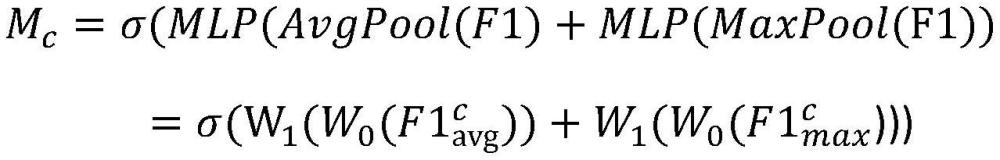
本发明涉及图像处理,特别是涉及一种基于自适应多尺度特征融合网络的图像分类识别方法。
背景技术:
1、图像分类是根据图像的语义信息对不同类别图像进行区分,是计算机视觉的核心,是物体检测、图像分割、物体跟踪、行为分析、人脸识别等其他高层次视觉任务的基础。图像分类在许多领域都有着广泛的应用,如:安防领域的人脸识别和智能视频分析等,交通领域的交通场景识别,互联网领域基于内容的图像检索和相册自动归类,医学领域的图像识别等。
2、在本世纪的早期,虽然神经网络开始有复苏的迹象,但是受限于数据集的规模和硬件的发展,神经网络的训练和优化仍然是非常困难的。mnist和cifar数据集都只有60000张图,这对于10分类这样的简单的任务来说,或许足够,但是如果想在工业界落地更加复杂的图像分类任务,仍然是远远不够的。
3、后来在李飞飞等人数年时间的整理下,2009年,imagenet数据集发布了,并且从2010年开始每年举办一次imagenet大规模视觉识别挑战赛,即ilsvrc。imagenet数据集总共有1400多万幅图片,涵盖2万多个类别,在论文方法的比较中常用的是1000类的基准。
4、在imagenet发布的早年里,仍然是以svm和boost为代表的分类方法占据优势,直到2012年alexnet的出现。alexnet是第一个真正意义上的深度网络,与lenet5的5层相比,它的层数增加了3层,网络的参数量也大大增加,输入也从28变成了224,同时gpu的面世,也使得深度学习从此进行gpu为王的训练时代。
5、在此之后不断有各种优秀的网络出现,例如vgg,resnet等优秀的网络,到后面的convnext等等不断刷新imagenet的记录,图像分类的准确度从以前的不到50%迅速发展至接近90%准确度的高精度。
6、现有技术缺点:目前的图像分类识别方法对于多尺度特征提取能力不强,无法精准获取多层次、多尺度的图像特征,进而导致在复杂图像分类识别任务中,分类准确性不足。
技术实现思路
1、本发明提供的一种基于自适应多尺度特征融合网络的图像分类识别方法,提高了图像分类识别的准确性和可靠性。
2、为达到上述目的,本发明提供的一种基于自适应多尺度特征融合网络的图像分类识别方法,其关键是,包括以下步骤:
3、步骤1:图像获取模块获取图像数据a,并传递给自适应多尺度特征融合网络;
4、步骤2:所述自适应多尺度特征融合网络中的特征提取模块对所述图像数据a进行特征提取操作,得到特征数据b,并传递给特征融合模块;
5、步骤3:所述特征融合模块对所述特征数据b进行特征融合操作,得到融合数据c,并传递给分类模块;
6、步骤4:所述分类模块对所述融合数据c进行分类识别,得到分类结果。
7、通过上述设计,所述特征提取模块基于各类图像数据的主要特征,通过四个自适应多分支注意力模块ama对图像数据进行四尺度变换,用于获得四种不同尺度的特征图,以捕获图像数据从粗到细的不同粒度水平特征。随着特征图的维数逐渐减少,提取的特征信息从低到高逐渐丰富,从而捕获图像的多层次和多尺度信息。这种多层次、多尺度特征的获取,使得自适应多尺度特征融合网络能够更好地理解图像中复杂的细节和整体背景,为后续的特征融合和分类步骤奠定坚实的基础。
8、所述特征融合模块通过动态权重实现高、低层信息的快速双向融合。对于不规则图像数据,多尺度特征融合能够整合这种复杂的特征,进而提高模型性能和分类精度。
9、作为优选:在所述步骤2中,所述特征提取模块设置有四个自适应多分支注意力模块ama,四个所述自适应多分支注意力模块ama结构一致,首尾依次连接;
10、所述特征提取模块对所述图像数据a进行特征提取,具体步骤如下:
11、步骤21:所述特征提取模块中的第一ama1获取所述图像数据a,并对所述图像数据a进行特征提取,得到第一特征数据a1,并传递给第二ama2和第一1×1卷积层;
12、步骤22:所述第二ama2对所述第一特征数据a1进行特征提取,得到第二特征数据a2,并传递给第三ama3和第二1×1卷积层;
13、步骤23:所述第三ama3对所述第二特征数据a2进行特征提取,得到第三特征数据a3,并传递给第四ama4和第三1×1卷积层;
