一种基于大模型的知识点提取方法及系统与流程
本发明涉及文本提取,特别是涉及一种基于大模型的知识点提取方法及系统。
背景技术:
1、基于大型模型的知识点提取方法利用了近年来在自然语言处理领域取得的重大突破,其中包括了深度学习、自然语言理解和表示学习等技术。这些方法旨在从海量的文本数据中自动提取出有意义的知识点,以帮助人们更好地理解和利用文本信息。随着大型预训练语言模型(如gpt、bert等)的出现,研究人员和工程师们开始探索如何利用这些模型来实现更加精确和高效的知识点提取。这些大型模型通过在大规模语料库上进行预训练,可以学习到丰富的语言知识和语义表示,从而能够更好地理解和分析文本数据。
2、但是,传统的知识点提取方法通常需要依赖手工设计的特征来表示文本,这些特征可能无法充分捕捉文本的复杂语义信息,导致提取的知识点不够全面和准确,同时传统方法在处理长文本和复杂语境时往往表现不佳,难以充分挖掘文本中的丰富语义信息,并且传统方法在处理语义关联和上下文理解方面存在局限性,无法充分考虑词语之间的复杂语义关系,导致提取出来的知识点难以满足对文本理解的高要求。
技术实现思路
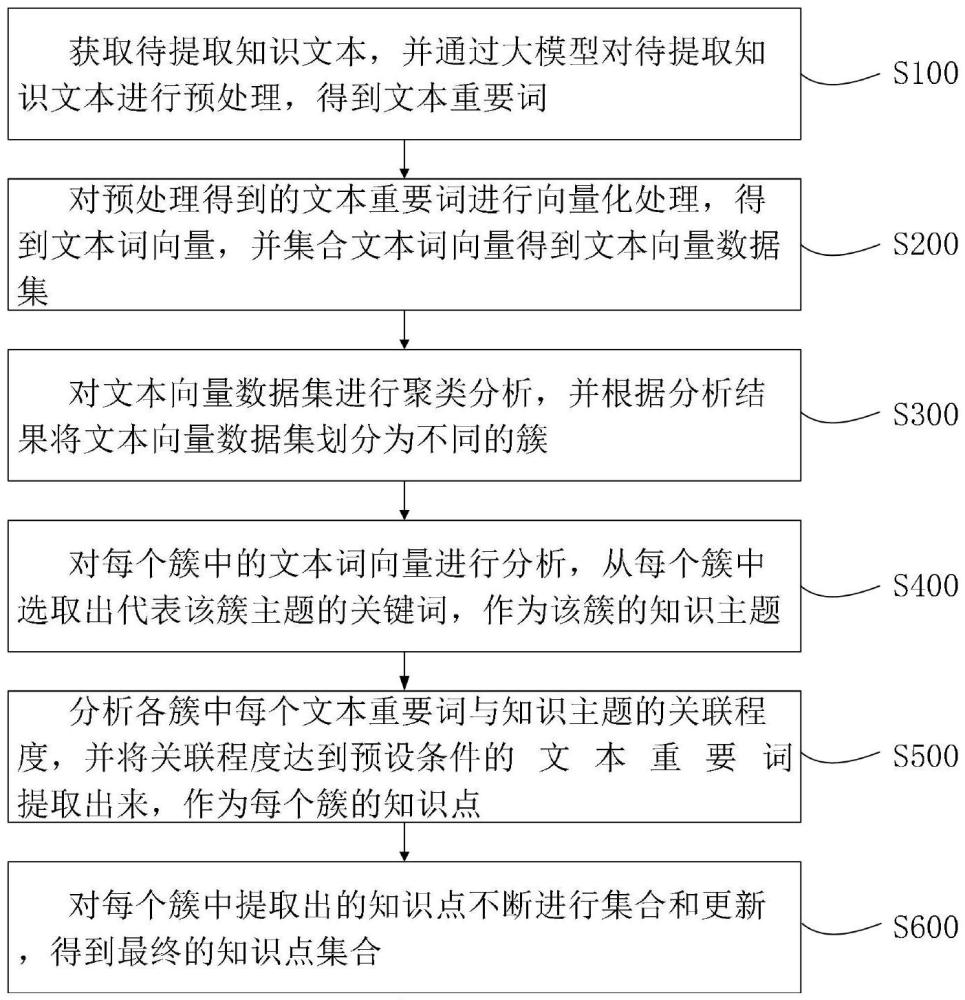
1、为了解决上述技术问题,本发明提供了一种基于大模型的知识点提取方法及系统,包括:
2、获取待提取知识文本,并通过大模型对待提取知识文本进行预处理,得到文本重要词;
3、对预处理得到的文本重要词进行向量化处理,得到文本词向量,并集合文本词向量得到文本向量数据集;
4、对文本向量数据集进行聚类分析,并根据分析结果将文本向量数据集划分为不同的簇;
5、对每个簇中的文本词向量进行分析,从每个簇中选取出代表该簇主题的关键词,作为该簇的知识主题;
6、分析各簇中每个文本重要词与知识主题的关联程度,并将关联程度达到预设条件的文本重要词提取出来,作为每个簇的知识点;
7、对每个簇中提取出的知识点不断进行集合和更新,得到最终的知识点集合。
8、进一步的,所述通过大模型对待提取知识文本进行预处理,包括:
9、通过大模型对待提取知识文本进行清洗,去除待提取知识文本中的特殊字符、标点符号和html标签,并对待提取知识文本进行去噪处理;
10、通过大模型对去噪处理后的待提取知识文本进行分词处理,将文本分割成单词;
11、通过大模型去除分词处理后单词中的停用词,并对剩余的单词进行词性分析和句法分析,确定与知识点相关的文本重要词;
12、将确定出的文本重要词进行标准化处理。
13、进一步的,所述对剩余的单词进行词性分析和句法分析,确定与知识点相关的文本重要词,包括:
14、获取剩余单词的词性,并判断剩余单词的词性类型,根据预先设定的预设词性-分数映射关系,确定剩余单词的第一分数;
15、获取剩余单词所在句子的结构,并判断句子的结构类型,根据预先设定的预设句子结构-分数映射关系,确定剩余单词的第二分数;
16、将第一分数与第二分数进行相加计算,得到剩余单词的总分数;
17、将总分数超出预设分数阈值的剩余单词筛选出来,确定为与知识点相关的文本重要词。
18、进一步的,所述对预处理得到的文本重要词进行向量化处理,得到文本词向量,并集合文本词向量得到文本向量数据集,包括:
19、通过词嵌入技术将预处理得到的文本重要词映射到连续向量空间,在连续向量空间内将文本重要词转换为低维稠密的文本词向量;
20、将转换后得到的文本词向量进行集合,得到文本向量数据集。
21、进一步的,所述对文本向量数据集进行聚类分析,并根据分析结果将文本向量数据集划分为不同的簇,包括:
22、获取文本向量数据中文本词向量的数量,并根据文本词向量的数量确定要划分的簇的个数;
