多租户无服务器平台资源管理方法及系统与流程
本发明涉及数据处理技术,尤其涉及一种多租户无服务器平台资源管理方法及系统。
背景技术:
1、随着云计算技术的发展,无服务器计算(serverless computing)作为一种新兴的云计算模式,正在受到越来越多的关注。无服务器计算允许用户专注于应用程序的开发,而无需关注底层基础设施的管理和维护。在无服务器平台中,函数即服务(function-as-a-service, faas)是最主要的服务形式,用户以函数为单位编写和部署应用程序,平台根据函数的实际执行情况自动进行资源分配和伸缩。然而,现有的无服务器平台在多租户环境下的资源管理方面仍然存在一些挑战。首先,多个租户共享无服务器平台的计算资源,需要确保不同租户之间的资源隔离,防止互相干扰。同时,要公平合理地分配资源,避免某些租户占用过多资源而影响其他租户的服务质量。其次无服务器平台需要根据函数的实际执行情况,动态调整资源分配。当函数请求增加时,要及时扩容资源以满足性能需求;当函数请求减少时,要及时缩容资源以节约成本。然而,准确预测资源需求并及时调整资源分配仍然是一个挑战。并且无服务器平台通常采用按需启动的方式,在函数首次被调用或闲置一段时间后再次被调用时,需要重新启动运行环境,导致较长的启动延迟,即冷启动问题。如何最小化冷启动对函数执行性能的影响,是当前无服务器平台面临的一个挑战。
2、现有的无服务器平台,如aws lambda、google cloud functions等,虽然在自动伸缩和按需计费方面取得了一定进展,但在多租户环境下的资源隔离与公平性、动态伸缩的精准性、冷启动优化、成本优化以及异构资源管理等方面,仍有较大的改进空间。因此,亟需一种新的多租户无服务器平台资源管理方法,以解决上述问题,提高平台的性能、效率和用户体验。
技术实现思路
1、本发明实施例提供一种多租户无服务器平台资源管理方法及系统,能够解决现有技术中的问题。
2、本发明实施例的第一方面,
3、提供一种多租户无服务器平台资源管理方法,包括:
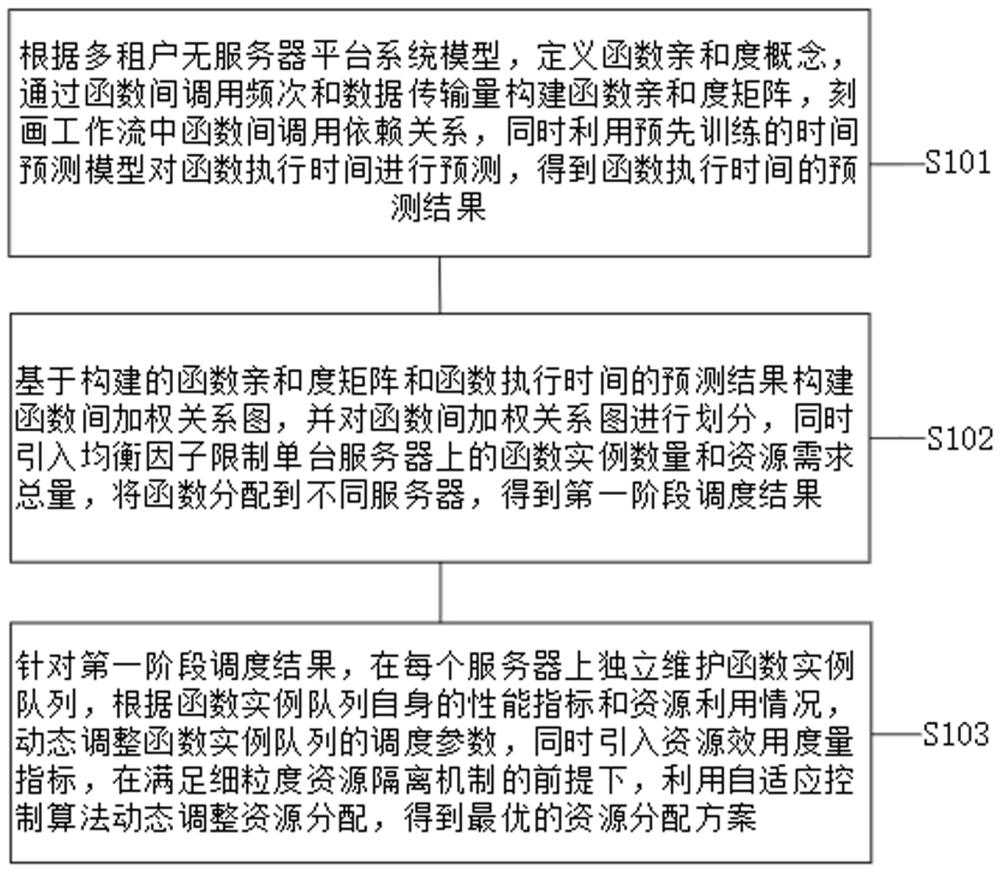
4、根据多租户无服务器平台系统模型,定义函数亲和度概念,通过函数间调用频次和数据传输量构建函数亲和度矩阵,刻画工作流中函数间调用依赖关系,同时利用预先训练的时间预测模型对函数执行时间进行预测,得到函数执行时间的预测结果;
5、基于构建的函数亲和度矩阵和函数执行时间的预测结果构建函数间加权关系图,并对函数间加权关系图进行划分,同时引入均衡因子限制单台服务器上的函数实例数量和资源需求总量,将函数分配到不同服务器,得到第一阶段调度结果;
6、针对第一阶段调度结果,在每个服务器上独立维护函数实例队列,根据函数实例队列自身的性能指标和资源利用情况,动态调整函数实例队列的调度参数,同时引入资源效用度量指标,在满足细粒度资源隔离机制的前提下,利用自适应控制算法动态调整资源分配,得到最优的资源分配方案。
7、在一种可选的实施例中,
8、利用预先训练的时间预测模型对函数执行时间进行预测,得到函数执行时间的预测结果之后还包括:
