一种基于知识注入和知识编码的语言隐写分析方法
本发明属于信息隐藏领域,涉及文本隐写检测,具体涉及一种基于知识注入和知识编码的语言隐写分析方法。
背景技术:
1、文本隐写分析随着自然语言处理技术的进步而迅速发展。尽管检测能力有了显著提升,但在面对真实的在线文本检测场景时,仍然难以取得令人满意的结果。一个显著的原因在于,公共网络空间中的文本,如twitter等,往往是高度碎片化的,单个文本通常具有有限的指示特征。当前的检测模型在从个体输入文本中提取足够丰富的特征方面面临着挑战,阻碍了对文本的全面理解,限制了模型的最终检测能力。
2、yang等人[sesy:linguistic steganalysis framework integrating semanticand syntactic features]提出了一种sesy方案,使用强大的预训练语言模型——双向编码器表示变换(bert)来提取语义特征,并设计了sesy框架来考虑由于嵌入秘密信息而引起的语法变化,有效提升了现有先进的语言隐写分析算法。这种方案在一定程度上增强了文本隐写分析的能力,但这些检测模型在真实网络检测场景中面临着由网络文本的碎片化性质引起的严峻挑战。
3、fu等人[hga:hierarchical feature extraction with graph and attentionmechanism for linguistic steganalysis]提出了一种hga方案,引入了ls-bgat,这是一种创新方法,将文本节点与单词节点合并,形成一个庞大的异构图,利用图注意网络(gat)来全面了解单词和语料库之间的相互关系。但是这种方案仍然未能有效应对在线隐写文本检测中面临的文本碎片化挑战。基于单个句子输入实现对文本的深入理解几乎是不可能的。
技术实现思路
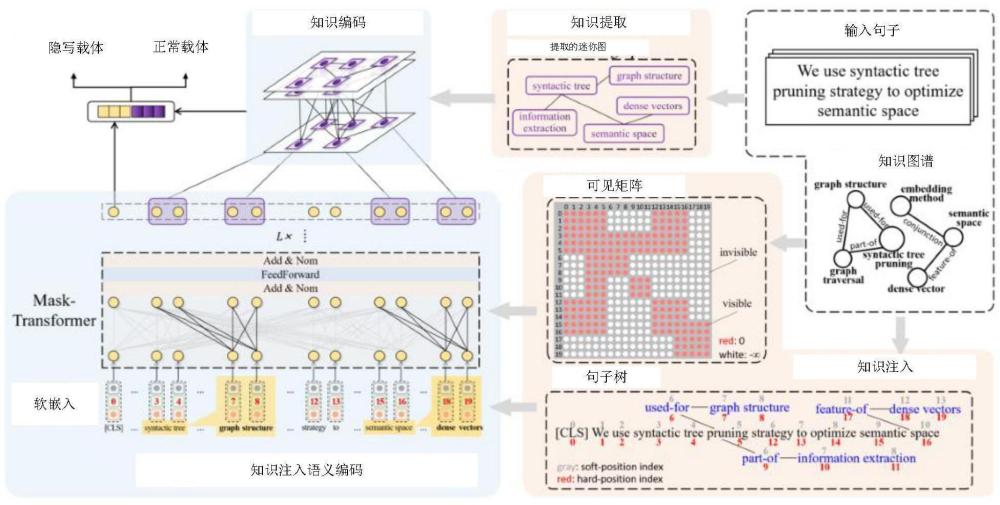
1、本发明提出了一种基于知识注入和知识编码的语言隐写分析方法,用以解决由网络文本碎片化引起的文本隐写分析的实际挑战等问题。
2、所述基于知识注入和知识编码的语言隐写分析方法,具体步骤如下:
3、步骤一,构建一个基于知识注入和知识编码的语言隐写分析系统模型;
4、所述的系统模型命名为kike,包括两个部分:基于知识注入的语义编码和基于知识提取的知识编码。
5、步骤二,语言隐写分析系统模型借助知识图对输入句子进行预处理,以适应现有的顺序语言模型框架,完成知识注入;
6、预处理过程具体为:
7、步骤201,输入句子s是由一系列标记组成的集合,表示为s={w1,w2,...,wn},其中n是句子的长度,wi是句子的第i个标记。知识图k是由实体和实体之间关系的三元组组成的图结构,表示为k(v,e),k包含多个三元组(vi,ek,vj),其中vi和vj是实体,ek表示实体之间的关系。
8、步骤202,利用知识图将输入句子从原始形式s转换为句子树s'为:
9、
10、其中,(wi,...,wi+l-1)代表由l个词组成的实体ei,表示连接到ei的多个分支。
11、步骤203,对句子树s'中的标记重新编号,使用软位置索引和硬位置索引的组合进行语言模型的位置嵌入;
12、具体实现过程为:
13、首先,原句子每个标记的软位置索引为1~n,若知识图注入的内容与原句子软位置i的距离为x,则知识图注入内容的软位置索引为i+x,并在位置嵌入过程中映射到相同的位置向量;
14、然后,硬位置索引用于重新排序句子树中的标记,并将句子树展平为线性序列,以进行编码阶段。
15、最后,通过以上软硬位置索引的组合,得到句子树中各标记的索引。
16、步骤204,使用硬位置索引构建可见矩阵m,指导知识分支的可视范围;
17、可见矩阵m表示如下:
18、
19、其中,表示两个标记在同一分支,表示两个标记不在同一分支。i和j是硬位置索引。
20、步骤三,对句子树和可见矩阵采用bert,完成语义特征的提取,并进行知识注入语义编码;
21、具体过程为:
