一种基于RAG的垂直领域知识多轮问答方法与流程
本发明属于人工智能,具体为一种基于rag的垂直领域知识多轮问答方法。
背景技术:
1、垂直领域的专业问答是人工智能领域走向落地的重要场景,传统的基于文档知识库或知识图谱的问答系统主要存在以下问题;1、无法很好地理解用户问题的上下文,特别是在多轮问答中,系统难以维持对话的连贯性;2、对于需要综合多个知识点或需要推理和分析的问题,难以提供满意的答案;3、在处理非标准化或开放式问题时缺乏灵活性,难以适应不同的提问方式等。
2、随着生成式大语言模型(large language mode l,llm)的广泛使用,基于检索增强生成(retr i eva l augmented generat i on,rag)的垂直领域问答系统在一定程度上解决了上述问题,但仍可能存在复杂问题未拆解导致检索准确性不高、遗漏重要语义信息、检索到的文档块丢失重要语义和阅读顺序、文档块不包含答案造成内容、历史对话混杂无用信息、文档块内容过长淹没用户真实意图等问题,导致对话系统性能不够理想。
技术实现思路
1、本发明的目的在于提供一种基于rag的垂直领域知识多轮问答方法,以解决上述背景技术中提出的问题。
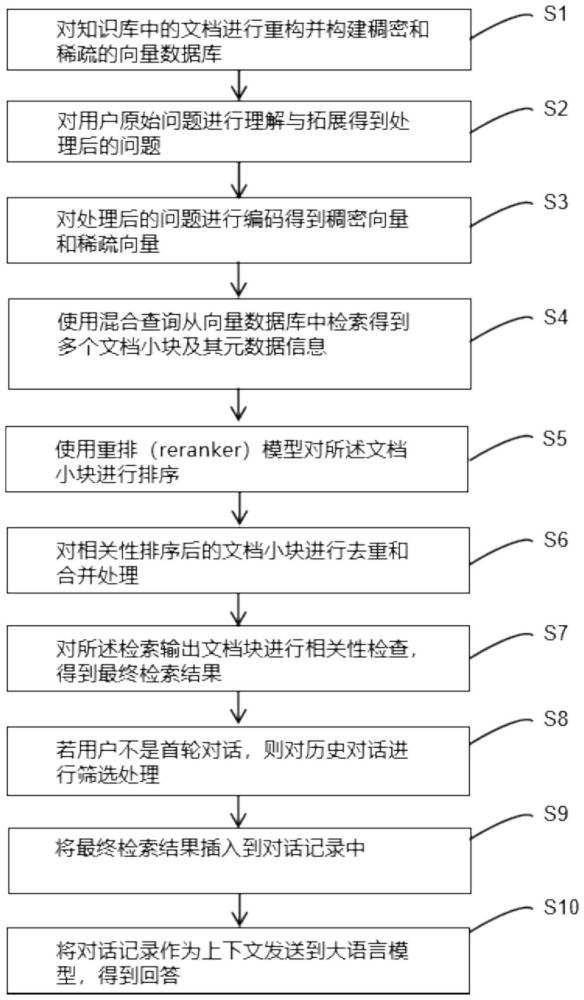
2、为了实现上述目的,本发明提供如下技术方案:一种基于rag的垂直领域知识多轮问答方法,包括以下步骤:
3、s1,对知识库中的文档进行重构并构建稠密和稀疏的向量数据库;
4、优选地,步骤s1中的详细步骤为:
5、s101,提取文档的层级结构信息,所述层级结构信息包括但不限于文档标题,章节标题,有序列表,无序列表,表格,图片,表格标题,图片标题;
6、优选地,所述提取方法包括人工提取、算法自动提取、算法自动提取加人工审核;
7、s102,根据所述层级结构信息对文档进行大块切分;
8、进一步的,设定大块的字符数上限和下限,结合所述层级结构信息对文档进行大块切分,并将每个大块的字符数控制在所述大块的字符数上限和下限之间;
9、s103,大块层级语义信息补全:根据上述层级结构信息,获取大块的上级层级的标题和内容,对上级层级的标题和内容进行命名实体识别,提取所述垂直领域内的重要实体,并将上级标题和上级重要实体添加到大块的前面;
10、进一步的,所述大块的上级层级至少包括以下之一:
11、1)文档标题;2)与当前大块在语义上有“总-分”关系的前序大块;
12、s104,将各个大块拆分为多个小块;
13、进一步的,设定小块的字符数上限和下限,结合所述层级结构信息对每个大块进行小块切分,并将每个小块的字符数控制在所述小块的字符数上限和下限之间;
14、s105,小块层级语义信息补全:对文档大块的文本内容进行命名实体识别,提取文档大块内的领域重要实体,并将大块的上级标题、上级重要实体、大块标题、大块内的重要实体添加到小块前面,补全小块文档缺失的重要语义信息;
15、s106,构建小块文本的稠密向量和稀疏向量;
16、进一步的,所述稠密向量为通过bert、gpt、自编码器等神经网络构建的大部分特征值为非0值的语义向量;所述稀疏向量是指通过词袋模型、tf-idf、稀疏编码等传统nlp方法获得的大部分特征值为0的语义向量;
17、进一步的,所述稠密和稀疏向量能够利用多功能语义向量模型,一次推理同时得到稠密和稀疏向量;
18、s107,构建小块元数据信息,并将小块内容的稠密和稀疏向量及小块元数据信息一起写入向量数据库,所述小块元数据信息包含:小块文本内容、小块id、大块文本内容、大块id、原始文档id、原始文档名称。
19、s2,对用户原始问题进行理解与拓展得到处理后的问题;
20、优选地,对用户问题进行实体补全和句式优化,所述实体补全和句式优化利用大语言模型多轮问答理解和文本生成式能力,进行关键实体自动补全,并将口语表达转换为专业的书面语规范式表达,进一步地,如有历史对话,则利用大语言模型综合历史轮次的问答记录以及当前用户的最新问题,得到语义和语法结构完整、提问表达更专业的问题;
