基于视觉语言模型的青瓷跨模态知识图谱构建方法
本发明属于视觉处理、自然语言处理和知识图谱构建的交叉。该方法涉及视觉数据的分析与处理,包括青瓷的图像特征提取与分析,以及文本数据的语义分析和信息抽取。通过整合青瓷图像特征和文本特征,实现对青瓷器型、色彩以及纹理等信息的系统化表示与展示。
背景技术:
1、构建跨模态知识图谱的核心任务是实现文本知识图谱中的实体与相应图像之间的有效关联。现有研究主要聚焦于从图像到文本和从文本到图像两个方向。
2、从图像到文本的思路通常先识别和确定图像中的视觉元素,然后用图谱中的实体或概念标注这些元素。例如,结合yolov3(you only look once version 3)技术与图谱中的文本特征,可以实现甲骨文拓片图像中字符与现代汉字之间的匹配。然而,该方法依赖于图像数据的人工标注和专家校验,存在局限性。另一种方法是通过固定词汇表从互联网搜集图像,并利用图像中提取的视觉知识增强预训练检测器和分类器的语义理解能力,代表性技术是neil(never ending image learner),这大大减少了人工标注的成本。但是,该方法搜集的图像可能包含噪声,容易对模型性能产生不利影响。还有一种字幕指导的视觉显著性方法,通过将字幕中的词汇或短语映射到静态图像的相关区域,并生成相应的显著性图,从而获得视觉对象及对应的文本标签。然而,显著性方法对输入敏感,难以产生稳定可靠的结果。此外,通过在共享的多模态子空间内,基于注意力机制,将图像和文本特征连接起来,但由于图像和文本的语义尺度不一致,容易导致不准确的匹配。
3、从文本到图像的思路旨在为文本知识图谱中的实体或概念匹配相应的图像。利用在线百科全书是一种成本效益高的方式,可以找到符合条件的高质量图像,但存在无对应图像的情况。此外,许多图像仅与实体或概念有间接联系,无法准确反映实体的真实特征。利用网络搜索引擎能够便捷地搜集到与指定名称相关的图像,但可能带来一些不相关的噪声图像。为了有效减少由具有多重含义的实体标签引发的噪声问题,可以结合实体的具体类型信息来明确查询意图。为确保所选取图像的多样性,可以构建一个能筛选掉相似图像的检索模型。利用在线百科全书和网络搜索引擎可以互为补充,共同提升图谱的准确性和多样性。
4、现有的视觉语言模型通常采用对比学习策略的clip(contrastive vision-language pretraining),设计一个规模庞大的vlp(vision-language pretraining)模型,其训练数据达数亿级别。图像和文本分别经过clip的编码器提取特征,然后被映射到共享的特征空间内,通过计算余弦相似度来优化正样本对的相似性和负样本对的差异性。通过创建一个18亿图像-文本对的噪声数据集,训练了泛化能力更强的vlp模型align(alarge-scale image and noisy-text embedding)。为使这些vlp模型可以更好地适应特定的下游任务,通常需要利用专有数据微调模型。预训练-提示方法是一种有效利用vlp模型知识的技术,它可以在不调整预训练模型参数的前提下,寻找最优的提示来适配下游任务。由于不需要更新预训练模型的所有参数,因此大幅降低了计算成本。
5、通过使用可学习的向量来优化提示中的上下文单词,使coop(contextoptimization)模型能更灵活地适应特定的下游任务。提出vpt(visual prompt tuning),首次尝试将提示机制用于图像编码器,即在保持模型主干不变的情况下,在图像输入空间中引入少量可训练的参数。设计了一个小型神经网络upt(unified prompt tuning)来同时优化文本和视觉的可学习提示,实现了比单一模态提示更优的效果。maple(multi-modalprompt learning)通过在图像和文本编码器的多个transformer层中学习,促进了视觉-语言提示间的紧密耦合。
