一种基于声音信号的行车事件判断方法
本发明涉及汽车智能座舱,尤其涉及一种基于声音信号的行车事件判断方法。
背景技术:
1、随着汽车行业向着智能化网联化的快速发展,多种类型的传感器技术应用到智能汽车上,汽车的感知能力越来越强大,除了视觉技术,声音信号也能提供很多有用信息,并具备无需光照,不受阴雨天及黑天情况干扰的优势。运用声音事件检测技术的音频监控设备由于其成本低廉,体积小巧,安装方便快捷,可靠性较强,不容易损坏,维护简单的特点,未来将会在智能汽车中广泛应用。
2、近些年,声音事件分类和检测的技术框架主要是基于深度学习路线,采用卷积神经网络(cnn)和循环神经网络(rnn)搭建检测模型。对音频信号中的特征进行提取和分类,作为声音事件分析与检测的依据,并据此直接得出检测结果。但模型没有考虑到场景中声音事件之间的联系来帮助模型进行预测,同时,对每个声音事件及其相继发生的其他声音事件之间的关系信息也没有有效利用。所以在复调声音事件检测中与人类相比还存在一定的差距,特别是音频中存在多类声音事件的情况下的情况。并且由于现有的基于深度学习的模型由于参数量较大和实时性不足的原因,迟迟未能广泛的应用在实际场景中,特别是在对于实时性要求很高的行车场景。
3、当车辆处于正常状况并正常行驶时,车辆自身和周围环境通常不会出现太大的噪音,当突然出现较大噪音时,通常伴随着一些突发事件的发生,例如车祸的剧烈碰撞声,人们的惊叫声,泥石流和山体滑坡等自然灾害,车辆自身出现爆胎等问题时也会发出较大的响声,因此行驶过程中突然出现的巨大噪音,通常预示着可能存在的危机。音量的瞬时检测的时间非常短,可以做到在几十毫秒以内完成检测,实时性很高,可以进行快速预警。
4、目前尚且没有技术方案能够较全面的分别提取每个声音事件之间的共现关系和相继关系,并利用两种关系进行声音事件检测,同时基于音量大小进行快速预警,在极短的时间内提醒驾驶员或对自动驾驶中的车辆做出相应的调整。
5、keisuke imoto和seisuke kyochi在论文中指出,单个场景中发生的声音事件的种类是有限的,并且有一些声音事件会同时发生。因此希望能够利用有限的声音数据高效地建模声音事件。把声音事件的发生表示为一个图,其节点表示事件发生的频率,其边表示共同发生的声音事件,将该图用于声音事件建模,并引入图拉普拉斯正则化到神经网络的目标函数中。该方法考虑了每段音频中同时的发生声音事件。helinwang和yuexianzou在论文中考虑到现有的音频标注数据集中的没有声音事件之间的共同出现的概率。为了解决这个问题,在论文中通过基于图的方法对标签依赖关系进行建模,其中图的每个节点代表一个标签。通过挖掘标签之间的统计关系构造邻接矩阵来表示图的结构信息,并利用图卷积网络(gcn)来学习节点表示,从而隐式地建模标签依赖关系。然后将生成的节点表示应用于声学表示以进行分类。
6、现有的技术几乎都仅采用神经网络模型如cnn,rnn,crnn等拾取到的音频信号中每种声音事件独立的特征来进行声音事件检测,没有用到声音事件之间的联系来帮助模型进行预测,同时也没有考虑声音事件相继发生的时序关系。并且现有技术在遇到危险状况时,其所需的检测时间可能会延误时机,无法及时做出应对来避免事故的发生。
7、现有方法在构建声音事件关系图时,仅考虑了同时发生的声音事件,使用两个声音事件同时发生的概率来构建无向图或使用两个声音事件同时发生的条件概率来构建有向图,二者都没有考虑到声音事件相继发生的情况。同时,使用共现方法构建的图形结构由于其条件较为苛刻,基本都存在节点多但边少的情况,即该方法构造出来的图较为稀疏,在使用图网络学习稀疏图时传递效率低,浅层图神经网络不能获取足够的关系信息,加深图网络会在增加运算量的同时面临过度平滑的风险。并且,许多有关联的声音事件还具有一定的时间先后性,这种事件相继发生的关系性对于声音事件的推断也是十分重要的。