9、在函数执行过程中,实时记录函数实际执行时间,与函数执行时间的预测结果进行比较,计算预测误差数据;
10、根据预测误差数据进行预测偏差分析,识别出预测误差大、波动频繁的函数类型和执行模式,输出预测偏差分析结果;
11、根据预测偏差分析结果,使用在线学习算法动态调整时间预测模型的参数,针对不同函数类型和执行模式,设计多种预测纠正策略,根据函数特点和系统状态,自适应选择最优纠正策略。
12、在一种可选的实施例中,
13、对函数间加权关系图进行划分包括:
14、将函数间加权关系图的划分过程划分为负载均衡优化阶段、通信优化阶段和关键路径优化阶段;
15、在所述负载均衡优化阶段,构建均衡偏差的二次型目标函数,引入均衡容忍度约束子图规模上限,采用启发式算法求解负载均衡划分方案,得到初步的均衡划分结果;
16、将得到的初步的均衡划分结果作为通信优化阶段的初始解,在所述通信优化阶段,构建基于图割的通信代价目标函数,引入延迟容忍度约束关键路径长度,利用局部搜索算法在保持负载均衡前提下对初始解进行优化,降低通信代价,得到低通信划分结果;
17、基于得到的低通信划分结果,在所述关键路径优化阶段,提取关键路径长度作为优化目标,集合负载均衡和通信代价约束,利用关键路径调度算法对低通信划分结果进行调整,得到关键路径优化划分结果;
18、将关键路径优化划分结果作为下一轮负载均衡优化的输入,重复执行划分结果优化步骤,直至满足预设的收敛条件,输出最终的函数间加权关系图划分结果。
19、在一种可选的实施例中,
20、动态调整函数实例队列的调度参数包括:
21、将函数实例队列的性能指标、资源利用情况以及当前的调度参数值作为强化学习的状态空间,将所有可调节的调度参数的取值范围划分为离散的等级,形成强化学习的动作空间;
22、根据调度参数动态调整的多目标,构建多目标奖励函数,所述多目标奖励函数可以包括降低平均响应时间、提高吞吐量、降低错误率;
23、基于所设计的状态空间、动作空间和奖励函数,采用深度强化学习模型对调度参数的动态调整问题进行建模,并通过策略梯度算法更新深度强化学习模型的参数,利用更新后的深度强化学习模型,输出最终的目标调度参数调整策略,利用目标调度参数调整策略动态调整函数实例队列的调度参数。
24、在一种可选的实施例中,
25、通过策略梯度算法更新深度强化学习模型的参数的计算公式如下:
26、;
27、其中,θ*表示更新后的策略参数,θ表示策略参数,α表示学习率,n表示采样轨迹数,i表示采样轨迹索引,t表示采用轨迹长度,t表示当前时间步,表示对θ的梯度操作,π(·)表示条件概率分布,at表示动作,st表示当前状态,t'表示当前时间步的下一个时间步,γ表示折扣因子,r(·)表示奖励,st'表示在当前时间步的下一个时间步时所处的状态,at'表示在当前时间步的下一个时间步时所处的状态对应的动作。
28、在一种可选的实施例中,
29、利用自适应控制算法动态调整资源分配,得到最优的资源分配方案包括:
30、采集系统的资源利用率数据,所述资源利用率数据包括cpu利用率、内存利用率和磁盘i/o利用率;
31、对采集到的资源利用率数据进行预处理和特征提取,得到标准利用率数据,将标准利用率数据输入至预先训练的资源预测模型中,得到预设时间内资源利用率的预测结果;