6、pic2word(mapping pictures to words)使用图像特征作为提示,并将其映射到文本模态中,从而拉近了图像与文本特征的相似度,提高了两者的对应匹配能力。
技术实现思路
1、为了克服现有技术的上述缺点,本发明提供基于视觉语言模型的青瓷跨模态知识图谱构建方法。主要提出一种基于vlp模型的图像多特征映射跨模态实体对齐方法,简称imfm-cmea(cro-ss-modal entity alignment method based on imag-e multi-featuremapping)。该方法通过将不同模态的特征映射到统一的特征空间中,实现了跨模态实体的对齐,尤其适用于青瓷图像与文本描述的匹配。进一步地,还将该方法应用于青瓷跨模态知识图谱的构建。公开的vlp模型初始化其中的图像和文本编码器,并且保持编码器参数不变。
2、为了解决上述技术问题本发明提供如下的技术方案:
3、一种基于视觉语言模型的青瓷跨模态知识图谱构建方法,从青瓷图像中提取轮廓、纹理和色彩方面的局部特征;接着引入带门控的多元融合器来动态地融合多个图像特征;进一步地通过多层全连接网络,学习将融合特征映射到一个合适的中间表示空间,以引导文本编码器生成与图像特征更加匹配的文本特征;最后借助infonce损失函数对模型进行训练和优化。
4、进一步,所述方法包括以下步骤:
5、步骤1:视觉语言模型的构建,基于该模型的图像多特征映射跨模态实体对齐方法,通过将不同模态的特征映射到统一的特征空间中,实现跨模态实体的对齐,尤其适用于青瓷图像与文本描述的匹配;公开的vlp模型初始化其中的图像和文本编码器,并且保持编码器参数不变;
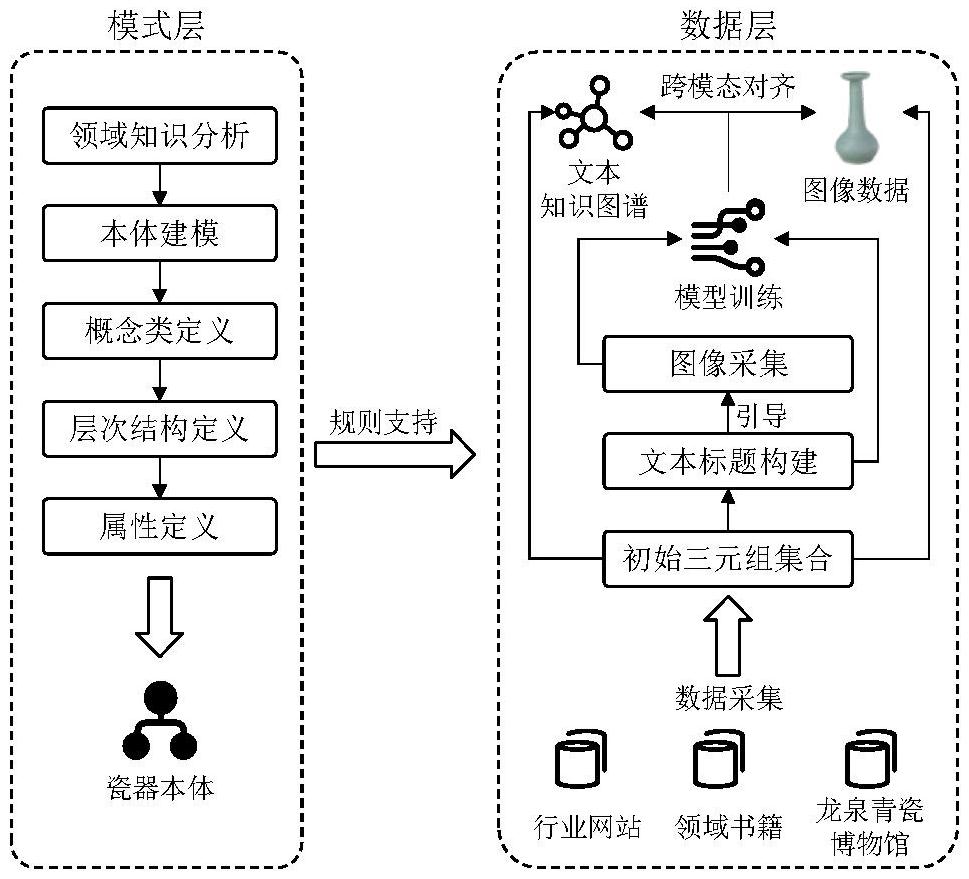
6、步骤2:首先进行模式层的本体建模,在充分分析瓷器领域知识的基础上,定义瓷器本体的概念类、层次结构和属性,精细的模式层能够支持数据层的构建,首先从多个来源采集数据层所需的数据,然后根据规则将它们映射为初始三元组集合,并构建成文本知识图谱,进一步地,利用imfm-cmea方法对其中包含的图像数据进行跨模态对齐;在此之前,还需创建包含图像和文本标题的chinaware数据集,以进行imfm-cmea的训练,最后将图文数据映射为一系列对齐的跨模态三元组知识,并存储到文本知识图谱中。
7、再进一步,所述步骤1中,视觉语言模型的构建步骤如下:
8、步骤1.1:进行图像局部多特征提取:在imfm-cmea,即图像多特征提取与跨模态实体对齐中,图像多特征提取扮演着至关重要的角色,通过捕捉青瓷在器形、纹样和色彩方面独特的图像特征,可为后续文本特征的重构提供关键的视觉信息,这种局部多特征的选择策略能够显著提升不同模态间实体的有效关联和对齐;
9、对于给定的图像i,基于数字图像处理技术提取其在轮廓、纹理和色彩方面的局部特征,为突出图像中最显著的部分,首先采用u2-net(two-level nested u-structure)分割图像,以描绘出瓷器器形的主要轮廓,并初步清除了无效像素点;