21、优选地,对得到的完整问题进行问题分解,得到能够解答问题的一系列子问题,进一步地,所述问题分解,能够通过大语言模型的思维链能力,将用户问题拆分为多个基础的子问题;
22、s3,对处理后的问题进行编码得到稠密向量和稀疏向量;
23、s4,使用混合查询从向量数据库中检索得到多个文档小块及其元数据信息;
24、优选地,所述混合查询为通过使用处理后问题的稠密向量去向量数据库稠密向量列查询,同时使用稀疏向量去向量数据库的稀疏向量列查询,利用倒数排名融合(rrf,reci proca l rank fus i on)算法对稀疏检索和稠密检索的结果进行合并;
25、s5,使用重排(reranker)模型对检索得到的文档小块进行排序;
26、优选地,对问题和多个文档小块组成pa i r(问题和文档小块内容组成的文本对)计算相似度,根据相似度分数排序,并根据阈值过滤不符合要求的文档小块;进一步地,所述相似度能够通过排序模型如bge-reranker直接得到问题和文档的相关性分数,或者通过文本向量模型得到文本和文档小块各自的向量,并计算向量之间的距离;
27、s6,对相关性排序后的文档小块进行去重和合并处理,包括:
28、s601,遍历排序后的文档小块,若存在文档小块的元数据信息中的大块id与排序靠前的小块元的数据信息中的大块id相同,则去掉所述大块id相同的排序靠后的文档小块;
29、s602,遍历s601处理后的文档小块,若该文档小块的元数据信息中的原始文档id与排序更靠前的小块的元数据信息中的原始文档id相同,则将该排序靠后的文档小块合并到文档id相同但排序靠前的文档小块中,并去掉文档id相同但排序靠后的文档小块;
30、s603,遍历s602处理后的文档小块,用文档小块元数据信息中的大块文本内容作为去重和合并处理后的检索输出文档块;
31、s7,对所述检索输出文档块进行相关性检查,得到最终检索结果;
32、进一步的,所述相关性检查为利用大语言模型对文档进行检查:判断各个文档与用户问题相关性级别,将过滤掉与用户问题无关的检索输出文档块之后的文档块作为最终检索结果;
33、进一步的,所述相关性级别包括:1)直接回答:该文档直接回答了用户问题;2)部分回答:该文档部分回答了用户问题;3)无关:该文档不能回答用户问题,与问题无关。
34、s8,若用户不是首轮对话,则对历史对话进行筛选处理;
35、进一步的,所述筛选处理为计算用户问题与历史轮次用户问题的语义相似度分数,以及用户问题与历史轮次的系统回答的语义相似度分数,如果两个相似度分数中有一个大于设定的阈值,则保留该轮次的对话,否则,舍弃该轮次的对话,从而防止用户编辑错误或者无意义的对话轮次等带来的负面影响。
36、s9,将最终检索结果插入到对话记录中;
37、将最终检索结果内容处理成一条user(用户)记录,插入到倒数第二轮对话,例如:
38、{"user":"检索到的内部知识库文档如下:<retr ieved documents>"};
39、新增一条ass i stant(大语言模型)记录,例如:
40、{"ass i stant":"收到内部知识库文档,我将根据文档来回答用户问题,请提供用户问题。"};
41、s10,将对话记录作为上下文发送到大语言模型,得到回答。
42、本发明的有益效果如下:
43、本发明设计了:以知识库中的文档进行重构,并构建稠密和稀疏的向量数据库,作为基础,辅助对客户原始问题进行理解与拓展,并实现问题的有效处理,利用混合查询从向量数据库中检索得到多个文档小块及元数据信息,并利用重排模型对文档小块进行排序,对相关性排序后的文档小块进行去重和合并处理,然后进行相关性检查,在对用户是否为首轮对话进行判断、筛选处理,并将最终的检索结果插入到对话记录中,将对话记录作为上下文发送到大语言模型,得到回答;
44、通过以上方法,使得垂直领域中的专业复杂问题得到有效的语义拆分和层级关联,提高了检索时问题相关语义的检索成功率、原文引用的精确率和召回率,同时也有效避免了历史对话混杂无用信息、文档块内容过长淹没用户真实意图等问题,能实现高效的垂直领域知识多轮问答。
- 还没有人留言评论。精彩留言会获得点赞!