14、步骤24:所述第四ama4对所述第三特征数据a3进行特征提取,得到第四特征数据a4,并传递给第四1×1卷积层;
15、步骤25:所述第一1×1卷积层对第一特征数据a1进行一维卷积操作,得到第一卷积数据b1,并传递给特征融合模块;
16、所述第二1×1卷积层对第二特征数据a2进行一维卷积操作,得到第二卷积数据b2,并传递给特征融合模块;
17、所述第三1×1卷积层对第三特征数据a3进行一维卷积操作,得到第三卷积数据b3,并传递给特征融合模块;
18、所述第四1×1卷积层对第三特征数据a3进行一维卷积操作,得到第四卷积数据b4,并传递给特征融合模块。
19、作为优选:在所述步骤21中,所述第一ama1对所述图像数据a进行特征提取,具体步骤如下:
20、步骤211:所述第一ama1中的深度可分离层获取所述图像数据a,并对所述图像数据a进行深度分离,得到深度分离数据x1,并传递给第一批归一化层;
21、步骤212:所述第一批归一化层对所述深度分离数据x1进行批归一化处理,得到第一批归一化数据x2,并传递给卷积注意力机制cbam、全局上下文注意力机制gc和第五1×1卷积层;
22、步骤213a:所述卷积注意力机制cbam对所述第一批归一化数据x2进行卷积注意力调整后,得到卷积注意力数据x3,并传递给第二批归一化层;
23、步骤213b:所述全局上下文注意力机制gc对所述第一批归一化数据x2进行全局上下文注意力调整后,得到全局注意力数据x4,并传递给第三批归一化层;
24、步骤213c:所述第五1×1卷积层对所述第一批归一化数据x2进行一维卷积操作,得到第五卷积数据x5,并传递给第四批归一化层;
25、步骤214a:所述第二批归一化层对所述卷积注意力数据x3进行批归一化处理,然后经线性整流函数relu激活,得到第一激活数据y1,并传递给融合模块;
26、步骤214b:所述第三批归一化层对所述全局注意力数据x4进行批归一化处理,然后经线性整流函数relu激活,得到第二激活数据y2,并传递给融合模块;
27、步骤214c:所述第四批归一化层对所述第五卷积数据x5进行批归一化处理,然后经层归一化函数relu激活,得到第三激活数据y3,并传递给融合模块;
28、步骤215:所述融合模块对所述第一激活数据y1、第二激活数据y2和第三激活数据y3进行融合处理,得到第一特征数据a1。
29、通过上述设计,在每个自适应多分支注意力模块ama中,首先使用内核大小为3×3的深度可分离层和批归一化层,生成维度为输入特征映射一半的特征映射。该降维策略旨在实现多尺度特征提取,从而为图像分类识别任务提供更丰富的信息。随后,将生成的特征映射分别馈送到三个不同的分支中。
30、为了同时从通道和空间维度提取特征,在第一个分支中引入了卷积注意力机制cbam;第二个分支采用全局上下文注意力机制gc,将网络集中在图像的整体结构和上下文语义信息上;在第三个分支中引入了1×1卷积,1×1卷积的使用通过引入额外的非线性变换增强了网络表示复杂特征的能力。最后,将三个分支得到的特征映射进行融合。融合权值是动态可训练的参数,便于自适应调整,进一步提高特征融合的有效性。经过四个ama的处理后,网络获得高级抽象特征,并保留来自较低层的相对原始信息。
31、作为优选:在所述步骤213a中,所述卷积注意力机制cbam设置有通道注意力机制和空间注意力机制,所述卷积注意力机制cbam进行卷积注意力调整过程如下:
32、所述通道注意力机制将所述第一批归一化数据x2和通道注意力图mc相乘,得到通道注意力数据m;所述空间注意力机制将所述通道注意力数据与空间注意力图ms相乘,得到所述卷积注意力数据x3。
33、卷积注意力机制cbam的基本概念是结合通道注意力和空间注意力机制,确保网络能够在通道和空间维度上关注关键特征。这样的设计旨在消除冗余信息和噪声,增强图像特征的表示能力。
34、作为优选:所述通道注意力图mc经以下步骤得到:
35、步骤a1a:所述通道注意力机制中的第一最大池化层对所述第一批归一化数据x2进行最大池化操作,得到第一最大池化数据c1,并传递给多层感知机;
36、步骤a1b:所述通道注意力机制中的第一平均池化层对所述第一批归一化数据x2进行平均池化操作,得到第一平均池化数据c2,并传递给多层感知机;
