一种基于视听融合的机器人室内易混淆行为类识别方法与流程
本发明属于服务机器人感知,特别涉及室内服务机器人的视觉与听觉信息融合处理,为一种基于视听融合的机器人室内易混淆行为类识别方法,用于提高在复杂室内环境中对易混淆人类行为的识别准确性。
背景技术:
1、服务机器人在医院、养老院、家庭等室内环境中的应用日益广泛,它们需要具备对人类行为的准确识别能力,以便提供及时的响应和服务。在医疗和护理场景中,及时检测和响应病理性行为(如打喷嚏、咳嗽)对于监控患者健康状况至关重要;同时,对于老年人和儿童等群体,突发性意外行为(如跌倒、撞击)的快速识别和反应可以极大减少伤害风险。
2、目前,服务机器人在病理性行为、意外事件检测领域所用的主要技术包括:(1)基于人体关键点的姿态估计:姿态估计技术通常依赖于计算机视觉中的人体姿态估计算法,使用卷积神经网络(cnn)对图像中的人物进行特征提取,并通过递归神经网络(rnn)或图卷积网络(gcn)来预测人体关键点的位置。模型需要在包含各种病理性行为姿态的数据集上进行训练,例如,咳嗽、打喷嚏、跌倒等。通过分析关键点的变化,机器人能够识别出人体姿态的异常,如剧烈的咳嗽动作或不稳定的步态,从而判断是否存在病理性行为。(2)面部识别与表情分析:该类算法首先需要使用面部检测算法来定位视频中的人脸,而后通过分析面部视频流,使用深度学习算法来识别特定的面部表情或动作,这些可能与病理性行为相关。例如,打哈欠通常涉及嘴巴的张开和面部肌肉的伸展。该类算法使得服务机器人能够实时处理视频流,并快速响应检测到的表情变化。(3)声音识别与声学事件检测:该类算法需要使用高质量的麦克风阵列来捕捉环境声音,并通过梅尔频率倒谱系数(mfcc)等声学特征提取方法,将声音信号转换为机器可理解的特征向量,随后再进行分类。利用声音识别技术来检测特定的声响,如咳嗽或打喷嚏的声音。声学事件检测算法可以被设计来识别突发性声音事件,如跌倒或撞击产生的声音。(4)多模态融合技术:在决策层面,可以采用投票机制、贝叶斯方法或深度学习模型来综合不同模态的识别结果。在特征层面,可以设计特定的融合机制,如加权平均、特征拼接或使用注意力机制来选择性地强调某些特征。例如,结合面部表情分析和声音识别,以更准确地检测咳嗽行为。
3、然而,现有技术在室内复杂环境下对这些行为的识别面临挑战。视觉信息可能因环境遮挡和光照变化而不准确,而听觉信息可能受到背景噪声的干扰。此外,病理性行为和一些正常行为在视觉上具有高度相似性,使得仅依赖单一模态信息的识别系统难以区分。
4、尽管多模态学习在理论上可以提高识别的准确性,但实际实施中存在诸多挑战。大多数系统仅使用视频或音频中的一种数据源,无法充分利用多模态信息提高识别准确度。一些尝试融合多模态数据的系统,其特征融合策略较为简单,未能充分发挥视听信息的互补优势。现有系统对环境噪声和动态变化的适应性较差,容易受到干扰,影响识别效果。
技术实现思路
1、为了克服上述现有技术的缺点,本发明的目的在于提供一种基于视听融合的机器人室内易混淆行为类识别方法,可用于解决室内场景下的行为识别中常见的视觉易混淆类的误检问题,通过深度学习,使服务机器人更精确地理解人类行为。
2、为了实现上述目的,本发明采用的技术方案是:
3、本发明使用视频在空间分布上的信息、差分上的特征信息以及音频中的类别信息对视频中的行为类进行整体识别。在音频信息的处理上,直接使用膨胀因果卷积处理原始音频信息,从而避免音频转化为其它信息格式过程中的信息损失。考虑到行为特征在视觉、声音上是不均匀分布的,本发明在解码器中引入了类别自适应的特征融合网络。融合网络通过引入类别混淆表构建了损失函数形成了自适应的训练范式。针对现有行为识别视频数据集中声音存在大量干扰性噪音的问题,本发明使用深度网络进行杂音滤除,并通过适当的人工筛选构建了室内场景下针对视觉易混淆行为的视频数据集,该数据集中的行为具有无干扰的典型性声音,能够训练出收敛的视听融合的行为识别模型。
4、具体地,本发明一种基于视听融合的机器人室内易混淆行为类识别方法的过程可描述为:
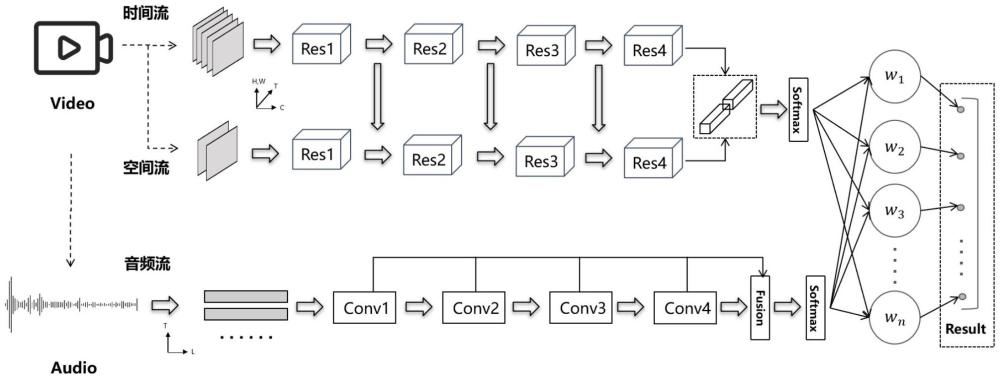
