一种基于情感分析的智能语音阅读方法及系统与流程
本发明涉及自然语言处理,特别是一种基于情感分析的智能语音阅读方法及系统。
背景技术:
1、属性级情感三元组抽取任务的现有研究存在几个主要缺点。首先,早期采用的管道式方法容易导致误差传播和计算开销增加,影响了抽取结果的精度和处理效率。虽然后来提出的网格标注和位置感知标注等方法能够一次性抽取所有三元组,但这些方法往往需要复杂的建模和推理过程。其次,基于编码器-解码器范式的研究虽然利用了先进的预训练语言模型,但在属性-意见术语对的配对学习方面仍显不足,常出现误匹配或漏匹配的情况。
2、此外,现有模型在情感判定能力上也存在局限性。由于语料库中情感样本分布不均衡以及部分情感表达的隐晦性,当前的三元组抽取模型在识别文本中不同属性项的细微情感差异时表现不佳。这些问题限制了三元组抽取任务的应用效果,使得现有技术难以满足实际需求。
技术实现思路
1、鉴于现有的属性级情感三元组抽取方法存在误差传播、计算开销大、建模与推理复杂、属性-意见术语对配对学习不足以及情感判定能力局限等问题,提出了本发明。
2、因此,本发明所要解决的问题在于如何提高抽取的准确性、效率和实用性,从而更好地满足实际应用需求。
3、为解决上述技术问题,本发明提供如下技术方案:
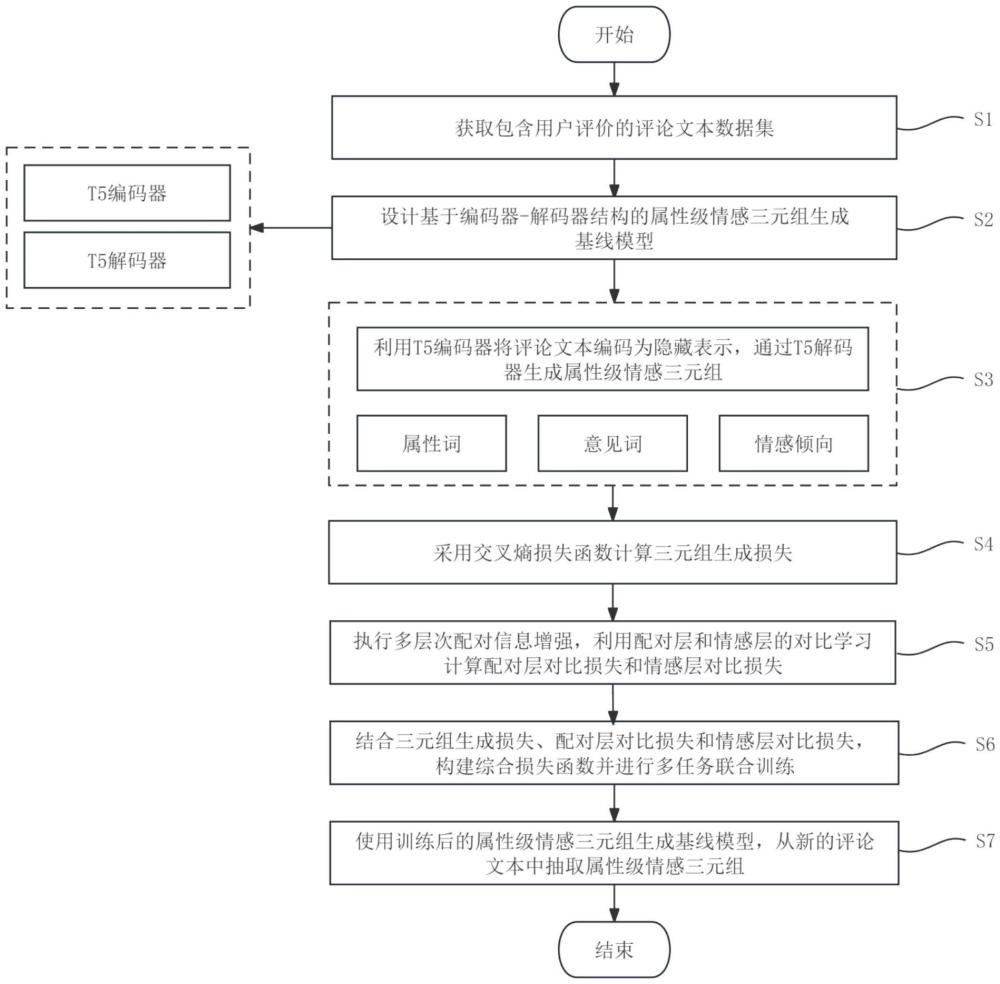
4、第一方面,本发明实施例提供了一种基于情感分析的智能语音阅读方法及系统,其包括获取包含用户评价的评论文本数据集;构建基于编码器-解码器结构的属性级情感三元组生成基线模型;利用t5编码器将评论文本编码为隐藏表示,并基于隐藏表示,通过t5解码器生成属性级情感三元组,属性级情感三元组包括注释式和抽取式两种输出范式;采用交叉熵损失函数计算三元组生成损失le;执行多层次配对信息增强,利用配对层和情感层的对比学习计算配对层对比损失laop和情感层对比损失lsen;结合三元组生成损失、配对层对比损失和情感层对比损失,构建损失函数并进行多任务联合训练;使用训练后的属性级情感三元组生成基线模型,从新的评论文本中抽取属性级情感三元组。
5、作为本发明所述基于情感分析的智能语音阅读方法及系统的一种优选方案,其中:t5编码器的具体公式如下:
6、he=t5encoder(x1,x2,...,xn)
7、其中,he∈rn×d为t5编码器的输出隐藏表示,d为隐藏表示的维度,t5encoder(·)为t5编码器,(x1,x2,...,xn)为输入评论文本的词元序列,n为序列长度,r为实数集。
8、t5解码器的具体公式如下:
9、
10、其中,为t5解码器在时间步t的输出,d为隐藏表示的维度,t5decoder(·)为t5解码器,wv和bv为可学习的参数矩阵和偏置向量,softmax(·)为softmax激活函数,y<t为解码器在时间步t之前的输出序列,pt为当前时间步t的词表概率分布,he∈rn×d为t5编码器的输出隐藏表示,r为实数集。
11、作为本发明所述基于情感分析的智能语音阅读方法及系统的一种优选方案,其中:多层次配对信息增强包括配对层信息增强和情感层信息增强,配对层信息增强的执行步骤如下:定义描述信息集合,描述信息集合包括匹配类型描述和不匹配类型描述;基于bert模型对配对描述信息进行编码,获取描述信息表征;从t5编码器的输出中抽取属性词和意见词的隐层表征,随机拼接属性词和意见词的隐层表征,并通过线性层获取术语对表征;采用对比学习方法,计算描述信息表征和术语对表征之间的相似度;基于配对层对比损失函数优化属性级情感三元组生成基线模型的参数,以改善属性词和意见词的匹配。
12、作为本发明所述基于情感分析的智能语音阅读方法及系统的一种优选方案,其中:获取描述信息表征的具体公式如下:
13、
14、其中,为[cls]位置的输出,waop和baop为可学习参数,daop为配对信息描述,m表示词数量,bert(·)为预训练的双向transformer编码器函数,leakyrelu(·)为带有泄漏的线性整流单元激活函数。