37、步骤a2:所述多层感知机对所述第一最大池化数据c1和第一平均池化数据c2进行多层感知,得到感知数据c3,并传递给第二最大池化层和第二平均池化层;
38、步骤a3a:所述第二最大池化层对所述感知数据c3进行最大池化操作,得到第二最大池化数据c4,并传递给第一逐元素相加单元;
39、步骤a3b:所述第二平均池化层对所述感知数据c3进行平均池化操作,得到第二平均池化数据c5,并传递给第一逐元素相加单元;
40、步骤a4:所述第一逐元素相加单元将所述第二最大池化数据c4和第二平均池化数据c5进行逐元素相加,然后经sigmod函数进行激活,得到通道注意力图mc。
41、所述通道注意力图mc的计算方程表达式如下:
42、
43、其中,σ表示sigmoid函数,w0和w1表示多层感知机的权重,mlp表示多层感知机,avgpool表示平均池化,maxpool表示最大池化;f1表示输入特征,即第一批归一化数据x2;和表示通道信息。
44、作为优选:所述空间注意力图ms经以下步骤得到:
45、步骤b1:所述空间注意力机制中的第三最大池化层对所述通道注意力图mc进行最大池化操作,得到第三最大池化数据s1,并传递给第三平均池化层;
46、步骤b2:所述第三平均池化层对所述通道注意力图mc进行平均池化操作,得到第三平均池化数据s2,并传递给卷积层;
47、步骤b3:所述卷积层对所述第三平均池化数据s2进行卷积操作,得到卷积数据s3,并传递给第四最大池化层;
48、步骤b4:所述第四最大池化层对所述卷积数据s3进行最大池化操作,得到第四最大池化数据s4,并传递给第四平均池化层;
49、步骤b5:所述第四平均池化层对所述第四最大池化数据s4进行平均池化操作,然后经sigmod函数进行激活,得到空间注意力图ms。
50、所述空间注意力图ms的计算方程表达式如下:
51、
52、其中,f7×7表示滤波器大小为7×7的卷积操作,和表示空间信息。
53、作为优选:在所述步骤213b中,所述全局上下文注意力机制gc设置有上下文建模模块和转换模块,所述全局上下文注意力机制gc进行全局上下文注意力调整,具体步骤如下:
54、步骤c1:所述上下文建模模块中的第六1×1卷积层对所述第一批归一化数据x2进行卷积操作,然后经sigmod函数进行激活,得到第四激活数据d1,再将所述第四激活数据d1和第一批归一化数据x2进行逐元素相乘,得到建模数据d2,并传递给转换模块;
55、步骤c2:所述转换模块中的第七1×1卷积层对所述建模数据d2进行卷积操作,然后经层归一化函数relu激活,再将激活后数据经第八1×1卷积层进行卷积操作,得到转换数据d3,并传递给第二逐元素相加单元;
56、步骤c3:所述第二逐元素相加单元将所述第一批归一化数据x2和转换数据d3进行逐元素相加,得到全局注意力数据x4。
57、全局上下文注意力机制gc从全局角度进行操作,旨在增强神经网络对图像特征的抽象理解,减轻全局信息的损失,侧重于捕获图像的全局结构和上下文语义特征。
58、在上下文建模模块中,对原始特征q即第一批归一化数据x2进行卷积操作,然后进行softmax操作,生成全局概率分布k即第四激活数据d1,描述图像中每个位置对gc的重要性,有效地呈现了每个位置的上下文权重,有助于网络更好地理解图像中的关键位置,以确定图像种类。然后,将得到的概率权重按元素乘以原始特征映射。该操作生成一个具有上下文权重的特征,在每个位置引入gc的影响。通过这一步,模型强调了每个位置与全局信息之间的关系,从而更好地捕获图像内不同位置之间的语义联系。
59、在转换模块中,卷积和层归一化操作应用于上下文加权的特征,从而产生包含gc信息的特征映射v即转换数据d3。这种归一化提高了模型的收敛速度和泛化能力。最后,将v中的全局信息与原始特征q结合,得到包含gc影响的输出特征即全局注意力数据x4。有助于网络更好地了解不同种类图像数据的有效特征。
60、所述全局上下文注意力机制gc通过生成全局概率分布、引入gc关注和特征归一化,为神经网络注入了更丰富的全局语义信息,有效提高了模型的性能。全局上下文注意力机制gc的具体建模过程如下:
61、k=s(resize(f1×1(q)))
62、
63、mo=q+v