23、预先设定若干个距离区间,并基于k-means聚类算法确定每个文本词向量到聚中心的距离值;
24、判断每个文本词向量到聚中心的距离值所处的距离区间,并将距离值处于不同的距离区间的文本词向量归于不同的簇内,完成将文本向量数据集划分为不同的簇。
25、进一步的,所述对每个簇中的文本词向量进行分析,从每个簇中选取出代表该簇主题的关键词,作为该簇的知识主题,包括:
26、确定各簇中每个文本词向量对应的文本重要词,并分析各簇中每个文本重要词的含义,根据含义对每个文本重要词打上相应的信息标签;
27、提取各文本重要词每个信息标签的关键词,将出现次数最多的关键词选取出来代表该簇主题的关键词,并作为该簇的知识主题。
28、进一步的,所述分析各簇中每个文本重要词与知识主题的关联程度,并将关联程度达到预设条件的文本重要词提取出来,作为每个簇的知识点,包括:
29、获取每个文本重要词在对应簇中的出现频次,并出现频次作为每个文本重要词的系数;
30、将知识主题用向量进行表示,得到知识主题向量,并分别计算每个文本词向量与知识主题向量的相关度;
31、基于每个文本重要词的系数和每个文本词向量与知识主题向量的相关度计算每个文本重要词与知识主题的关联程度;
32、将关联程度超出预设关联阈值的文本重要词提取出来,作为每个簇的知识点。
33、进一步的,所述每个文本重要词与知识主题的关联程度的计算公式为:
34、l=g/1-α,
35、其中,l为每个文本重要词与知识主题的关联程度,g为每个文本词向量与知识主题向量的相关度,α为每个文本重要词的系数。
36、本发明还提供了一种基于大模型的知识点提取系统,包括:
37、获取模块,用于获取待提取知识文本,并通过大模型对待提取知识文本进行预处理,得到文本重要词;
38、处理模块,用于对预处理得到的文本重要词进行向量化处理,得到文本词向量,并集合文本词向量得到文本向量数据集;
39、划分模块,用于对文本向量数据集进行聚类分析,并根据分析结果将文本向量数据集划分为不同的簇;
40、选取模块,用于对每个簇中的文本词向量进行分析,从每个簇中选取出代表该簇主题的关键词,作为该簇的知识主题;
41、提取模块,用于分析各簇中每个文本重要词与知识主题的关联程度,并将关联程度达到预设条件的文本重要词提取出来,作为每个簇的知识点;
42、整合模块,用于对每个簇中提取出的知识点不断进行集合和更新,得到最终的知识点集合。
43、本发明实施例一种基于大模型的知识点提取方法及系统与现有技术相比,其有益效果在于:
44、本发明通过使用大型模型进行文本预处理,可以有效地识别文本中的重要词汇,并且可以根据具体的文本内容和语境来提取关键词,从而更好地反映文本的主题和内容;
45、本发明词向量的向量化处理可以通过词嵌入模型来实现,这些模型可以帮助将文本中的词汇转换为具有语义信息的向量表示,该向量表示可以更好地捕捉词汇之间的语义关系,从而更好地表达文本的语义信息;
46、本发明对文本向量数据集进行聚类分析可以帮助将文本数据划分为不同的簇,从而更好地理解文本数据的结构和主题;
47、本发明通过关键词提取技术选取代表簇主题的关键词,可以帮助更好地理解每个簇的主题和内容,为后续的知识点提取提供基础;
48、本发明分析文本重要词与知识主题的关联程度可以帮助确定哪些词汇更加重要,并且更好地反映了文本重要词与知识主题之间的关联,帮助提取出最具代表性的知识点;
49、本发明对于提取出的知识点,通过集合和更新可以帮助得到更加完备和准确的知识点集合,有助于更好地理解文本数据的内容和主题。
- 还没有人留言评论。精彩留言会获得点赞!