大模型推理引擎的参数调优方法及装置与流程
本说明书一个或多个实施例涉及计算机,尤其涉及一种大模型推理引擎的参数调优方法及装置。
背景技术:
1、大模型,主要指大语言模型(large language model,简称llm),因其在许多预测任务中表现出色,已被许多服务方(或称服务方应用)使用,以期为用户提供优质服务。
2、然而,大模型的参数量巨大,如可以达到数百甚至上千亿,这导致了非常高昂的推理开销。例如,为了容纳如此庞大的参数量,需要使用大显存的高端gpu或者多个高端gpu,这就带来了非常高昂的设备购买和运维成本。又例如,由于llm独特的自回归式生成机制和键值对缓存机制,在llm推理过程中,gpu的计算效率较低。
3、对此,业界提出利用大模型推理引擎(下文或简称推理引擎)来优化模型推理过程,从而在相同的计算资源下,利用大模型处理由服务方应用发起的更多推理请求,也就降低了每个请求的平均成本。具体地,推理引擎是专门用于加载和运行大模型推理的软件系统,如图1所示,上层应用向推理引擎发起推理请求,大模型推理引擎调度大模型对推理请求进行处理,例如,从推理请求中提取内容作为大模型的输入,再将大模型的输出作为推理请求的响应数据或处理结果,反馈给上层应用。举例来说,推理引擎在调度大模型的过程中,可以采用持续批处理(continuous batching)、分页注意力(paged attention)和分块填充(chunked prefill)等技术来提高llm模型的推理速度和吞吐量。
4、大模型推理引擎通常有一些需要配置的参数,例如,是否启用分页注意力、是否启用分块填充、块大小、最大批处理字符数等。这些参数的配置直接影响模型推理性能。
5、因此,需要一种参数调优方案,可以确定出最优或逼近最优的参数配置,从而提高乃至最大化推理引擎性能,有效降低推理请求的处理成本。
技术实现思路
1、本说明书实施例描述一种大模型推理引擎的参数调优方法及装置,可以确定出最优或逼近最优的参数配置。
2、根据第一方面,提供一种大模型推理引擎的参数调优方法,所述大模型推理引擎用于运行目标大模型以处理目标应用发起的推理请求。该调优方法包括:
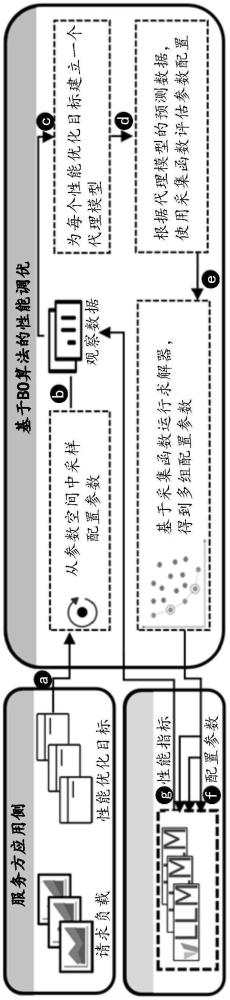
3、获取多个观测样本,其中各观测样本包括一组配置参数,以及根据该组参数配置所述大模型推理引擎后,对所述目标应用的历史推理请求进行重放而确定的引擎性能指标。利用所述多个观测样本初始化bo算法中的观测数据,以及,将所述bo算法中的目标函数定义为配置参数和引擎性能指标之间的映射关系,从而执行所述bo算法,得到使引擎性能指标发生优化的若干组配置参数。
4、在一些实施例中,获取多个观测样本,包括:获取所述目标应用的请求负载,其中包括历史推理请求对应的模型输入和输出信息;从参数空间中采样多组配置参数,根据其中各组配置参数分别配置所述大模型推理引擎并重放所述请求负载,从而根据大模型推理引擎的各次运行数据确定对应的引擎性能指标;基于所述各组配置参数和其对应的引擎性能指标,构建出所述多个观测样本。
5、进一步,在一些具体的实施例中,从参数空间中采样多组配置参数,包括:采用基于sobol序列的准蒙特卡洛算法,从所述参数空间中采样出所述多组参数配置。
6、在一些实施例中,其中引擎性能指标的类型由所述目标应用提供。
7、在一些实施例中,所述目标应用为离线应用,所述引擎性能指标包括吞吐量指标;或者,所述目标应用为在线非交互式应用,所述引擎性能指标包括尾部时延;或者,所述目标应用为在线交互式应用,所述引擎性能指标包括首字时间ttft和每字时间tpot。