10、接着进行图像预处理,以提高图像的质量,首先,采用高斯滤波平滑图像,以减少图像中的随机噪声和微小波动;然后,增强图像的对比度,使图像不同部分的差异更明显,纹理和结构更突出;进一步地,采用canny算子识别图像中主体的关键结构轮廓,canny算子是一种准确性高且抗噪能力出色的边缘检测算法,同时,利用有着较强灰度和旋转不变性的局部二值模式(lbp)捕获主体的纹理信息;接着,通过高斯混合模型(gaussian mixturemodels,gmms)抽取色彩特征,该模型由多个高斯分布叠加构成,并通过期望最大化算法进行训练,能够适应复杂的数据分布形态,在进行色彩特征提取之前,图像先被转换至hsi(hue-saturation-intensity)颜色空间,因为hsi空间更贴近人类对颜色的感知方式,是一种比rgb(red-green-blue)更为直观的颜色表述;
11、图像编码器将所有图像特征μ转化为对应的器形特征向量μs、纹样特征向量μp和色彩特征向量μc;
12、通过捕捉青瓷图像在多个维度的局部特征,提升了不同模态间的实体关联和对齐效果,为构建青瓷多模态知识图谱提供了坚实基础;
13、步骤1.2:图像多特征融合:采用带门控的多元融合器为输入的图像特征与局部多特征自适应地分配权重,生成可信赖的融合特征,图像多特征的融合策略借鉴了基于门控的特征融合策略,在训练过程中,该策略可以自动为每个特征分配权重,不需要手动设置,带门控的多元融合器首先学习每个特征适当的融合权重,以整合给定图像的多个特征μ,μs,μp,μc,所述公式为:
14、
15、zi=σi(lni(μ′))
16、式中,μ′表示图像多特征初步整合的结果;ln表示线性层;表示拼接计算;zi表示每个图像特征对应的融合权重,i∈[0,3],zi∈[0,1];σ表示sigmoid激活函数;
17、最后在进行特征融合时,每个图像特征的占比由融合权重zi决定,所述公式为:
18、
19、式中,μf表示图像多特征的融合结果;m表示待融合特征的个数,m∈[0,3];θ表示tanh激活函数;μi表示待融合特征μ,μs,μp,μc;
20、步骤1.3:文本特征映射重构:通过多层全连接映射器将输入的融合特征转化为映射特征,然后将其与编码的文本特征融合,输入文本编码器中,使重构的文本特征更接近匹配的图像特征,利用图像特征来指导文本特征ν的重构,使其更接近于图像特征μ,首先,设计多层全连接映射器将融合特征μf转化为映射特征λ,过程公式为:
21、
22、式中,λ表示映射特征;φ表示relu(rectified linear unit)激活函数,其中输出层无relu;η表示dropout正则化技术,其中输出层无dropout;l表示全连接传播层数;m表示中间层隐藏神经元个数;o表示映射特征输出维度;
23、接着,将映射特征λ与经过编码的文本t进行融合,然后将其输入到文本编码器中,所述计算公式为:
24、
25、式中,v表示重构的文本特征;f(·)表示文本编码器;ψ表示tokenizer文本编码;t表示文本;s表示映射特征λ的缩放范围;
26、步骤1.4:跨模态对比学习:构造infonce(information noise contrastiveestimation)损失函数用于imfm-cmea的训练,通过相似度计算获得图像和文本之间的相似度分数;借鉴clip中的跨模态对比学习思想,使用infonce损失函数优化模型的学习结果,即在训练的过程中,建立图像特征μ和文本特征ν之间的联系,通过计算跨模态特征间的余弦相似度来衡量它们之间的相似性;首先,计算文本到图像的对比损失lt→i,所述公式为:
27、
28、式中,n表示图像-文本对的数量;vi,μi表示正样本对;vi,μj表示负样本对;τ∈r表示可学习的温度系数;
