基于NLP的不合格通知单智能归集方法、系统和设备与流程
本技术涉及智能制造的,尤其涉及基于nlp的不合格通知单智能归集方法、系统和设备。
背景技术:
1、复杂装备制造过程具有批量大、生产节拍快、工艺过程较为复杂等特点,大部分质量过程数据存储在制造执行系统中,其中包含大量非结构化数据,如不合格通知单。
2、针对该类型数据的利用,传统分析方法需要靠人工逐条判定。而通过人工逐条判定,需要消耗大量的人工成本,同时,由于复杂装备产品专业性较强,存在大量的专业术语,在进行,人工逐条判定时,对于相关人员的专业水平和经验要求也很高。因此,人工逐条判定存在效率低、准确性不高的情况,导致,产品排故进度慢,继而使得产品不能按照正常的生产节奏生产,影响产品准时交付。
技术实现思路
1、本技术的主要目的在于提供基于nlp的不合格通知单智能归集方法、系统和设备,旨在解决对不合格通知单进行人工逐条判定时,效率低、准确性不高的技术问题。
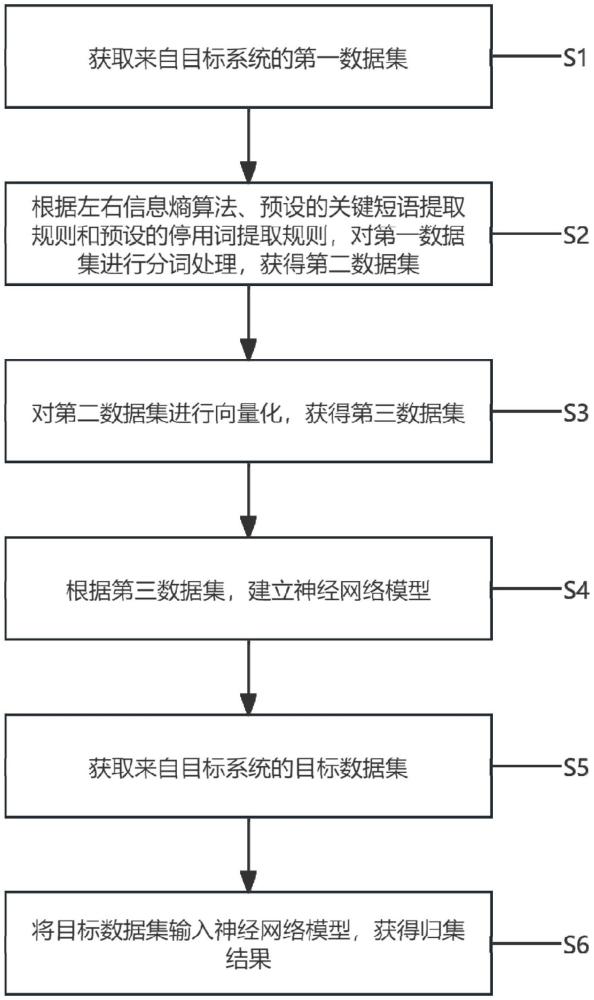
2、第一方面,为实现上述目的,本技术提供一种基于nlp的不合格通知单智能归集方法。
3、一种基于nlp的不合格通知单智能归集方法,包括以下步骤:
4、获取来自目标系统的第一数据集,其中,所述第一数据集被配置为包括已被归类为不合格通知单的第一通知单文本集合和所述通知单文本集合对应的第一归类集合;
5、根据所述左右信息熵算法、预设的关键短语提取规则和预设的停用词提取规则,对所述第一数据集进行分词处理,获得第二数据集,其中,所述第二数据集被配置为不合格通知单对应的关键短语的集合;
6、对所述第二数据集进行向量化,获得第三数据集;
7、根据所述第三数据集,建立神经网络模型并使用所述第三数据集对所述神经网络进行训练;
8、获取来自目标系统的目标数据集,其中,所述目标数据集被配置为待归类的通知单文本的集合;
9、将所述目标数据集输入所述神经网络模型,获得归集结果。
10、可选的,所述预设的分词算法包括左右信息熵算法、预设的关键短语提取规则和预设的停用词提取规则中的至少一项。
11、可选的,所述根据预设的分词算法,对所述第一数据集进行分词处理,获得第二数据集的步骤,包括:
12、根据所述左右信息熵算法、所述关键短语提取规则和所述停用词提取规则,提取所述第一数据集中的关键短语,建立专业术语数据集;
13、根据所述停用词提取规则,建立停用词数据集;
14、将所述专业术语数据集录入中文分词库中的专业术语词库,将所述停用词数据集录入中文分词库中的停用词词库;
15、调用所述中文分词库,对所述第一数据集进行分词,获得第二数据集。
16、可选的,所述根据所述左右信息熵算法、所述关键短语提取规则和所述停用词提取规则,提取所述第一数据集中的关键短语,建立专业术语数据集的步骤,包括:
17、根据预设的中文分词库和停用词提取规则,对所述第一数据集进行断句、分词和去除停用词,获得词语数据集;
18、对所述词语数据集的各词语进行续接,获得续接词数据集;
19、统计所述词语数据集中各词语共现情况,以及,统计所述续接词数据集中各词语串的共现情况,获得共现频次数据集;
20、根据所述词语数据集、所述续接词数据集和所述共现频次数据集,进行关键短语提取,获得专业术语数据集。
21、可选的,所述对所述词语数据集的各词语进行续接,获得续接词数据集的步骤,包括:
22、对所述词语数据集中的各词语进行左续接,获得二阶词语数据集;
23、对所述二阶词语数据集中的各二阶词语进行右续接,获得三阶词语数据集。
