本发明涉及数据处理,具体涉及基于自然语言理解推理的语言大模型高质交互系统。
背景技术:
1、自然语言理解推理的语言大模型为复杂版面文本批改提供了一种新的解决方案;这些模型能够模拟人类的语言理解过程,对复杂版面文本内容进行深入分析,从而实现自动化、标准化的批改;然而,中文作为一种语义丰富、结构复杂的语言,在进行自然语言理解时面临诸多挑战;特别是在复杂版面文本批改这一特定场景下,对语言的细微差别和深层含义的理解尤为重要。
2、在进行复杂版面文本的批注时,通常根据自然语义处理的技术对复杂版面文本进行分词、句法和语义分析,然后结合整体行文结构、词汇丰富度等因素对复杂版面文本进行评分,但是在构建基于自然语言理解推理的语言大模型高质交互系统时,由于中文的复杂性和多样性,传统的分词方法可能无法充分适应复杂版面文本中的复杂语境和多样表达,这导致分词结果可能与复杂版面文本的真实语义有所偏差,进而影响到复杂版面文本的整体理解和批改质量,从而给出低质量的文本评价结果。
技术实现思路
1、本发明提供基于自然语言理解推理的语言大模型高质交互系统,以解决现有的问题。
2、本发明的基于自然语言理解推理的语言大模型高质交互系统采用如下技术方案:
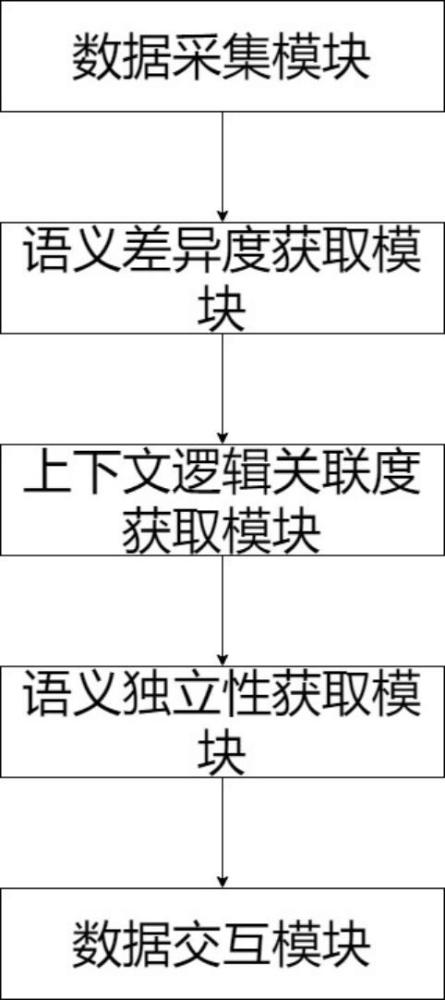
3、包括以下模块:
4、数据采集模块,用于获取原始复杂版面文本的文本数据;将所述文本数据划分为若干个段落,将每个段落划分为若干条语句,将每条语句划分为若干个分词结果,每个分词结果对应一个概率值;
5、语义差异度获取模块,用于根据概率值对每条语句中所有分词结果进行筛选,获取每条语句的参考分词结果;根据每条语句中每个分词结果与参考分词结果之间的相似情况,获取每个分词结果的语义差异度;
6、上下文逻辑关联度获取模块,用于根据每个语句中每个分词结果与上下文语句之间的逻辑相关情况,获取每个分词结果的上下文逻辑关联度;
7、语义独立性获取模块,用于根据每个分词结果的语义差异度和上下文逻辑关联度,获取每个分词结果的语义独立性;
8、数据交互模块,用于根据语义独立性筛选出合理分词结果;通过合理分词结果进行交互得到最优分词结果;根据最优分词结果对复杂版面文本进行评估,得到文本评价结果。
9、优选的,所述根据概率值对每条语句中所有分词结果进行筛选,获取每条语句的参考分词结果,包括的具体方法为:
10、对于任意一条语句,将所述语句中概率值最大的分词结果记为所述语句的参考分词结果。
11、优选的,所述根据每条语句中每个分词结果与参考分词结果之间的相似情况,获取每个分词结果的语义差异度,包括的具体方法为:
12、对于文本数据中第i个段落内第j条语句中第k个分词结果,分别将第k个分词结果和第k个分词结果的参考分词结果划分为若干个文本结构;
13、获取第k个分词结果与所述参考分词结果之间每个文本结构的相似性;
14、将第k个分词结果与所述参考分词结果之间所有文本结构的相似性的均值,作为第k个分词结果的语义差异度。
15、优选的,所述获取第k个分词结果与所述参考分词结果之间每个文本结构的相似性,包括的具体方法为:
16、对于第k个分词结果的参考分词结果,分别获取第k个分词结果与所述参考分词结果的每个文本结构的词向量;
17、对于第k个分词结果与所述参考分词结果之间的任意一个文本结构,将第k个分词结果的所述文本结构的词向量与所述参考分词结果的所述文本结构的词向量之间的余弦相似度,作为第k个分词结果与所述参考分词结果之间的所述文本结构的相似性。