29、接着,计算图像到文本的对比损失li→t:
30、
31、最后,得到模型的最终对比损失
32、
33、更进一步,所述步骤2的过程如下:
34、步骤2.1:模式层本体建模:采用自上而下的七步法构建瓷器领域的知识本体,将瓷器知识划分为基本、造型、工艺、功能和文化五大类别,并对其中的关键概念、层次结构和相关属性进行了明确的定义,瓷器是本体的顶层结构,每件瓷器都被视为一个独立的实体,基本、造型和工艺是瓷器的三个核心概念类,窑口和馆藏子类别属于基本概念类,以文字描述的形式呈现,造型概念类下细分为器形和部件等子类别,工艺概念类中有釉色这一子类别,器形与部件描述了瓷器的物理外观特征,纹样描绘了瓷器表面的图案,色彩代表了釉烧后胎体上的颜色构成,釉色是对瓷器颜色分类的描述,这些都是瓷器的重要视觉特征,根据定义的概念类设计关系属性,用以表达每个概念与瓷器实体间的联系,采用has[概念类]of/in的格式表示;在数据属性的设计方面,用唯一标识(id)来准确识别不同的实体或关系;用中文名称(name)或英文名称(enname)来直观区分不同的实体或关系;用dataurl记录数据的存储位置;用label记录实体的非结构化文本描述;用longitude和latitude记录窑口和馆藏等的地理坐标信息;完备的瓷器本体可以为后续提取青瓷相关的实体和属性提供规则框架,首先搜集和梳理相关的知识内容,接着从中提取与本体概念类别相对应的实体,并将其整合到本体中,然后填充具体的数据属性,并依据本体中定义的关系属性来明确实体间的相互联系;
35、步骤2.2:数据层初始三元组集合构建:图谱数据层采用自下而上的方法构建,为了丰富图谱的内容,从公开互联网数据中提取了部分结构化数据,依据瓷器本体定义的规则,形成了初始的三元组集合;
36、步骤2.3:chinaware数据集构建:为赋予imfm-cmea更全面的瓷器知识,基于搜索引擎方法创建了chinaware数据集,首先依据预先定义的瓷器本体,挑选具有代表性的器形、纹样和釉色等实体信息,并以此为基础构建文本标题,然后在图像搜索引擎中采集与标题相匹配的图像数据,通过筛选和清洗,这些图像数据与文本标题共同构成了chinaware数据集;
37、步骤2.4:跨模态实体对齐与图谱可视化:经过chinaware数据集训练的imfm-cmea能够被应用于青瓷的跨模态实体对齐工作,首先运用imfm-cmea对图文数据对的相似度进行评分,然后根据评分结果筛选出排名靠前且得分高于预定阈值的图文对,将它们转化为跨模态三元组形式的知识,最后,将这些三元组知识整合并存储到neo4j中。
38、本发明的视觉语言模型部分主要由四个模块组成:
39、图像局部多特征提取模块:在imfm-cmea中,图像多特征提取扮演着至关重要的角色。通过捕捉青瓷在器形、纹样和色彩方面独特的图像特征,可为后续文本特征的重构提供关键的视觉信息。这种局部多特征的选择策略能够显著提升不同模态间实体的有效关联和对齐。
40、具体来说,对于给定的图像,本文基于数字图像处理技术提取其在轮廓、纹理和色彩方面的局部特征,为突出图像中最显著的部分,首先采用u2-net(two-level nested u-structure)分割图像,以描绘出瓷器器形的主要轮廓,并初步清除了无效像素点。接着进行图像预处理,以提高图像的质量。首先,采用高斯滤波平滑图像,以减少图像中的随机噪声和微小波动;然后,增强图像的对比度,使图像不同部分的差异更明显,纹理和结构更突出。