22、步骤301,bert的嵌入层包括词嵌入、位置嵌入和段嵌入,在位置嵌入部分使用软位置索引,以表示句子中标记的相对位置,词嵌入和段嵌入部分保留原始的映射方法。
23、步骤302,将这三部分信息嵌入到高维特征空间并相加,以获得隐藏层变量h0={h1,h2,...,hn′}∈rn′×d,其中n'是经过压缩句子树后展平序列的长度,d是特征的数量。
24、步骤303,将h0传递给mask-transformer模块,该模块由l个堆叠的mask-transformer子层组成,每一层的输入向量集是前一层的输出向量集,如下所示:
25、hl=mask-transformerl(hl-1),1≤l≤l
26、每一层mask-transformer子层包括一个多头注意力层、一个全连接层和两个残差连接标准化层。使用可见矩阵来控制在注意力计算过程中标记之间的相关性计算。每个隐藏向量组(ql,kl,vl)的计算如下:
27、
28、其中,wq、wk和wv是可训练的参数矩阵,hl是第l层中所有隐藏向量的组合。如果向量hli对hlj是可见的,那么相关计算与bert中的相同。如果hli和hlj是不可见的,由于mij=-∞,注意力得分将被设置为0。sl是第l层的注意力得分。
29、步骤304,经过l层语义特征的细化,使用sigmoid函数得到知识注入语义编码的表示向量:
30、
31、表示第l层mask-transformer子层输出的隐藏层变量;
32、步骤四,在预处理的同时,使用图结构建模的ke模块对输入句子和知识图进行知识提取,得到迷你图;
33、首先从输入句子中提取已识别的实体,并逐一连接,然后将它们连接到知识图中相应的对象分支,形成一个迷你图g(γ,e),其中γ={v1,…,vm},m是句子树中实体的数量,e={εab=(va,vb)1≤a,b≤m}是边集。
34、通过最大池化函数将hc中的实体向量作为图节点的初始向量,并采用一个邻接矩阵a∈rm×m来表示实体之间的连接关系。
35、步骤五,通过一个两层的gat对迷你图进行知识编码。
36、具体实现过程为:
37、首先,第一层采用多头图注意力层,提取节点之间的关联信息。对于每个多头图注意力层,使用一个全局共享的权重矩阵w对初始向量进行线性变换。
38、然后,使用softmax方法计算每个节点与其连接节点之间的图注意力系数αij,具体表达式如下:
39、
40、其中,ni表示与节点ei相连接的所有邻居节点的集合,w∈rd×d'和是可训练的模型参数,leakyrelu是一个非线性激活函数。
41、最后,利用αij,通过自适应聚合来自邻居节点的信息对节点i的特征表示进行更新,如下所示:
42、
43、其中,σ是sigmoid激活函数。将多个gals的输出向量串联起来,馈送到下一个单独的gal中,得到m个节点的向量集合e2。
44、步骤六,知识编码完成后,将捕获的实体节点特征和从知识注入模块获得的表示向量串联并加入到一个全连接层中,系统模型通过全连接层的输出预测输入文本是正常载体还是隐写载体。
45、步骤七,对系统模型的预测准确性进行训练,在训练阶段,使用交叉熵损失函数更新系统模型参数,当损失函数最小化时,训练完成。
46、交叉熵损失函数为:
47、
48、其中,y是正常载体的标签,是模型输出的预测标签,n是输入样本的数量。
49、本发明的优点在于:
50、1、本发明提出了一种基于知识注入和知识编码的语言隐写分析方法,解决真实的在线环境中面临着与网络文本的碎片化问题,可以通过知识注入的语义提取部分、认知验证部分和信息融合部分。通过借助知识图引入专业领域知识,语言模型可以更好地辅助执行分类任务。
51、2、本发明为了实现基于知识注入和知识编码的新型语言隐写分析,在知识注入中,借助来自专业领域的知识图将三元组注入到句子中,结合生成的句子树和可见矩阵与现有的transformer架构一起提取语义特征。在知识编码中,将实体集成到迷你图中,并使用图神经网络进行认知验证。上述两个过程结合,使语言隐写分析的结果更加准确。
- 还没有人留言评论。精彩留言会获得点赞!