一种基于特征级解耦的虚假人脸检测和溯源方法
本发明涉及计算机数据处理,特别涉及一种基于特征级解耦的虚假人脸检测和溯源方法。
背景技术:
1、深度伪造人脸检测任务旨在判断给定的图像或视频中人脸是否经过深度伪造技术篡改或合成。从伪造特征建模方式的角度,可以将现有工作分为两大类:基于人工构造的方法和基于深度学习的方法。基于人工构造的方法依赖于丰富的专家知识,并显式地建模伪造特征进行检测,例如视觉伪影、头部姿态不一致性、异常眨眼频率、瞳孔形状不规则和角膜高光不一致等。然而,该类方法一般只能针对特定伪造方法构建明确的单一鉴伪线索,对其他伪造方法的数据可能无法有效应用,因此适用面较为有限。相较而言,基于深度学习的方法能够直接从大规模的伪造数据中学习多样的伪造特征,从而达到更出色的检测效果。该类方法通过数据驱动的方式捕捉各种伪造痕迹,例如轮廓贴合痕迹、频域伪影、时序伪造痕迹、身份信息不一致和纹理瑕疵等。此外,一些方法尝试结合任务特性,设计更适合的网络结构、损失函数、数据增广和训练策略,以提升检测性能。
2、深度伪造溯源则是一项更精细的任务,需要分析伪造图像或视频背后的生成细节,包括合成方法、网络结构和超参数等方面的信息。根据是否能够预先接触待溯源的目标数据,深度伪造溯源可以分为主动溯源和被动溯源。主动溯源一般需要预先将设计好的指纹信息在训练阶段嵌入生成模型中,推断时则直接提取嵌入的指纹信息进行溯源。相比被动溯源,主动溯源在鲁棒性和准确性方面通常更优越,但是其需要预先将信息嵌入到深度伪造数据中,导致其应用场景受限。被动溯源则不需要接触待溯源的目标数据,可进一步分为模型级溯源、网络结构级溯源和方法级溯源。文献通过提取对抗生成网络(generativeadversarial networks,gans)模型指纹判断图像由哪个具体模型合成的。yang等人经验性实验证明了网络结构指纹的存在性,且其具有全局一致的性质,并提出了结构溯源网络dna-det进行网络结构级别的溯源。girish等人考虑了gans方法的更新迭代迅速,探索了开放环境下的gans方法溯源场景。jia等人在包括5种不同人脸替换方法生成的数据集上训了一个视频级的伪造方法溯源模型。
3、现有的工作往往将人脸伪造检测任务和溯源任务视为独立的研究方向,并设计独立的检测模型。例如,一些溯源工作将其视为检测任务后的后续任务。然而这些工作往往忽视了伪造检测任务与溯源任务之间的联系,本发明注意到,检测任务关注的是伪造共性特征,而溯源任务关注的是伪造特殊特征。从虚假人脸伪造的流程来看,不同伪造方法既存在共同的操作,又存在独特的操作。因此人脸伪造特征也可以分为共同的伪造痕迹和独有的伪造痕迹。由于两个任务所关注的特征分量之间存在这种互补的联系,因此将人脸伪造检测任务和人脸伪造溯源任务进行统一是有可能的。
4、以往的工作曾经尝试过分离多种伪造方式的共性特征和特殊特征,其做法是在分类器部分设计一个伪造分类头和领域分类头,分别学习特定方法的纹理和可概括特征。然而本发明发现,即使是二值损失监督的编码器,如果将编码器的部分参数冻结,仅仅重新训练领域分类头,也能够获得一定的检测效果。如图1所示,xception所得到的伪造特征总是按照伪造领域进行聚集。这也暗示了单纯的二值损失监督并不能获得理想的共性特征。因此,如何分离共性特征与特异性特征值得更多的思考。