24、可选的,所述统计所述词语数据集中各词语共现情况,以及,统计所述续接词数据集中各词语串的共现情况,获得共现频次数据集的步骤,包括:
25、统计所述词语数据集中各词语的词频,或调用外部词频词典,获得各词语对应的第一共现频次;
26、统计所述二阶词语数据集中各二阶词语的词语串频次,获得各二阶词语对应的第二共现频次;
27、统计所述三阶词语数据集中各三阶词语的词语串频次,获得各三阶词语对应的第三共现频次;
28、根据所述第一共现频次、所述第二共现频次和所述第三共现频次,获得所述共现频次数据集。
29、可选的,所述根据所述词语数据集、所述续接词数据集和所述共现频次数据集,进行关键短语提取,获得专业术语数据集的步骤,包括:
30、根据所述第一共现频次、所述第二共现频次和所述二阶词语数据集,对所述二阶词语数据集中的各二阶词语进行互信息计算,获得各二阶词语对应的互信息值;
31、根据所述第一共现频次、所述第三共现频次和所述三阶词语数据集,对所述三阶词语数据集中的各三阶词语进行左边界信息熵计算和右边界信息熵计算,获得各三阶词语对应的左边界信息熵值和右边界信息熵值;
32、根据所述互信息值、所述左边界信息熵值和所述右边界信息熵值,获得度量集合,在所述度量集合中选取目标数量个度量值最高的词语作为关键短语;
33、根据所述关键短语和预设的术语对应关系,获得所述关键短语对应的术语简称并将所述关键短语和所述术语简称作为所述专业术语数据集。
34、可选的,所述对所述第二数据集进行向量化,获得第三数据集的步骤,包括:
35、获取所述第二数据集中各词语的tf词频和idf逆文档频率,对所述第二数据集进行tf-idf统计,获得第三数据集。
36、第二方面,本技术提供一种基于nlp的不合格通知单智能归集系统。
37、基于nlp的不合格通知单智能归集系统,包括:
38、第一工单获取模块,所述第一工单获取模块用于获取来自目标系统的第一数据集,其中,所述第一数据集被配置为包括已被归类为不合格通知单的第一通知单文本集合和所述通知单文本集合对应的第一归类集合;
39、分词模块,所述分词模块用于根据所述左右信息熵算法、预设的关键短语提取规则和预设的停用词提取规则,对所述第一数据集进行分词处理,获得第二数据集,其中,所述第二数据集被配置为不合格通知单对应的关键短语的集合;
40、数据向量化模块,所述数据向量化模块用于对所述第二数据集进行向量化,获得第三数据集;
41、第一归集模块,所述第一归集模块用于根据所述第三数据集,建立神经网络模型并使用所述第三数据集对所述神经网络进行训练;
42、第二工单获取模块,所述第二工单获取模块用于获取来自目标系统的目标数据集,其中,所述目标数据集被配置为待归类的通知单文本的集合;
43、第二归集模块,所述第二归集模块用于将所述目标数据集输入所述神经网络模型,获得归集结果。
44、第三方面,本技术提供一种电子设备,包括:处理器及存储器,其中,所述存储器用于存储计算机程序;所述处理器用于加载执行所述计算机程序,以使所述电子设备执行如第一方面中任一项所述的基于nlp的不合格通知单智能归集方法。
45、本技术所能实现的有益效果。
46、本技术实施例提出的一种基于nlp的不合格通知单智能归集方法,通过获取已被归类为不合格通知单的通知单文本,再使用左右信息熵算法获取其中的关键短语,将关键短语向量化后,作为原始数据建立神经网络模型,继而使用建立的神经网络模型对待归类的通知单文本进行自动归集。因此,本技术通过左右信息熵算法提取工单中的关键短语,提升了数据预处理结果质量,提高了神经网络模型对不合格工单的归集准确率。
- 还没有人留言评论。精彩留言会获得点赞!