一种样本优选方法、装置、终端设备及介质
本发明涉及大模型,特别涉及一种样本优选方法、装置、终端设备及介质。
背景技术:
1、随着大语言模型的不断发展,以chatgpt和gpt-4为代表的大语言模型在全球范围内引起了广泛关注,这些大语言模型能够支持人类以自然语言的形式表达任务和要求,并且能够高效地理解输入的文本指令(提示语),生成符合要求的文本输出。大语言模型具有上下文学习的能力,并不需要对模型参数进行调整,能够通过分析少量示例来掌握新任务的解决策略,例如,通过在测试问题之前提供一系列问题示例及其对应的期望结果,可以构建出引导模型正确响应的提示,因而示例的数量和类型在提示语中对模型性能具有显著影响。
2、目前,在针对大语言模型进行示例样本优先时,通常仅考虑了每个示例与待解决问题之间的单独相似度进行选择,并未涉及示例之间相互作用对模型效果的潜在影响,导致大语言模型性能较差,因此,本发明提出一种样本优选方法、装置、终端设备及介质,采用了shapley近似计算进行样本优选,考量了示例之间相互作用对模型效果的潜在影响,使得优选样本能够更好的引导模型正确响应的提示,提高大语言模型性能,同时还能够减少shapley计算,提高shapley计算效率。
技术实现思路
1、本发明的目的在于提供一种样本优选方法、装置、终端设备及介质,以解决上述背景技术中提出的问题。
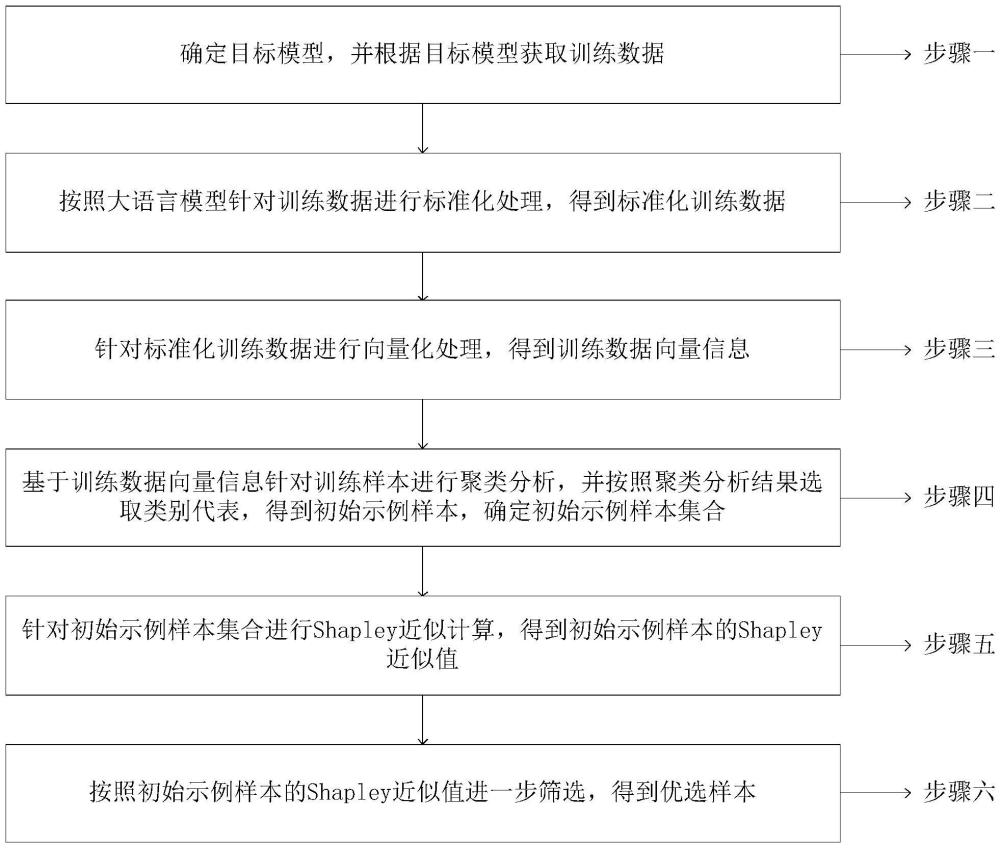
2、为实现上述目的,本发明提供如下技术方案:一种样本优选方法,包括:
3、确定目标模型,并根据目标模型获取训练数据;
4、按照大语言模型针对训练数据进行标准化处理,得到标准化训练数据;
5、针对标准化训练数据进行向量化处理,得到训练数据向量信息;
6、基于训练数据向量信息针对训练样本进行聚类分析,并按照聚类分析结果选取类别代表,得到初始示例样本,确定初始示例样本集合;
7、针对初始示例样本集合进行shapley近似计算,得到初始示例样本的shapley近似值;
8、按照初始示例样本的shapley近似值进一步筛选,得到优选样本。
9、优选地,所述训练数据包括:基本数据信息、历史数据信息和结果数据信息,按照大语言模型针对训练数据进行标准化处理时,基于标准化模板针对训练数据进行标准化处理,其中,标准化模板包括:第一转化模板、第二转化模板和第三转换模板,当采用第一转化模板针对基本信息进行标准化处理时,针对基本数据信息进行特征提取,得到基本特征信息,并按照固定序列针对基本特征信息进行列举排列,得到基本特征信息序列;当采用第二转化模板针对历史数据信息进行标准化处理时,通过列举的方式将历史数据信息转化为自然文本描述;当采用第三转化模板针对结果数据信息进行标准化处理时,根据结果数据信息进行二值化处理,得到结果数据信息标准化数值。
10、优选地,针对标准化训练数据进行向量化处理时,采用文本向量化模型针对标准化训练数据按照样本依次进行向量化处理,将标准化训练数据转换成向量形式,得到训练数据向量信息,其中,文本向量化模型针对初始示例集合中的每个示例进行向量化处理之前进行模型学习训练。
11、优选地,基于训练数据向量信息针对训练样本进行聚类分析,包括:
12、针对训练样本确定聚类特征,并根据训练数据向量信息分析训练样本的分布情况;
13、确定聚类类别数目;
14、基于聚类类别数目结合训练数据向量信息确定初始聚类中心;
15、根据训练数据向量信息进行聚类分析与初始聚类中心优化,得到聚类分析结果。