8、现有技术都没有分别考虑到在场景中多个事件同时和相继发生的情况,也没有将声音事件同时发生和相继发生两种关系分别构建声音事件关系图,并作为事件分析的有效信息,目前尚无利用图神经网络分别学习声音事件关系和声音事件相继关系,并对声音事件发生时序关系和起止时间检测,同时将突然出现的大音量噪声作为行车中的预警信息的声音事件识别技术。
技术实现思路
1、本发明要解决的技术问题是针对上述现有技术的不足,提供一种基于声音信号的行车事件判断方法,对行车事件进行判断预警。
2、为解决上述技术问题,本发明所采取的技术方案是:一种基于声音信号的行车事件判断方法,包括以下步骤:
3、步骤1:构建声音事件关系图,包括以下步骤:
4、步骤1.1:获取和处理声音事件的标签信息;
5、读取声音事件数据集中的标签文件,获取训练数据集的标签信息,包括每个音频的标签文件中的声音事件类别,以及每个声音事件的起止时间;
6、将各类声音事件分别记为li,i=0,1,2,3...n,n为声音事件类别总数,并记录每个声音事件的起止时间,其中每个声音事件记为m为声音事件总数,每个声音事件的开始时间表示为结束时间表示为
7、步骤1.2:设计声音事件关联窗;
8、对声音事件数据集中音频中每一个声音事件的结束时间处使用长度为t的声音事件关联窗,以获取每个声音事件发生后相继发生的其他声音事件,实现声音事件相继发生的检测性能;
9、步骤1.3:计算声音事件关系,构建声音事件共现关系图和相继关系图,包括以下步骤:
10、步骤1.3.1:获取共现关联关系的声音事件信息;
11、由步骤1.1获取到的每个声音事件的起止时间和获取每一个声音事件的共现范围内的其他声音事件,当一个声音事件lim的共现范围内存在其他声音事件时视为共现关系,记为且i≠j;声音事件共现的次数,记为表示声音事件li与声音事件lj同时发生的次数,即共现的次数;
12、步骤1.3.2:获取相继关联关系的声音事件信息;
13、由步骤1.1获取到的每个声音事件的起止时间和结合声音事件关联窗的长度t,获取每一个声音事件lim的声音事件关联窗范围内的其他声音事件,当一个声音事件的声音事件关联窗范围内存在其他声音事件则视为相继关系,记为两个相继关系的声音事件相继发生的次数,记为表示声音事件li与声音事件lj在同一个声音事件窗内发生的次数;
14、步骤1.3.3:获取声音事件数据集中各类声音事件的发生次数;
15、统计声音事件数据集中各类声音事件发生的次数,记为xi,表示声音事件li发生的次数;
16、步骤1.3.4:通过先验概率公式分别计算出声音事件数据集中各类声音事件同时发生和相继发生的概率;
17、根据得到的声音事件数据集中各类声音事件发生的次数xi以及音频事件共现的次数计算当声音事件li发生时同时发生声音事件lj的概率如下公式所示:
18、
19、其中,为当声音事件li发生时同时发生声音事件lj的概率,为音频事件共现的次数,xi为声音事件数据集中各类声音事件发生的次数;
20、根据得到的各类事件发生的次数xi以及事件相继发生的次数计算出声音事件相继发生的概率如下公式所示:
21、
22、采用概率阈值α1,α2,α1,α2∈(0,1)对声音事件进行过滤,将概率低于概率阈值的声音事件作为节点之间的关系权重,并将关系权重置0,如下公式所示:
23、
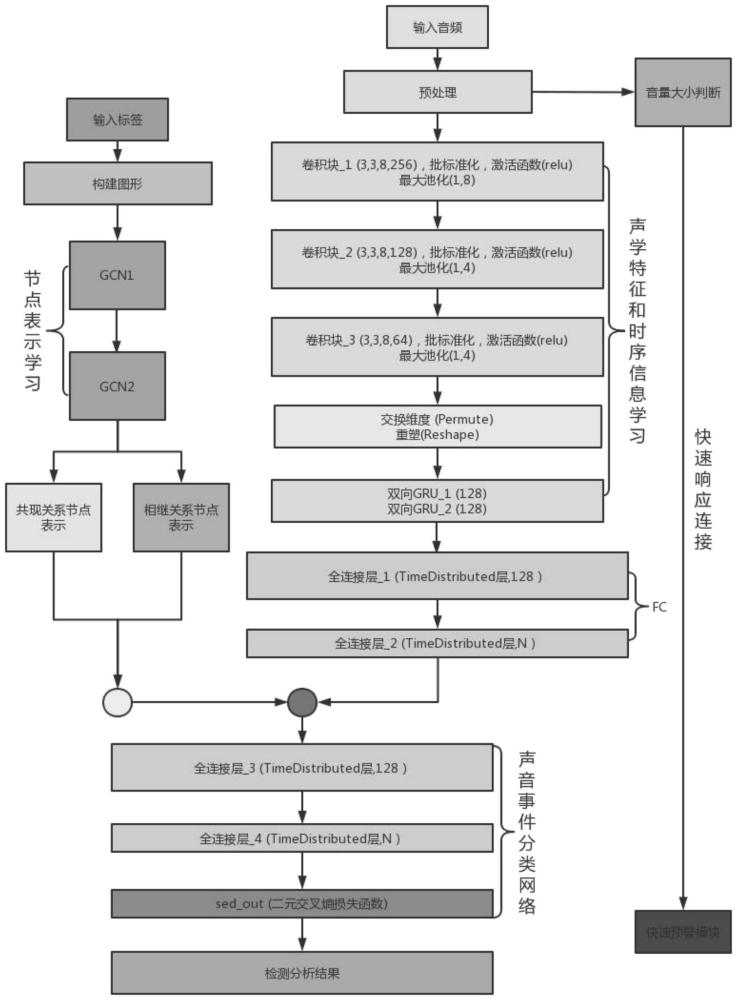
24、最后,将各类声音事件作为节点,将计算出的概率和分别作为声音事件共现关系图和声音事件相继关系图连接这些节点的有向边,完成声音事件共现关系图和声音事件相继关系图构建;