5、人脸伪造图像的伪造特征包含方法无关伪造特征(共性特征)和方法相关伪造特征(特异性特征)。由于这两种伪造特征分量对应分别对应检测任务与溯源任务,这种隐式的联系也使得一个统一的框架成为了可能。
6、在此基础上,本发明进一步探索了如何分离伪造图像的共性特征与特殊特征,并将其作为统一人脸伪造检测任务和溯源任务的基础。由于两者的互补特性,本发明认为整合一个统一的框架对两个任务都可以有促进作用。然而,统一的虚假人脸检测和溯源框架存在以下的挑战:
7、(1)如何消除伪造无关特征的影响:深度神经网络会不经意间学习到内容或者身份信息,这会阻止网络学习到纯粹的伪造特征。
8、(2)如何对伪造特征进行编码:在特征编码阶段,同时对特殊伪造和共性伪造进行编码,对低级伪造特征和高级伪造特征进行编码。解决低级伪造特征如视觉伪影,伪造边界也难以被学习的问题。
9、(3)联合优化问题:本发明注意到,共性特征与特殊特征之间存在隐式联系,如何使用网络对共性特征和特殊特征进行分离,并最终分别进行检测和溯源任务。
技术实现思路
1、本发明实施例提供的一种基于特征级解耦的虚假人脸检测和溯源方法,包括:
2、基于伪造特征级解耦框架,进行虚假人脸检测和溯源。
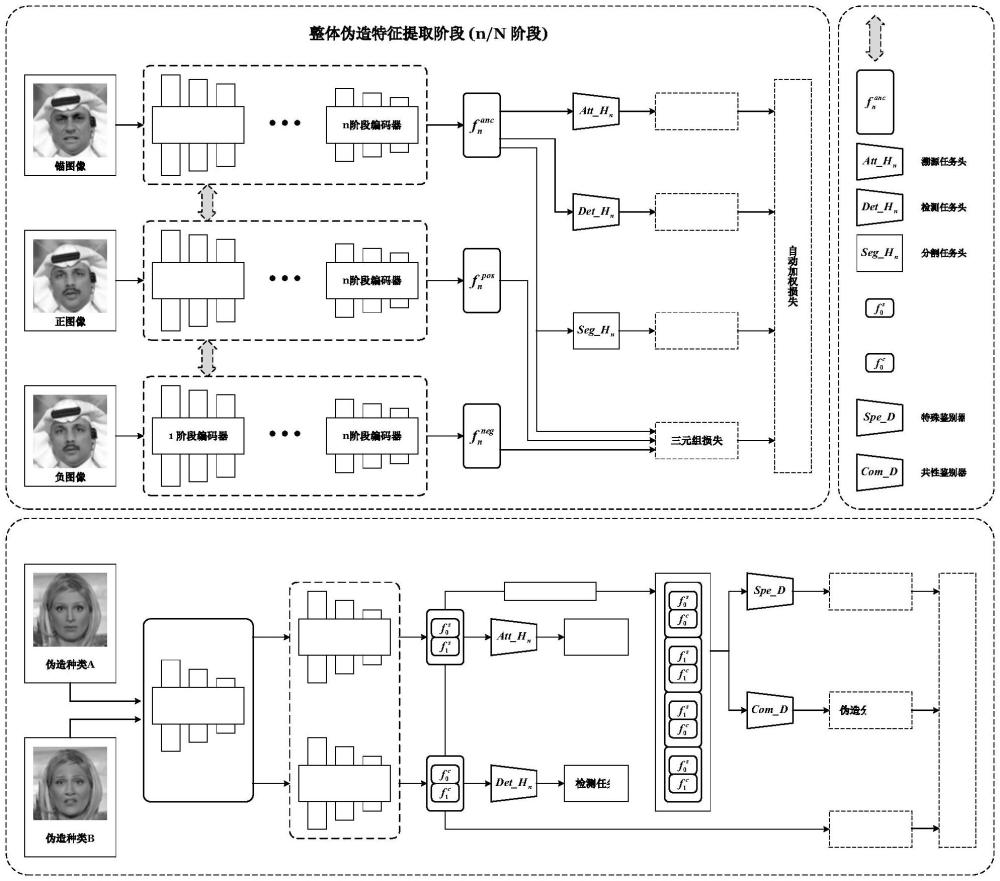
3、优选的,伪造特征级解耦框架包含两个阶段:渐进式伪造特征提取阶段和交叉解耦阶段。
4、优选的,渐进式伪造特征提取阶段包括:
5、n阶段整体伪造特征编码器:将编码器由浅层到深层分为n个阶段,以限制网络深度的方式从低级伪造特征(对应浅层特征)到高级伪造特征(对应深层特征)对整体伪造特征进行学习,然后逐渐在低级伪造特征的基础上学习到高级伪造特征;
6、三元相似度计算:将从数据集中随机选择一个和输入样本标签相同的图像以及一个和输入样本标签不同的图像,构建一个三元组,然后将三元组输入到整体伪造特征编码器中提取特征并计算三元组损失,三元组损失用于减小同类特征之间的距离,增大不同类特征之间的距离,定义如下:
7、
8、其中,xanc表示锚定形象,xpos与xanc标签相同,xneg属于标签不同;ep表示渐进式特征编码器的功能,符号d表示欧几里得距离,α是预定义的边距;
9、多目标特征提取模块:由交叉熵计算的二值分类损失来监督模型学习伪造相关特征:
10、
11、其中,表示交叉熵损失,hc是伪造相关特征的分类头,该特征由多个mlp层实现,y∈{fake,real}是二元分类标签,fake表示图像属于伪造图像,real表示图像属于真实图像;
12、或,
13、通过引导模型识别伪造图像的伪造方法:
14、
15、其中,hs为特定伪造特征的分类头,表示交叉熵损失,fn表示第n阶段的整体伪造特征图,y′∈{real,gan1,gan2,…}为给出标识出属于图像的标签的实例;