15、术语对表征的具体公式如下:
16、
17、其中,ha和ho分别为属性词和意见词的稠密表示,f为一个平均池化函数,ws和bs为可学习参数,i为评论文本x中属性词和意见词的位置索引,he为t5编码器的输出隐藏表示,hc为术语对表征。
18、作为本发明所述基于情感分析的智能语音阅读方法及系统的一种优选方案,其中:情感层信息增强的执行步骤如下:定义情感类别集合,情感类别集合包括积极、中立和消极三种情感类别;基于bert模型对情感类别描述进行编码,并使用新线性层获取情感信息表征;从t5编码器的输出中抽取真实的属性词和意见词对的隐层表征;通过线性层将真实术语对的隐层表征转换为术语对表征;采用对比学习方法,计算情感信息表征和术语对表征之间的相似度;基于情感层对比损失函数优化属性级情感三元组生成基线模型的参数,以提高其对不同情感的理解和区分能力;情感信息表征dsen的具体公式如下:
19、
20、其中,leakyrelu(·)为带有泄漏的线性整流单元激活函数,为[cls]位置的输出,wsen和bsen为可学习参数。
21、作为本发明所述基于情感分析的智能语音阅读方法及系统的一种优选方案,其中:配对层对比损失函数lsen的具体公式如下:
22、
23、其中,为所有不属于当前情感类别的真实术语对表征集合,dsen为情感信息表征,为序列中真实的术语对信息,τ为温度系数,为真实的术语对信息和情感信息表征的相似度。
24、作为本发明所述基于情感分析的智能语音阅读方法及系统的一种优选方案,其中:综合损失函数l的具体公式如下:
25、l=αle+βlaop+γlsen
26、其中,α、β、γ为权重超参数,le、laop、lsen分别为三元组生成损失函数、配对层对比损失函数和情感层对比损失函数。
27、第二方面,本发明实施例提供了基于配对信息增强的属性级情感三元组抽取系统,其包括文本数据获取模块,用于获取包含用户评价的评论文本数据集;基线模型构建模块,用于构建基于编码器-解码器结构的属性级情感三元组生成基线模型;三元组生成模块,用于利用t5编码器将评论文本编码为隐藏表示,并基于隐藏表示,通过t5解码器生成属性级情感三元组,属性级情感三元组包括注释式和抽取式两种输出范式;损失计算模块,用于采用交叉熵损失函数计算三元组生成损失;多层次配对信息增强模块,用于执行多层次配对信息增强,利用配对层和情感层的对比学习计算配对层对比损失和情感层对比损失;多任务联合训练模块,用于结合三元组生成损失、配对层对比损失和情感层对比损失,构建综合损失函数并进行多任务联合训练;属性级情感三元组生成模块,用于使用训练后的属性级情感三元组生成基线模型,从新的评论文本中抽取属性级情感三元组。
28、第三方面,本发明实施例提供了一种计算机设备,包括存储器和处理器,所述存储器存储有计算机程序,其中:所述计算机程序指令被处理器执行时实现如本发明第一方面所述的基于情感分析的智能语音阅读方法及系统的步骤。
29、第四方面,本发明实施例提供了一种计算机可读存储介质,其上存储有计算机程序,其中:所述计算机程序指令被处理器执行时实现如本发明第一方面所述的基于情感分析的智能语音阅读方法及系统的步骤。
30、本发明有益效果为:本发明通过设计注释式和抽取式两种输出范式,增强了模型的适用性。通过配对层和情感层的对比学习,本发明显著提升了属性词和意见词的匹配准确度,以及情感判定的精确性。采用t5模型,本发明避免了传统非生成式方法中的误差传播问题,同时能够更深入地探索标签语义,提高了三元组抽取的整体质量。通过结合三元组生成损失、配对层对比损失和情感层对比损失,本发明实现了多任务联合训练。这种方法不仅提高了模型的整体性能,还增强了模型在处理复杂情感表达时的鲁棒性。
- 还没有人留言评论。精彩留言会获得点赞!