一种基于特征嵌入和平滑策略的高保真手部化身生成方法
本发明涉及了三维重建领域中的一种手部化身生成方法,具体涉及了一种基于特征嵌入和部分感知平滑策略的高保真手部化身生成方法。
背景技术:
1、手部化身在数字应用中扮演着关键角色,特别是在虚拟现实、数字娱乐和人机交互等领域,它们增强了用户的沉浸感并促进了虚拟环境中的自然交互。
2、尽管以往的研究集中于逼真的手部渲染,但很少关注手部几何形状的精细重建,而手部几何形状的精细度对于高质量的渲染是至关重要的。现有技术通常依赖于基于网格的表示,这些表示受到固定拓扑和有限分辨率的限制,难以准确表示细节。新兴的神经隐式表示技术在合成静态场景的新视图方面显示出强大的能力,一些研究已将这些方法扩展到人体等可运动物体的领域,以促进逼真渲染,然而这些神经隐式表示的技术需要大量的时间资源损耗才能实现逼真的渲染。在扩展现实和游戏领域,对于即时渲染的要求是非常看重的,这就要求技术能够在保持高渲染质量的同时实现快速响应。
3、总的来说,现有技术在高保真手部化身生成领域存在以下缺陷:
4、1、现有技术在恢复手部细节几何形状方面存在困难,这些细节在逼真渲中起着关键作用。
5、2、尽管一些方法能够实现实时渲染,但它们通常无法捕捉到手部网格的精细细节,导致渲染效果缺乏真实感。而某些高质量渲染的方法在训练过程中需要大量的时间,这限制了它们在实时应用中的可行性。
6、3、现有方法难以泛化到未见过的姿势和形状,这限制了它们的应用范围。
技术实现思路
1、为了解决背景技术中存在的问题,本发明提供了一种基于特征嵌入和部分感知平滑策略的高保真手部化身生成方法,用于获取富有细节纹理的手部几何结构和高保真的手部渲染图像,同时能实现各种手部姿势的实时响应,生成各种手部姿势的实时动画效果,能够用于虚拟现实、增强现实、游戏、人机交互和其他数字环境中,以增强用户的沉浸感和实现自然交互。
2、本发明采用的技术方案包括如下步骤:
3、一、一种基于特征嵌入和平滑策略的高保真手部化身生成方法
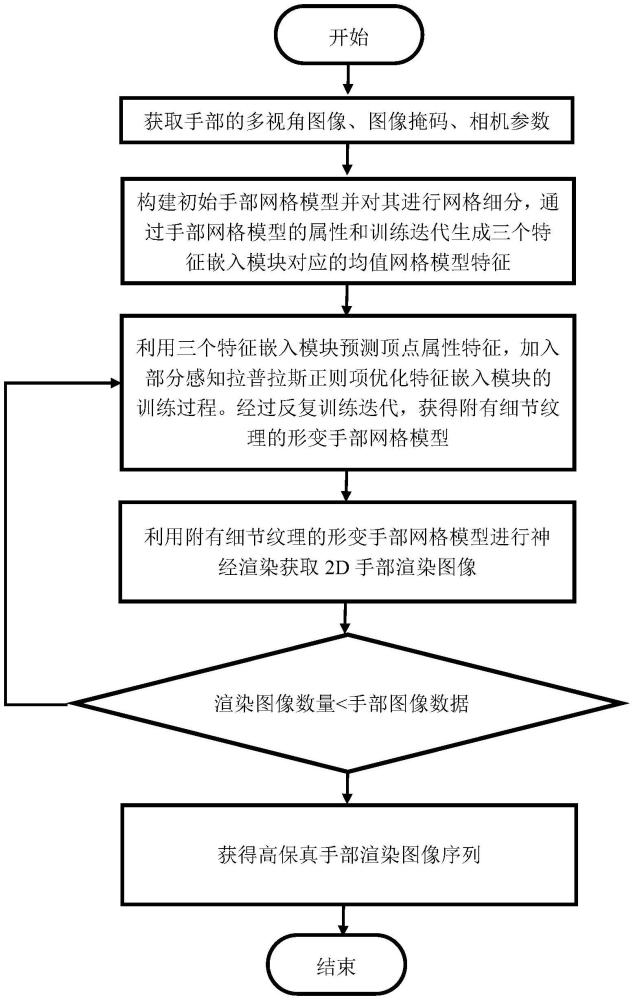
4、s1:获取多视角手部图像数据集,数据集中包含不同视角下的多个手部图像样本;
5、s2:根据一个手部图像样本构建初始手部网格模型以及生成三个特征嵌入模块对应的均值网格模型特征;
6、s3:基于初始手部网格模型和三个特征嵌入模块对应的均值网格模型特征,利用多视角手部图像数据集对三个特征嵌入模块和神经网络渲染器分别进行训练后,获得优化的三个特征嵌入模块和最终的神经网络渲染器以及更新的手部网格模型;
7、s4:对于实际手部图像序列,结合当前手部网格模型,根据一张手部图像对当前三个特征嵌入模块进行迭代训练后,获得优化的三个特征嵌入模块以及更新的手部网格模型;再利用最终的神经网络渲染器对更新的手部网格模型进行图像渲染后,获得该手部图像对应的高保真的2d手部渲染图像;