16、像素级伪造引导模块:将m划分为h1×w1不重叠的patch;其中,h1表示特征图的高,w1表示特征图的宽;然后得到相应的标签mk(k=1,2,…,h1w1),对每个补丁pk的所有m的值取平均值得到:
17、
18、假设为预测的位置图,预测的准确性用交叉熵损失来衡量:
19、
20、其中,mk表示伪造区域下采样到特征图大小对应像素级的标签,表示伪造特征图对于伪造区域的预测,k表示像素的编号;
21、预训练阶段整体损失:基于三个损失权参数平衡三个损失函数,并涉及来平衡它们,请注意,在训练时将涉及更多的参数,采用自动加权损失(awl)来自动选择参数,最后的损失弥补如下:
22、
23、其中,为预训练损失,s1、s2、s3、s4为可学习的参数,在网络训练过程中进行优化。对应三元组损失,表示真伪交叉熵损失,表示伪造类别的多分类损失,表示伪造区域的分割损失;
24、交叉解耦阶段包括:
25、共性和特殊编码器:编码器处理一对图像(x0,x1),其中x0表示操纵方法为a的伪造图像,x1表示操纵方法为b的图像;编码器e包括预训练的伪造特征编码器ep和特异性伪造编码器es和共性伪造编码器ec,分别在伪造特征的基础上提取共性伪造特征和特殊伪造特征;在es和ec的头部加入了基于双线性插值法进行上采样的多尺度特征融合网络;将编码器应用于每一对,得到对应的伪造特征如下:
26、{f1,…,fn}i=ep(xi)
27、
28、其中,i∈{0,1}是图像的索引,{f1,…,fn}i、fis和fic分别对应输入图像xi的总体伪造特征、特殊伪造特征和共性伪造特征,wj、αj表示特征融合时第j层的可学习权重,xi表示输入图像,ep表示预训练的整体伪造特征编码器,es表示特殊特征编码器,ec表示共性特征编码器;
29、特征编码损失:采用领域损失和伪造损失进行特殊特征和共性特征的提取,公式为:
30、
31、特征重构损失:自我重构和交叉重构;对于自重构,分别利用共性鉴别器和特殊鉴别器进行鉴别,公式为:
32、
33、正交正则化损失:使用正交分集损失来降低注意力特征的相关性,正交分集损失表示为:
34、
35、训练阶段整体损失:训练过程使用自动加权损失进行训练,最终的awl计算结果为:
36、
37、其中s5、s6、s7、s8为参数,在训练过程中进行优化,表示特征编码损失,表示自重建损失,表示交叉重建损失,表示正交正则化损失。
38、共性和特殊编码器:编码器处理一对图像(x0,x1),其中x0表示操纵方法为a的伪造图像,x1表示操纵方法为b的图像;编码器e包括预训练的伪造特征编码器ep和特异性伪造编码器es和共性伪造编码器ec,分别在伪造特征的基础上提取共性伪造特征和特殊伪造特征;在es和ec的头部加入了基于双线性插值法进行上采样的多尺度特征融合网络;将编码器应用于每一对,得到对应的伪造特征如下:
39、{f1,…,fn}i=ep(xi)
40、
41、其中,i∈{0,1}是图像的索引,{f1,…,fn}i、fis和fic分别对应输入图像xi的总体伪造特征、特殊伪造特征和共性伪造特征,wj、αj表示特征融合时第j层的可学习权重,xi表示输入图像,ep表示预训练的整体伪造特征编码器,es表示特殊特征编码器,ec表示共性特征编码器;