18、优选的,所述根据每个语句中每个分词结果与上下文语句之间的逻辑相关情况,获取每个分词结果的上下文逻辑关联度,包括的具体方法为:
19、对于文本数据中第i个段落内第j条语句中第k个分词结果,获取第k个分词结果的邻域文本数据;
20、获取第k个分词结果的句向量和第k个分词结果的邻域文本数据中每条语句的句向量;
21、根据第k个分词结果的句向量与第k个分词结果的邻域文本数据中不同语句的句向量之间的逻辑相关情况,获取第k个分词结果与其邻域文本数据中每条语句之间的逻辑关联值;
22、计算第k个分词结果对应的所有所述逻辑关联值的平均值,将所有所述逻辑关联值的平均值作为第k个分词结果的上下文逻辑关联度。
23、优选的,所述获取第k个分词结果的邻域文本数据,包括的具体方法为:
24、预设一个邻域参数t,将第j条语句之前的t条语句以及之后的t条语句共同构成的文本数据,作为第j条语句中第k个分词结果的邻域文本数据。
25、优选的,所述获取第k个分词结果的句向量和第k个分词结果的邻域文本数据中每条语句的句向量,包括的具体方法为:
26、将第k个分词结果的所有文本结构的词向量的均值,作为第k个分词结果的句向量;对于第k个分词结果的邻域文本数据中任意一条语句,将所述语句的参考分词结果的所有文本结构的词向量的均值,作为第k个分词结果的邻域文本数据中所述语句的句向量。
27、优选的,所述获取第k个分词结果与其邻域文本数据中每条语句之间的逻辑关联值,包括的具体方法为:
28、对于第k个分词结果的邻域文本数据中任意一条语句,将第k个分词结果的句向量与所述语句的句向量共同输入训练好的神经网络中,若输出结果为蕴含,将1作为第k个分词结果与所述语句之间的逻辑关联值;若输出结果为不相干,将0作为第k个分词结果与所述语句之间的逻辑关联值。
29、优选的,所述根据每个语句中每个分词结果与上下文语句之间的逻辑相关情况,获取每个分词结果的上下文逻辑关联度,包括的具体方法为:
30、对于任意一条语句中任意一个分词结果,将所述分词结果的语义差异度与所述分词结果的上下文逻辑关联度的乘积,记为第一乘积;将所述语句的参考分词结果的概率值与所述分词结果的概率值的差值,记为第一差值;将第一乘积与第一差值的比值,记为第一比值;将第一比值进行线性归一化后的值,作为所述分词结果的语义独立性。
31、优选的,所述根据语义独立性筛选出合理分词结果,包括的具体方法为:
32、预设一个阈值参数t,对于任意一条语句,对于除所述语句的参考分词结果以外的任意一个分词结果,若所述分词结果的语义独立性大于阈值参数t,将所述分词结果记为合理分词结果。
33、本发明的技术方案的有益效果是:本发明根据每条语句中每个分词结果与参考分词结果之间的相似情况,获取每个分词结果的语义差异度;根据每个语句中每个分词结果与上下文语句之间的逻辑相关情况,获取每个分词结果的上下文逻辑关联度;根据每个分词结果的语义差异度和上下文逻辑关联度,获取每个分词结果的语义独立性;根据语义独立性筛选出合理分词结果;通过合理分词结果进行交互得到最优分词结果;根据最优分词结果对复杂版面文本进行评估,得到文本评价结果;通过分词结果的语义独立性判断复杂版面文本分析时是否存在难以分辨的歧义分割结果,然后将可能存在语义理解分歧的不同分词情况进行输出,由阅卷教师进行交互,根据交互结果获取最优分词结果,避免了仅根据分词概率进行语义理解时可能产生的复杂版面文本歧义理解,通过在复杂版面文本批改时进行高质量的交互得到了更优秀的复杂版面文本语义理解,从而得到更优秀的文本评价结果。