8、s5:重复s4,对实际手部图像序列中的其他手部图像依次进行图像渲染后,获得对应的高保真的2d手部渲染图像,从而获得手部渲染图像序列。
9、所述s2具体为:
10、s2.1:根据当前手部图像样本中的掩码后图像和姿势参数,构建初始手部网格模型,以及将初始手部网格模型的线性混合蒙皮权重作为第一特征嵌入模块的均值网格模型特征;
11、s2.2:结合球谐函数和当前视角下的相机参数,利用初始手部网格模型构建第二特征嵌入模块对应的均值网格模型特征和第三特征嵌入模块对应的均值网格模型特征。
12、所述s3具体为:
13、s3.1:根据当前手部图像样本、三个特征嵌入模块对应的均值网格模型特征,结合当前手部网格模型,对三个特征嵌入模块分别进行训练迭代后,获得三个训练完成的特征嵌入模块以及更新手部网格模型;
14、s3.2:根据当前手部网格模型以及第二特征嵌入模块和第三特征嵌入模块对应的最优潜空间特征向量,对当前神经网络渲染器进行训练迭代后,获得更新的神经网络渲染器;
15、s3.3:基于最新的特征嵌入模块、手部网格模型、神经网络渲染器,重复s3和s4,利用多视角手部图像数据集中的其他手部图像样本对三个特征嵌入模块、手部网格模型和神经网络渲染器进行训练后,获得最终三个特征嵌入模块、手部网格模型、神经网络渲染器。
16、所述s2.1具体为:
17、根据一个视角下的掩码后图像及其对应的姿势参数,利用mano模型构建原始网格模型,再通过细分方法提高原始网格模型的分辨率,生成初始手部网格模型,将初始手部网格模型的线性混合蒙皮权重作为第一特征嵌入模块的均值网格模型特征。
18、所述s2.2具体为:
19、初始化手部顶点偏移的特征向量以及顶点反照率的特征向量,再结合球谐函数和当前视角下的相机参数,对初始手部网格模型进行渲染后得到第一2d手部图像,根据第一2d手部图像和当前视角下的掩码后图像计算的第一损失值对手部顶点偏移的特征向量以及顶点反照率的特征向量进行训练迭代,直至训练结束,获得最优的手部顶点偏移的特征向量以及顶点反照率的特征向量,将最优的手部顶点偏移的特征向量作为第二特征嵌入模块的均值网格模型特征、最优的顶点反照率的特征向量作为第三特征嵌入模块的均值网格模型特征。
20、所述s3.1具体为:
21、s3.1.1:根据当前视角下的手部姿势、均值网格模型特征和当前潜空间特征向量,利用三个特征嵌入模块分别预测手部顶点偏移、顶点反照率和线性混合蒙皮权重,再根据预测获得手部顶点偏移、顶点反照率和线性混合蒙皮权重对当前手部网格模型进行优化,获得优化后的手部网格模型;
22、s3.1.2:渲染优化后的手部网格模型后,获得第二2d手部图像;
23、s3.1.3:根据第二2d手部图像和当前视角下的掩码后图像计算第二损失值,根据第二损失值对三个特征嵌入模块的潜空间特征向量进行调整并更新;