42、特征编码损失:采用领域损失和伪造损失进行特殊特征和共性特征的提取,公式为:
43、
44、特征重构损失:自我重构和交叉重构;对于自重构,分别利用共性鉴别器和特殊鉴别器进行鉴别,公式为:
45、
46、正交正则化损失:使用正交分集损失来降低注意力特征的相关性,正交分集损失表示为:
47、
48、训练阶段整体损失:训练过程使用自动加权损失进行训练,最终的awl计算结果为:
49、
50、其中s5、s6、s7、s8为参数,在训练过程中进行优化,表示特征编码损失,表示自重建损失,表示交叉重建损失,表示正交正则化损失。
51、优选的,基于特征级解耦的虚假人脸检测和溯源方法,还包括:
52、测试阶段:使用预训练编码器提取伪造特征,并使用特殊编码器提取特殊伪造特征进行伪造溯源任务,使用共性编码器提取共性伪造特征进行伪造分类任务。
53、本发明实施例提供的一种电子设备,所述电子设备包括:
54、至少一个处理器;以及
55、与所述至少一个处理器通信连接的存储器;其中,所述存储器存储有可被所述至少一个处理器执行的计算机程序,所述计算机程序被所述至少一个处理器执行,以使所述至少一个处理器能够执行上述任一项所述的基于特征级解耦的虚假人脸检测和溯源方法。
56、本发明实施例提供的一种计算机可读存储介质,所述计算机可读存储介质存储有计算机指令,所述计算机指令用于使处理器执行时实现上述任一项所述的基于特征级解耦的虚假人脸检测和溯源方法。
57、本发明实施例提供的一种计算机程序产品,所述计算机程序产品包括计算机指令,在被电子设备执行时,所述电子设备执行上述任一项所述的基于特征级解耦的虚假人脸检测和溯源方法的计算机程序代码。
58、本技术取得了以下有益效果:
59、本发明的贡献可以分为四个部分:
60、(1)本发明创新地将人脸伪造检测和溯源统一在了一个任务中。将伪造特征视为互补地共性特征和特异性特征,并在特征解耦的基础上对两个子任务进行联合优化。
61、(2)本发明提出了一个渐进式伪造特征编码器,利用多尺度分割所包含的像素级伪造特征引导网络对于更加抽象的伪造特征的学习。渐进式的方式能够保证高级的伪造特征建立在低级的伪造之上。并且这种学习方式能够通过多阶段限制神经网络深度的方式,有效地消除深度神经网络学习到伪造无关特征的问题。
62、(3)本发明提出了一个伪造特征交叉解耦模块,通过并在训练过程中引入精心设计的伪造对实现伪造特征级别的“共性-特殊”交叉重建,并引入正交正则化损失降低共性特征和特殊特征的相关性。
63、(4)大量的实验表明,本发明的框架实现了两种任务的统一,并且任务之间互相存在着促进作用。在检测和溯源任务中,本发明的框架分别具有更先进的性能。
64、本发明的其它特征和优点将在随后的说明书中阐述,并且,部分地从说明书中变得显而易见,或者通过实施本发明而了解。本发明的目的和其他优点可通过在所写的说明书、权利要求书、以及附图中所特别指出的结构来实现和获得。
65、下面通过附图和实施例,对本发明的技术方案做进一步的详细描述。
- 还没有人留言评论。精彩留言会获得点赞!