41、进一步地,采用canny算子识别图像中主体的关键结构轮廓。canny算子是一种准确性高且抗噪能力出色的边缘检测算法。同时,利用有着较强灰度和旋转不变性的局部二值模式(local binary pattern,lbp)捕获主体的纹理信息。接着,通过高斯混合模型(gaussian mixture models,gmms)抽取色彩特征,该模型由多个高斯分布叠加构成,并通过期望最大化算法进行训练,能够适应复杂的数据分布形态。在进行色彩特征提取之前,图像先被转换至hsi(hue-saturation-intensity)颜色空间,因为hsi空间更贴近人类对颜色的感知方式,是一种比rgb(red-green-blue)更为直观的颜色表述。
42、输入图像后提取的局部特征的可视化结果,即器形、纹样和色彩的图像。最终,图像编码器将所有图像特征μ转化为对应的器形特征向量μs、纹样特征向量μp和色彩特征向量μc。
43、这种方法通过捕捉青瓷图像在多个维度的局部特征,提升了不同模态间的实体关联和对齐效果,为构建青瓷多模态知识图谱提供了坚实基础。
44、图像多特征融合模块:采用带门控的多元融合器为输入的图像特征与局部多特征自适应地分配权重,生成可信赖的融合特征。图像多特征的融合策略借鉴了基于门控的特征融合策略。在训练过程中,该策略可以自动为每个特征分配权重,不需要手动设置。具体来说,带门控的多元融合器首先学习每个特征适当的融合权重,以整合给定图像的多个特征μ,μs,μp,μc,计算公式如下所示:
45、
46、zi=σi(lni(μ′))
47、式中,μ′表示图像多特征初步整合的结果;ln表示线性层;表示拼接计算;zi表示每个图像特征对应的融合权重,i∈[0,3],zi∈[0,1];σ表示sigmoid激活函数。
48、最后在进行特征融合时,每个图像特征的占比由融合权重zi决定,计算公式如下所示:
49、
50、式中,μf表示图像多特征的融合结果;m表示待融合特征的个数,m∈[0,3];θ表示tanh激活函数;μi表示待融合特征μ,μs,μp,μc。
51、文本特征映射重构模块:通过多层全连接映射器将输入的融合特征转化为映射特征,然后将其与编码的文本特征融合,输入文本编码器中,使重构的文本特征更接近匹配的图像特征。利用图像特征来指导文本特征v的重构,可以使其更接近于图像特征μ。首先,设计多层全连接映射器将融合特征μf转化为映射特征λ,转化过程公式如下所示:
52、λ=φ(η(ln(l,m,o,μf)))
53、式中,λ表示映射特征;φ表示relu(rectified linear unit)激活函数,其中输出层无relu;η表示dropout正则化技术,其中输出层无dropout;l表示全连接传播层数;m表示中间层隐藏神经元个数;o表示映射特征输出维度。
54、接着,将映射特征λ与经过编码的文本t进行融合,然后将其输入到文本编码器中,计算公式如下所示:
55、
56、式中,ν表示重构的文本特征;f(·)表示文本编码器;ψ表示tokenizer文本编码;t表示文本;s表示映射特征λ的缩放范围。
57、跨模态对比学习模块:构造infonce(information noise contrastiveestimation)损失函数用于imfm-cmea的训练,通过相似度计算获得图像和文本之间的相似度分数。借鉴clip中的跨模态对比学习思想,使用infonce损失函数优化模型的学习结果,即在训练的过程中,建立图像特征μ和文本特征v之间的联系,通过计算跨模态特征间的余弦相似度来衡量它们之间的相似性。首先,公式如下所示,计算文本到图像的对比损失lt→i:
58、
59、式中,n表示图像-文本对的数量;vi,μi表示正样本对;vi,μj表示负样本对;τ∈r表示可学习的温度系数。