32、采用异常检测算法对资源利用率数据进行实时分析,当检测到异常情况时,触发资源分配的动态调整,并根据分析结果与预设的异常阈值进行比较,得到资源分配的异常信息;
33、基于预设时间内资源利用率的预测结果和资源分配的异常信息构建目标函数,通过最小化目标函数,生成最优的资源分配方案。
34、在一种可选的实施例中,
35、所述目标函数的计算公式如下:
36、;
37、其中,j表示目标函数,λ1表示资源利用率预测结果的权重系数,m表示样本数,i表示样本索引,yi表示实际资源利用率数据,表示预测结果,λ2表示异常信息的权重系数,x表示资源利用率,μ表示数据集的平均值,σ表示数据集的标准差。
38、本发明实施例的第二方面,
39、提供一种多租户无服务器平台资源管理系统,包括:
40、第一单元,用于根据多租户无服务器平台系统模型,定义函数亲和度概念,通过函数间调用频次和数据传输量构建函数亲和度矩阵,刻画工作流中函数间调用依赖关系,同时利用预先训练的时间预测模型对函数执行时间进行预测,得到函数执行时间的预测结果;
41、第二单元,用于基于构建的函数亲和度矩阵和函数执行时间的预测结果构建函数间加权关系图,并对函数间加权关系图进行划分,同时引入均衡因子限制单台服务器上的函数实例数量和资源需求总量,将函数分配到不同服务器,得到第一阶段调度结果;
42、第三单元,用于针对第一阶段调度结果,在每个服务器上独立维护函数实例队列,根据函数实例队列自身的性能指标和资源利用情况,动态调整函数实例队列的调度参数,同时引入资源效用度量指标,在满足细粒度资源隔离机制的前提下,利用自适应控制算法动态调整资源分配,得到最优的资源分配方案。
43、本发明实施例的第三方面,
44、提供一种电子设备,包括:
45、处理器;
46、用于存储处理器可执行指令的存储器;
47、其中,所述处理器被配置为调用所述存储器存储的指令,以执行前述所述的方法。
48、本发明实施例的第四方面,
49、提供一种计算机可读存储介质,其上存储有计算机程序指令,所述计算机程序指令被处理器执行时实现前述所述的方法。
50、在本实施例中,通过构建函数亲和度矩阵,能够准确地刻画工作流中函数之间的调用依赖关系,为函数调度提供重要的依据。通过利用预先训练的时间预测模型对函数执行时间进行预测,能够更好地评估函数执行的时间开销,为资源分配提供参考。基于函数亲和度矩阵和函数执行时间预测结果,构建加权关系图,并采用贪心算法进行函数划分,可以将高亲和度的函数尽可能分配到同一台服务器上,减少跨服务器通信开销。通过引入均衡因子限制单台服务器上的函数实例数量和资源需求总量,可以避免个别服务器过度负载,提高整体资源利用效率。在每个服务器上独立维护函数实例队列,根据队列的性能指标和资源利用情况动态调整调度参数,可以实现更加灵活的调度策略,提高资源利用率。通过引入资源效用度量指标,并利用自适应控制算法动态调整资源分配,可以实现细粒度资源隔离和高效利用,提高系统的整体性能和资源利用效率,能够为无服务器平台的资源调度和管理提供全面的解决方案。
- 还没有人留言评论。精彩留言会获得点赞!