25、步骤2:对声音事件数据集中的音频数据进行预处理,提取特征序列,包括以下步骤:
26、在长度为512并且重叠为50%的汉宁窗上,使用512点快速傅里叶变换从多声道音频的每个c声道提取频谱图;然后提取频谱图的相位和幅度,并将提取出的相位和幅度作为单独的特征,其中幅度值还用于预警技术中的音量大小的判断;
27、步骤2.1:设定音频的采样频率,将音频数据进行分帧处理;
28、步骤2.2:选择窗函数对步骤1得到的分帧后的音频数据进行逐帧的加窗操作;
29、步骤2.3:获取频谱图,并提取相位和幅度;
30、步骤2.3.1:通过快速傅里叶变换将分帧加窗后的音频数据从时域转换到频域上,获取音频数据的频域信号
31、步骤2.3.2:对步骤2.3.1得到的频域信号进行取模操作获得音频数据的幅度谱;
32、步骤2.3.3:对步骤2.3.1得到的频域信号进行取相位角操作获得音频数据的相位谱
33、步骤2.3.4:将步骤2.3.2和步骤2.3.3得到的幅度谱和相位谱合并成,得到特征序列;
34、步骤3:设计声音事件检测模型并进行声音事件检测,包括以下步骤:
35、步骤3.1:设计声学特征学习模块进行声学特征学习;所述声学特征学习模块包括卷积神经网络、双向rnn层和两个fc层;所述卷积神经网络使用三层二维的cnn学习特征序列中的声学特征并输入到双向rnn层;所述双向rnn层用于从cnn输出学习时间上下文信息,并送入到两个fc层;两个fc层进一步提取声音事件的声学特征;
36、将步骤2预处理得到的特征序列作为输入送到卷积神经网络;在卷积神经网络部分,使用三层二维的cnn学习特征序列的声学特征;第一层cnn层有b1个3×3×2c维感受野的滤波器,b1为256,c为4,之后两层cnn层的滤波器数量分别为128,64;三层cnn层的步长和填充均为1,以保证特征序列长度t不变;在每一层cnn的之后,使用批标准化对输出进行标准化,并使用relu函数激活,然后使用沿频率轴的最大池化降低维度,从而保持特征序列长度t不变;三层cnn层使用跨越所有信道的滤波器内核,允许cnn学习时间和频率维度的相关信道内特征;最后一个cnn层的滤波器输出为t×2×b3,即512×2×64,其中的频率维减少为2是最大池化层的效果;在三个cnn层中的每一层之后,频率上的最大池化分别为8,4,4;将三个cnn层输出的特征序列512×2×64交换维度并进一步重塑为长度为2b3的特征向量的t帧序列,即512×128,并将其送入到双向rnn层,该双向rnn层用于从cnn输出学习时间上下文信息;在每一rnn层都使用q个节点的门控循环单元,所述门控循环单元用以提取声音事件的时间上下文信息来获取音频中各类声音事件的时序信息,q的值为128,并使用tanh函数激活,最终输出的特征序列维度与输入保持一致;然后将双向rnn层输出的特征序列送入到两个fc层,进一步提取声音事件的声学特征;第一个fc层包含r个节点,r为128,每个节点都具有线性激活;第二个fc层由n个节点组成,n的值为对应数据集中的声音事件类别数量;最终输出的声学特征的特征序列为512×n;包括以下步骤:
37、步骤3.1.1:创建第一层二维的cnn层,该层的输入为步骤2预处理输出的特征序列512×256×8,使用跨越所有信道的滤波器内核,允许cnn学习时间和频率维度的相关信道内特征,该层有b1个3×3×2c维感受野的滤波器,b1为256,c为4,步长和填充均为1,以保证特征序列长度t不变;经过cnn层之后特征序列变为512×256×256;使用批标准化对cnn层输出进行标准化,并使用relu函数激活,之后使用沿频率轴的最大池化降低维度变为512×32×256,从而保持特征序列长度t不变,频率上的最大池化为1×8;