60、接着,计算图像到文本的对比损失li→t:
61、
62、最后,得到模型的最终对比损失
63、
64、青瓷跨模态知识图谱的完整构建框架需要采用自顶向下的方式。首先进行模式层的本体建模,在充分分析瓷器领域知识的基础上,定义瓷器本体的概念类、层次结构和属性。精细的模式层可以支持数据层的构建。首先从多个来源采集数据层所需的数据,然后根据规则将它们映射为初始三元组集合,并构建成文本知识图谱。进一步地,利用imfm-cmea方法对包含的图像数据进行跨模态对齐。在此之前,还需创建包含图像和文本标题的数据集,以进行imfm-cmea的训练。最后将图文数据映射为一系列对齐的跨模态三元组知识,并存储到文本知识图谱中。
65、采用自上而下的七步法构建瓷器领域的知识本体时。将瓷器知识划分为基本、造型、工艺、功能和文化五大类别,并对其中的关键概念、层次结构和相关属性进行了明确的定义。瓷器是本体的顶层结构,每件瓷器都被视为一个独立的实体。基本、造型和工艺是瓷器的三个核心概念类。窑口和馆藏等子类别属于基本概念类,以文字描述的形式呈现。造型概念类下细分为器形和部件等子类别。工艺概念类中有釉色这一子类别。器形与部件描述了瓷器的物理外观特征,纹样描绘了瓷器表面的图案,色彩代表了釉烧后胎体上的颜色构成,釉色是对瓷器颜色分类的描述,这些都是瓷器的重要视觉特征。根据定义的概念类设计关系属性,用以表达每个概念与瓷器实体间的联系,采用has[概念类]of/in的格式表示。
66、在数据属性的设计方面,用唯一标识(id)来准确识别不同的实体或关系;用中文名称(name)或英文名称(enname)来直观区分不同的实体或关系;用dataurl记录数据的存储位置;用label记录实体的非结构化文本描述;用longitude和latitude记录窑口和馆藏等的地理坐标信息。完备的瓷器本体可以为后续提取青瓷相关的实体和属性提供规则框架。
67、首先搜集和梳理相关的知识内容,接着从中提取与本体概念类别相对应的实体,并将其整合到本体中。然后填充具体的数据属性,并依据本体中定义的关系属性来明确实体间的相互联系。
68、图谱数据层采用自下而上的方法构建。为了丰富图谱的内容,需从从专业书籍或者以及权威行业网站中提取了数据。依据瓷器本体定义的规则,形成了初始的三元组集合。
69、为赋予imfm-cmea更全面的瓷器知识,需要构建用于视觉语言模型训练的数据集。具体来说,首先依据预先定义的瓷器本体,挑选具有代表性的器形、纹样和釉色等实体信息,并以此为基础构建文本标题。然后在图像搜索引擎中采集与标题相匹配的图像数据,通过筛选和清洗,这些图像数据与文本标题共同构成了数据集。
70、经过数据集训练的imfm-cmea能够被应用于青瓷的跨模态实体对齐工作。首先运用imfm-cmea对图文数据对的相似度进行评分。然后根据评分结果筛选出排名靠前且得分高于预定阈值的图文对,将它们转化为跨模态三元组形式的知识。最后,将这些三元组知识整合并存储到neo4j中。通过融合图像数据与文本形式的知识图谱,不仅丰富了图谱的视觉展示效果,而且通过智能化的实体对齐技术,进一步提升了知识图谱构建的准确性和质量。
71、本发明的有益效果在于提出了一种计算图像和文本特征相似度分数的视觉语言模型,并基于该模型提出用于构建青瓷跨模态知识图谱的方法。本发明有效地缓解了青瓷领域跨模态实体对齐的问题,显著提高了青瓷细节特征的跨模态识别准确度。整体过程展示了一种基于视觉语言模型的青瓷跨模态知识图谱构建方法。
- 还没有人留言评论。精彩留言会获得点赞!