16、优选地,按照聚类分析结果选取类别代表时,确定初始示例样本集合的大小,并分析初始示例样本集合的大小与聚类分析结果中聚类类别数目之间的关系,当初始示例样本集合的大小等于聚类分析结果中聚类类别数目时,按照聚类分析结果从每个聚类中选取类别代表,当初始示例样本集合的大小大于聚类分析结果中聚类类别数目时,将初始示例样本集合的大小按照划分规则分为第一数值和第二数值,按照第一数值从每个聚类中选取类别代表,然后分析聚类分析结果中聚类类别的大小,按照聚类类别的大小进行筛选,得到聚类类别筛选结果,并在聚类类别筛选结果中按照第二数值从聚类类别筛选结果的每个聚类类别中选取类别代表;
17、按照聚类分析结果选取类别代表时,还从聚类分析结果中选取目标数目个训练样本作为验证示例样本集合。
18、优选地,针对初始示例样本集合进行shapley近似计算,包括:
19、确定截断阈值;
20、初始化每个初始示例样本的shapley值;
21、依次将每个初始示例样本作为研究对象,针对初始示例样本集合中剩余的初始示例样本进行全排列,得到研究对象的分析序列;
22、遍历研究对象的分析序列进行序列子元素分析,并结合截断阈值针对分析结果进行判断,得到序列子元素的结果准确率;
23、根据序列子元素的结果准确率进行shapley值计算,得到研究对象的shapley近似值。
24、优选地,按照初始示例样本的shapley近似值进一步筛选,包括:
25、将初始示例样本的shapley近似值按照大小进行排列,得到待筛选序列;
26、确定优选样本目标数目;
27、按照优选样本目标数目针对待筛选序列按照顺序进行筛选,得到目标子数据;
28、根据目标子数据进行训练数据追溯,得到优选样本。
29、一种样本优选装置,包括:数据获取模块、第一处理模块、第二处理模块、聚类分析模块、分析计算模块和样本筛选模块;
30、所述数据获取模块,用于确定目标模型,并根据目标模型获取训练数据;
31、所述第一处理模块,用于按照大语言模型针对训练数据进行标准化处理,得到标准化训练数据;
32、所述第二处理模块,用于针对标准化训练数据进行向量化处理,得到训练数据向量信息;
33、所述聚类分析模块,用于基于训练数据向量信息针对训练样本进行聚类分析,并按照聚类分析结果选取类别代表,得到初始示例样本,确定初始示例样本集合;
34、所述分析计算模块,用于针对初始示例样本集合进行shapley近似计算,得到初始示例样本的shapley近似值;
35、所述样本筛选模块,用于按照初始示例样本的shapley近似值进一步筛选,得到优选样本。
36、本发明采用了shapley计算实现对目标模型的样本选择,使得在确定大语言模型的示例样本时,充分考虑不同样本示例间的相互影响,利用shapley值实现样本示例的量化分析,从而使得可以根据更直观的数据筛选出更好的样本示例,进而使得大语言模型在针对目标模型的结果进行提示语重组时能够基于样本示例更好的引导模型进行正确响应提示,提高大语言模型性能,而且采用的是shapley近似计算,使得在初始样本集合较大时能够在误差允许范围内有效减小计算工作量,提高shapley近似计算的效率。
37、本发明的其它特征和优点将在随后的说明书中阐述,并且,部分地从说明书中变得显而易见,或者通过实施本发明而了解。本发明的目的和其他优点可通过在所写的说明书、权利要求书、以及附图中所特别指出的结构来实现和获得。
38、下面通过附图和实施例,对本发明的技术方案做进一步的详细描述。
- 还没有人留言评论。精彩留言会获得点赞!