24、s3.1.4:重复s3.1.1-s3.1.3,对三个特征嵌入模块的潜空间特征向量训练迭代,直至训练结束,获得三个特征嵌入模块对应的最优潜空间特征向量以及最优的手部网格模型并更新。
25、所述s3.1中,每个特征嵌入模块均包括姿势解码器,将当前视角下的手部姿势和对应的潜空间特征向量q拼接后再输入到姿势解码器中,姿势解码器的输出与映射矩阵相乘后再与对应的均值网格模型特征相加后的结果作为当前特征嵌入模块的预测输出。
26、所述s3.2具体为:
27、s3.2.1:利用第二特征嵌入模块和第三特征嵌入模块对应的最优潜空间特征向量构建神经网络渲染器,神经网络渲染器的渲染过程如下:
28、c(πi)=c(x,n,h,d)
29、h=concat(qd,qρ,qrender)
30、其中,c(πi)是从第i个视点的相机参数πi合成的图像,c()为渲染函数,x、n分别是通过交点处的三角面片顶点插值得到的位置和法线,d是射线方向,h是融合特征向量,concat()表示拼接操作,qd和qρ分别为第二特征嵌入模块和第三特征嵌入模块对应的最优潜空间特征向量;qrender为用于神经渲染的特征向量;
31、s3.2.2:根据神经网络渲染器渲染获得的2d手部渲染图像与当前视角下的掩码后图像的损失对神经网络渲染器进行训练迭代,训练完成后获得更新的神经网络渲染器。
32、所述s3.1.3中,第二损失值包含拉普拉斯平滑损失值计算公式如下:
33、
34、a=l*f=[a1,a2,...,ai]
35、
36、其中,a是拉普拉斯特征矩阵,φplap是分层权重,l是拉普拉斯矩阵,f是顶点属性的特征,a1,a2,ai分别是拉普拉斯特征矩阵的第1个、第2个、第i个特征值,p1和p2分别是第一和第二阈值,γ1、γ2和γ3分别是第一-第三平衡系数。
37、所述s3.2.2中,神经网络渲染器渲染获得的2d手部渲染图像与当前视角下的掩码后图像的损失的具体公式如下:
38、
39、其中,c(πi)是从第i个视点的相机参数πi合成的图像,‖‖1表示l1范数,表示图像相似性损失项,w是第三权重,ii是当前视角下的掩码后图像。
40、二、一种计算机设备
41、所述设备包括存储器和处理器,所述存储器存储有计算机程序,所述处理器执行所述计算机程序时实现所述方法的步骤。
42、三、一种计算机可读存储介质
43、所述介质上存储有计算机程序,所述计算机程序被处理器执行时实现所述方法的步骤。
44、本发明的有益效果是:
45、通过采取上述技术方案,本发明方法能够捕捉到手部的精细几何细节,包括肌肉、皮肤褶皱等,能够实现手部化身的实时渲染,同时保持高保真的视觉效果,这对于需要快速响应和高质量图像的应用场景至关重要。
46、本发明引入了部分感知拉普拉斯正则化,以消除不需要的伪影,同时通过不同级别的规则化来保持细节。在基于多视图视频输入的手部图像数据训练下,本发明能够生成不同姿势的手部化身,有较高的实用性和泛化能力。
- 还没有人留言评论。精彩留言会获得点赞!