8、在一些实施例中,执行所述bo算法涉及多轮次迭代更新,其中任一轮次迭代更新包括:基于当前的观测数据训练用于拟合所述目标函数的代理模型。以最大化预设的采集函数的函数值为目标,确定待评估的新配置参数;其中,所述采集函数的输入为所述代理模型的输出。根据所述新配置参数配置所述大模型推理引擎并重放所述历史推理请求,从而根据运行数据得到对应的引擎性能指标。利用由所述新配置参数和对应的引擎性能指标构建的观测样本,更新所述观测数据。
9、进一步,在一些具体的实施例中,其中引擎性能指标的指标类型为1个,所述采集函数的个数为多个;其中,以最大化预设的采集函数的函数值为目标,确定待评估的新配置参数,包括:以最大化所述多个采集函数对应的多个函数值为多个目标,采用多目标优化算法得到pareto前沿解集;基于所述pareto前沿解集,确定所述待评估的新配置函数。
10、在另一些具体的实施例中,其中引擎性能指标的指标类型为多个,所述采集函数为期望超体积改进ehvi。
11、在又一些具体的实施例中,在执行所述bo算法之前,所述方法还包括:获取多个可行性样本,其中各个样本包括一组配置参数,以及根据该组配置参数配置所述大模型推理引擎后,重放所述历史推理请求而确定的可行性标签,该标签指示引擎运行是否发生异常。
12、其中任一轮次迭代更新中还包括:基于当前的可行性数据训练预测模型,所述可行性数据初始包括所述多个可行性样本;其中,所述预测模型用于限制所述新配置参数的可行性概率大于或等于概率阈值。根据所述运行数据确定所述新配置参数对应的可行性标签,并利用由所述新配置参数和对应的可行性标签构建出的可行性样本,更新所述可行性数据。
13、更进一步,在一些例子中,所述任一轮次迭代更新还包括:在本轮确定的可行性样本中包含不可行样本的情况下,提高当前的概率阈值;或者,在含本轮在内的连续预定轮次确定的可行性样本均为可行样本的情况下,降低当前的概率阈值。
14、另一方面,在再一些具体的实施例中,根据所述新配置参数配置所述大模型推理引擎并重放所述历史推理请求,包括:根据给定的并行度k,从所述新配置参数中选取k组配置参数进行并行评估。
15、根据第二方面,提供一种大模型推理引擎的参数调优装置,所述大模型推理引擎用于运行目标大模型以处理目标应用发起的推理请求。所述调优装置包括:样本获取模块,配置为获取多个观测样本,其中各观测样本包括一组配置参数,以及根据该组参数配置所述大模型推理引擎后,对所述目标应用的历史推理请求进行重放而确定的引擎性能指标。算法执行模块,配置为利用所述多个观测样本初始化bo算法中的观测数据,以及,将所述bo算法中的目标函数定义为配置参数和引擎性能指标之间的映射关系,从而执行所述bo算法,得到使引擎性能指标发生优化的若干组配置参数。
16、根据第三方面,提供了一种计算机可读存储介质,其上存储有计算机程序,当该计算机程序在计算机中执行时,令计算机执行第一方面提供的方法。
17、根据第四方面,提供了一种计算设备,包括存储器和处理器,所述存储器中存储有可执行代码,该处理器执行所述可执行代码时,实现第一方面提供的方法。
18、综上,采用本说明书实施例披露的上述方法及装置,使用bo算法来适应不同类应用关注的优化目标,可以精准、高效地确定出性能最优或逼近最优的配置参数,从而降低推理引擎处理请求的计算资源和耗时,降低平均成本。
- 还没有人留言评论。精彩留言会获得点赞!