38、步骤3.1.2:创建第二层二维的cnn层,该层有b2个3×3×8维感受野的滤波器,b2为128,步长和填充均为1,以保证特征序列长度t不变;该层的输入为第一层cnn层输出的特征序列512×32×256,首先通过卷积层,卷积后特征序列维度变为512×32×128,然后使用批标准化对输出进行标准化,并使用relu函数激活,之后经过沿频率轴的最大池化后降低维度变为512×8×128,频率上的最大池化为1×4;
39、步骤3.1.3:创建第三层二维的cnn层,该层有b3个3×3×8维感受野的滤波器,b3为64,步长和填充均为1,以保证特征序列长度t不变;该层的输入为第二层cnn层输出的特征序列512×8×128,首先通过卷积层,卷积后特征序列维度变为512×8×64,然后使用批标准化对输出进行标准化,并使用relu函数激活,之后经过沿频率轴的最大池化降低维度变为512×2×64,频率上的最大池化为1×4;
40、步骤3.1.4:将三层cnn层输出的特征序列512×2×64交换维度变为2×512×64并进一步重塑为长度为2b3的特征向量的t帧序列,即512×128;
41、步骤3.1.5:创建两个双向rnn层,将经过步骤3.1.4重塑后的特征序列送入其中,提取声音事件的时间上下文信息,每一rnn层都使用q个节点的门控循环单元,q为128,并使用tanh函数激活,最终输出的特征序列维度与输入保持一致,即512×128;
42、步骤3.1.6:创建两个fc层,将经过rnn层提取了声音事件时间上下文信息的特征序列送入其中,进行进一步训练;第一个fc层包含r个节点,r为128,每个节点都具有线性激活。第二个fc层由n个节点组成,n的值为对应数据集中的声音事件类别数量。最终输出的声学特征的特征序列为512×n;
43、步骤3.2:设计节点表示学习模块学习两种关系信息的节点表示,包括以下步骤:
44、所述节点表示学习模块使用gcn网络分别学习共现和相继两种关系信息的节点表示,其中和分别代表共现关系的节点表示和相继关系的节点表示;gcn网络使用两个gcn层,每个gcn层将前一层学习到的节点表示或作为输入,学习后输出新的节点表示或第一个gcn层的输入节点表示是标签的词嵌入,其中n表示标签的数量,即数据集中声音事件的种类数,f表示标签字嵌入的维数;对于最后一层,输出为其中o等于声学特征学习模块输出的声学特征的维数;
45、步骤3.2.1:获取步骤1分别构建的声音事件共现关系图和声音事件相继关系图为g=(v,e),其中v包含网络中所有的n个节点,即要检测的n种声音事件,vi∈v,e代表节点之间的边(vi,vi)∈e,节点的特征向量矩阵为其中n为节点数,f为特征向量的维数;
46、步骤3.2.2:为了在聚合邻居信息时同时保留节点自身的信息,为每个节点添加自连接:
47、
48、其中,a表示邻接矩阵,中的元素aij为权重实数;in表示每个节点都添加了自连接,表示每个节点都添加了自连接关系后的邻接矩阵,表示每个添加了自连接之后的度矩阵,度矩阵d=∑jaij;
49、步骤3.2.3:使用参数β来调整节点自身和邻居的权重比:
50、
51、其中,表示调整了自身和邻居权重比之后的邻接矩阵,β用于分配邻居和自身的权重比,β∈[0,1];
52、步骤3.2.4:改进后的gcn网络在层与层之间的传播遵循以下公式:
53、
54、其中,h(l)表示第l层gcn网络的输入,w(l)表示第l层gcn网络待训练的参数,h()表示相应的激活函数。
55、步骤3.2.5:构建第一层gcn层,将节点的特征向量矩阵输入经过上述步骤3.2.4改进后的gcn网络中,学习得到节点表示如下公式所示:
56、
