorm(gelu(layernorm(z′q,e))+z′q,e)
36、zq=layernorm(ffn(z″q,e)+z″q,e)
37、s32、得到zq和zd之后输入到模态前置归一化激活解码模块中,得到zc:
38、z′c=crossattention(layernorm(zq)+zq,layernorm(zd)+zd)
39、z″c=layernorm(gelu(layernorm(z′c))+z′c)
40、zc=layernorm(ffn(z′c)+z′c)
41、随后将zc输入到预测模块中进行处理;在预测模块中,将zc输入到多层感知机(multilayerperceptron),并且通过sigmoid函数激活:
42、zc=mpnad(zq,zd)
43、
44、其中,mpnad为模态前置归一化激活解码模块,sigmoid()为激活函数,为预测结果。
45、进一步地,所述s4的具体步骤为:
46、s41、在行人穿行意图预测任务中,面临的是一个典型的二分类问题,即判断行人是否打算穿行;采用了交叉熵损失函数(cross-entropy loss)来量化模型预测与实际标签之间的差异;具体来说,对于每个类别,模型预测的概率为pt,对应于不穿行的概率为1-pt,交叉熵损失的计算公式如下:
47、
48、其中lce为交叉熵损失,yt为实际标签,当行人穿行时yt=1,否则yt=0;
49、为了进一步提升预测的准确性,使用了辅助损失函数lr旨在缩小模型在模态前置归一化激活模块中输出zd[t]与最终预测输出zd[t]之间的差距,表达式为:
50、
51、这种辅助损失有助于确保模型的预测在最终决策之前的一系列输出中保持一致性和稳定性;最终得到:
52、l=lce+lr
53、其中,lr为辅助函数,l为总损失;
54、这种损失策略鼓励模型在早期预测时就能从解码器的最后表示中受益,从而在行人动作发生前能够观察到整个序列的上下文信息,增强了模型对行人穿行意图的整体理解和预测能力。
- 还没有人留言评论。精彩留言会获得点赞!