5、对于视频数据,使用两个具有不同帧采样率、不同图像分辨率的支路分别进行两种不同层级的特征提取,第一个支路为时间流支路,该支路以较高的帧采样率对视频进行帧采样,通过对所得帧图像进行连续的三维卷积得到帧图像在时间差分上的特征;第二个支路为空间流支路,该支路以较低的帧采样率对视频进行帧采样,通过对所得帧图像进行连续的三维卷积提取保留在帧图像中的空间特征,将时间流支路的帧图像进行等比例缩小,以保证效率同步,从而提升三维卷积的速度与空间流支路平齐
6、也即,对视频数据,以空间流支路的帧采样率进行图像采样得到若干图像帧组成空间信息流,其中每个采样帧具有空间流支路的图像分辨率,从所述空间信息流提取空间流支路特征;并且,对所述视频数据,以时间流支路的帧采样率进行图像采样得到若干图像帧组成时间信息流,其中每个采样帧具有时间流支路的图像分辨率,从所述时间信息流提取时间流支路特征;其中,所述时间流支路的帧采样率大于所述空间流支路的帧采样率,所述时间流支路的图像分辨率小于所述空间流支路的图像分辨率。
7、对所述视频数据,以固定采样率进行音频采样得到若干音频组成的音频信息流,从所述音频信息流提取最终声音特征;
8、融合所述空间流支路特征和时间流支路特征得到最终视觉特征;
9、融合所述最终声音特征和最终视觉特征得到最终特征,并利用所述最终特征进行行为识别。
10、在具体实施中,所述空间流支路的帧采样率为每秒2帧,时间流支路的帧采样率为每秒16帧,所述空间流支路的图像分辨率为256×256,时间流支路的图像分辨率224×224。
11、在具体实施中,所述以空间流支路的帧采样率进行图像采样得到若干图像帧组成空间信息流,从所述空间信息流提取空间流支路特征,实现方法如下:
12、对于视频数据i,以空间流支路的帧采样率采样图像帧,得到空间流输入vs:
13、
14、其中,vs,i表示空间流输入中的第i帧,表示原始视频i中的第帧,表示向下取整,c1表示空间流支路的帧采样率;利用残差3d卷积对空间流输入vs提取特征,得到空间流支路特征fvs,l,其中l为卷积操作的次数;
15、所述以时间流支路的帧采样率进行图像采样得到若干图像帧组成时间信息流,从所述时间信息提取时间流支路特征,实现方法如下:
16、对于视频数据i,以时间流支路的帧采样率采样图像帧,得到时间流输入vt:
17、
18、其中,vt,i表示时间流输入中的第i帧,表示原始视频i中的第帧,c2表示时间流支路的帧采样率;利用残差3d卷积对时间流输入vt提取特征,得到时间流支路特征fvt,l。
19、在具体实施中,将时间流输入vt中的视频帧分割成更小的切片来提高处理速度,操作前每个视频帧的维度是h×w×3,通过对一张帧图像4等分切片,并将切片后的图像块拼接到通道维度上得到新的输入格式:
20、h×w×3=h/2×w/2×12
21、其中h为切片前的单帧图像高度,w为切片前的单帧图像宽度。
22、在具体实施中,所述利用残差3d卷积对空间流输入vs提取特征,得到空间流支路特征fvs,l,实现方法如下:
23、对所述空间流输入vs进行多步连续的残差3d卷积提取其特征,对于第l层的卷积,得到视觉特征向量fvs,l:
24、fvs,l=relu(conv3d(fvs,l-1,wvs,l)+bvs,l)
25、其中,3d卷积操作表示为fconv=conv3d(i,w,p)+b,conv3d表示3d卷积,w表示卷积核或滤波器,p表示填充(padding),b为偏置项,激活函数relu表示为frelu=max(0,fconv),wvs,l为第l层的卷积核,bvs,l为第l层的偏置项;
26、层间残差特征fres提取,由如下公式表示:
27、fres=fin+frelu
28、其中fin是输入特征;
29、所述利用残差3d卷积对时间流输入vt提取特征,得到时间流支路特征fvt,l,实现方法如下:
30、fvt,l=relu(conv3d(fvt,l-1,wvt,l)+bvt,l)
31、其中,wvt,l为第l层的卷积核,bvt,l为第l层的偏置项;
32、每次卷积后将时间流支路特征作为补充信息直接相加到空间流中,空间流支路特征保持不变,表示为:
33、f′vs,l=fvs,l+fvt,l