57、步骤3.2.6:构建第二层gcn层,将经过第一层gcn层聚合更新后的节点特征向量矩阵输入其中,学习得到节点表示如下公式所示:
58、
59、最后一层学习到的节点表示作为节点表示学习模块的输出,最终输出的节点表示的特征序列为n×512,其中和分别代表共现关系的节点表示和相继关系的节点表示;
60、步骤3.3:将gcn学习的两种关系信息所输出的节点表示的特征序列n×512均转置为512×n,然后采用两种以下方式进行融合,得到结合后的特征序列:
61、方式一:将获得的两种节点表示学习输出的特征序列和进行一次对应元素相乘,之后再与声学特征学习输出的特征序列做一次对应元素相乘,结合两种节点表示输出与声学特征输出,得到结合后的特征序列512×n;
62、方式二:将两种节点表示输出的特征序列和进行加权结合,使用参数γ来调整两种节点表示输出的特征序列的权重比,结合方式如下:
63、
64、其中,表示经过加权结合后的,同时具有两种关系信息的节点表示的特征序列,参数γ用于调整二者所占的权重比例,随后将经过加权结合后的节点表示与声学特征学习输出的特征序列做一次对应元素相乘,结合两种节点表示输出与声学特征输出,得到结合后的特征序列512×n;
65、步骤3.4:设计声音事件分类网络进行声音事件分类,包括以下步骤:
66、将结合后的特征序列送入声音事件分类网络中进行声音事件分类;所述声音事件分类网络由两个fc层组成;第一个fc层包含r个节点,每个节点都具有线性激活;第二个fc层由n个具有sigmoid激活的节点组成,每个节点对应于要检测的n个声音事件类别中的一个,使用sigmoid激活可以同时激活多个类,并输出分数,使用交叉熵损失函数进行训练,并输出最终的声音分类和检测结果,声音事件检测的输出在[0,1]的连续范围内,当输出超过阈值0.5时,则判断存在该声音事件,对于判断存在的声音事件输出其事件的起止时间和持续时间;
67、步骤4:设计基于音量的快速预警模块进行声音事件预警,包括以下步骤:
68、步骤4.1:通过步骤2.3.2获取的音频信号的幅度值确定声波的振幅并获取当前时刻的音量的大小,将幅度值记为vt,t的值为当前时刻;
69、步骤4.2:基于声音事件检测模型和统计分析确定音量阈值;
70、1)使用音频数据对声音事件检测模型进行训练;
71、2)使用训练好的声音事件检测模型对音频数据进行声音事件检测;
72、3)根据声音事件检测模型的检测结果,统计不同声音事件类别的音量幅度值大小情况并按照声音事件类别进行风险评估和分级,随后对大量数据进行统计分析,选择最优的分级阈值y;
73、步骤4.3:基于获取到幅度值和音量阈值,实现基于大音量的预警;
74、使用音量阈值y进行两个分级,当音频信号的幅度值vt≤y时判断为无风险情况,vt≥y时进行快速的风险警示。
75、采用上述技术方案所产生的有益效果在于:本发明提供的一种基于声音信号的行车事件判断方法,将图神经网络与卷积循环神经网络进行功能融合,针对每一个声音事件使用声音事件关联窗,分别获取了声音事件的共现信息和相继信息,并按照事件的共线关系和相继关系分别构图,该构图方式、两种关系信息独立学习互不干扰,模型可以有效获取两种不同的关系信息,相对于传统的共现方法更加全面,同时也有效缓解了传统共现方法所面临的稀疏图问题,使声音事件检测任务能够获取到更多的先验知识。有效提高复调声音事件的分类和检测的能力。同时本技术还将行车过程中突然出现的大音量噪声作为可能的危机信息,利用音量的实时检测在行车过程中进行高实时性的预警的技术。该技术实时性很高且几乎不增加运算量,可以在声音事件检测结果出来之前进行更加快速的预警和响应,降低风险,并为具体危机事件的分析和检测提供时间。
- 还没有人留言评论。精彩留言会获得点赞!