64、其中,q表示gc模块的输入特征图,即第一批归一化数据x2;mo表示gc模块的输出特征图,即全局注意力数据x4;resize(·)表示形状变换操作,s(·)表示softmax函数,g(·)表示层归一化和relu函数,表示逐元素相乘,f1×1表示滤波器大小为1×1的卷积操作。
65、作为优选:在所述步骤3中,所述特征融合模块中设置有第一特征融合层、第二特征融合层、第三特征融合层和第四特征融合层,其中,第一特征融合层设置有第一获取单元和第一融合单元,所述第二特征融合层设置有第二获取单元、第二融合单元和第三融合单元,所述第三特征融合层设置有第三获取单元、第四融合单元和第五融合单元,所述第四特征融合层设置有第四获取单元、第六融合单元;
66、所述特征融合模块进行特征融合操作,具体步骤如下:
67、步骤31:所述第一获取单元获取第一卷积数据b1,并传递给第一融合单元;
68、所述第二获取单元获取第二卷积数据b2,并传递给第二融合单元和第三融合单元;
69、所述第三获取单元获取第三卷积数据b3,并传递给第四融合单元和第五融合单元;
70、所述第四获取单元获取第四卷积数据b4,并传递给第四融合单元和第六融合单元;
71、步骤32:所述第四融合单元将所述第三卷积数据b3和第四卷积数据b4进行特征融合,得到第四融合数据f4,并传递给第二融合单元和第五融合单元;
72、所述第二融合单元将所述第二卷积数据b2和第四融合数据f4进行特征融合,得到第二融合数据f2,并传递给第一融合单元和第三融合单元;
73、步骤33:所述第一融合单元将所述第一卷积数据b1和第二融合数据f2进行特征融合,得到第一融合数据f1,并传递给第三融合单元和第三逐元素相加单元;
74、所述第三融合单元将所述第二卷积数据b2、第一融合数据f1和第二融合数据f2进行特征融合,得到第三融合数据f3,并传递给第五融合单元和第三逐元素相加单元;
75、所述第五融合单元将所述第三卷积数据b3、第四融合数据f4和第三融合数据f3进行特征融合,得到第五融合数据f5,并传递给第六融合单元和第三逐元素相加单元;
76、所述第六融合单元将所述第四卷积数据b4和第五融合数据f5进行特征融合,得到第六融合数据f6,并传递给第三逐元素相加单元;
77、步骤34:所述第三逐元素相加单元将所述第一融合数据f1、第三融合数据f3、第五融合数据f5和第六融合数据f6进行逐元素相加,得到融合数据c。
78、通过上述设计,所述特征融合模块采用加权双向特征金字塔网络bifpn来强不同分辨率特征之间的语义相关性,实现了自顶向下和自底向上的双向信息流,每条融合路径都配备了可训练的参数,可自动调整最优融合比例。对于来自特征提取模块的不同尺度的信息,本方法采用统一的上采样和下采样操作,以确保它们获得相同的特征分辨率。关于上采样,本方法选择了一个稳定和光滑的双线性插值方法,而下采样涉及最大池化。此外,在同一层的输入和输出节点之间,插入了跳跃连接,以减轻信息传播带来的退化和信息丢失。
79、作为优选:在所述步骤4中,所述分类模块设置有第一全连接层和第二全连接层;
80、所述第一全连接层、对所述融合数据c进行全连接操作,得到全连接数据并传递给第二全连接层;所述第二全连接层对所述全连接数据进行全连接操作,得到分类结果。
81、作为优选:所述分类结果为由0和1组成的1×q向量,该向量中每个向量位上的数,用于定义一种图像种类;
82、所述向量中仅有一个向量位上的数字为1,该向量位所对应的图像种类即为分类结果。
83、通过上述设计,实现了不同种类图像数据的分类识别,根据预测结果能够直观清晰的了解到所预测图像具体属于哪一图像种类。
84、在实际应用中,可以根据具体图像分类场景、设定相应的图像种类,然后对所述自适应多尺度特征融合网络进行相应的训练,即可实现相应图像数据的精准分类。例如当使用动物图像进行分类训练时,即可精准识别图像数据中的动物种类信息,如:猫、狗、马、羊、鱼等。
85、本发明的有益效果:在特征提取模块,分别在通道和空间维度上关注关键特征,有效消除冗余信息和噪声,增强图像特征的表示能力,实现了对ct图像多层次、多尺度特征的有效提取;在特征融合模块引入bifpn来融合多尺度特征,增强不同分辨率特征之间的语义相关性,提高了预测结果的准确性和可靠性。