34、经过l次的卷积操作后,得到空间流支路特征fvs,l和时间流支路特征fvt,l,融合得到最终视觉特征fv,表示为:
35、fv=fvs,l+fvt,l
36、在具体实施中,对所述视频数据,以固定采样率进行音频采样得到若干音频组成的音频信息流,实现方法如下:
37、从所述视频数据中提取出一维音频信号向量a1(t),将a1(t)输入open-unmix网络得到音频集合s,并滤除其中的背景杂音,得到音频输入ab(t);
38、将ab(t)合成到单声道中得到音频信号,并进行音频数据归一化使其范围锁定到0到1之间得到音频anorm(t),随后使用μ-law编码将anorm(t)动态压缩,得到aμ(t),最后将aμ(t)量化到l’个级别得到最终的音频向量a(t),即所述音频信息流。
39、在具体实施中,采用基于膨胀因果卷积的残差神经网络结构从所述音频信息流提取最终声音特征,实现方法如下:
40、将所述音频信息流分为t个时间步,使用基于扩张率d的因果卷积处理t时间步的一维采样数据at,得到输入序列at:t-d+1在时间步t的原始特征ft;其中at:t-d+1表示从当前时间步t回溯到t-d+1的所有样本;
41、通过k个不同扩张率的卷积层,提取不同尺度的特征,每个卷积层的输出表示为最终所有层的残差输出被合并以形成最终声音特征fa。
42、在具体实施中,制作分类混淆表tf,将表中各行按不同权重加权,最终使得融合的tf在非对角线上的元素之和最小,得到所述最终声音特征和最终视觉特征的最佳类别融合权重;
43、所述制作分类混淆表tf,过程如下:
44、预测视频的视觉预测置信度向量sv和声音预测置信度向量sa;
45、根据置信度向量,制作视觉流混淆表tv和音频流混淆表ta,tv的第i行和ta的第i行分别表示为:
46、tv,i=sci,v
47、ta,i=sci,a
48、其中sci,v为类别classi的视频ici的视觉预测置信度,sci,a为类别classi的视频ici的音频预测置信度;
49、融合tv和ta得到分类混淆表tf如下:
50、tf=tv×wv+ta×wa
51、其中wv,wa分别表示待训练的全连接层的权重;
52、利用混淆度cf量化度量预测效果,表达式如下:
53、
54、混淆度的计算为tf非对角线上的值之和,在理想情况下对角线上的元素都为1,而非对角线上的元素之和为0,即模型对数据所进行的分类没有任何混淆。
55、在具体实施中,所述使得融合的tf在非对角线上的元素之和最小,实现方法如下:
56、构建融合网络,所述融合网络在训练时输入为tv和ta,输出为一个n×n的类别混淆表tf,训练的目标是使tf非对角线上的元素之和最小,整个训练的损失函数l″如下:
57、
58、预测时取tf中各列的最大值构建一个sf向量,作为最终的融合预测得分。
59、在一个实施例中,构建室内场景视觉易混淆行为识别数据集d,以对识别模型进行训练,表示为:
60、d=clean(open-unmix(dopen)∪dcamera)
61、其中clean表示最终再对数据集进行一定的人工筛选,dopen表示使用open-unmix网络对从公开数据集中挑选出的易混淆行为类进行杂音滤除得到的行为典型性声音,dcamera表示对于某些行为类别进行人工拍摄并标注。
62、与现有技术相比,本发明的有益效果是:
63、本发明采用膨胀因果卷积的残差神经网络结构对音频特征进行提取,具体是将每个残差神经部分的残差相加作为最终的特征,从而可以尽可能多地保留音频特征。相比与将音频转换为时频谱图、波形图,能够避免某些特征在转化过程中丢失。
64、同时,由于很多类别在声音、视觉信息上的信息分布并不均匀,盲目的使用同一套权重来对声音、视觉信息进行融合是不合理的。考虑到在使用单一信息流时,不同的行为之间会产生不同的误判组合,如果按照类别顺序排列n个类别的预测结果,那么所构成的混淆表在对角线之外就具有非0值,本发明通过将混淆表的各行按不同权重加权,最终使得融合的表格tf在非对角线上的元素之和最小,从而得到最佳的类别融合权重,更好地融合视觉特征和声音特征,提高对易混淆行为的识别能力。
- 还没有人留言评论。精彩留言会获得点赞!