基于大模型知识库的集成式检索对话方法、系统及介质与流程
【】本发明涉及集成式检索对话领域,尤其涉及基于大模型知识库的集成式检索对话方法、系统及介质。
背景技术
0、
背景技术:
1、传统信息检索的方法,是通过从问题文本中提取问题实体以及属性关系,随后在知识库中进行检索。提问者通过输入具体的问题文本,对问题文本在线分析处理,随后进行检索输出最匹配的答案文本,得到对提问的回答,检索速度慢且精度差。
2、bm25为检索对话系统中比较常用的技术,是一种基于词袋模型的排名函数,用于文本相关性排序,能够有效处理不同长度的文档,有效评估文档和查询的相关性。但bm25单独处理大规模数据集并进行文本生成或回答复杂的查询时,效率和准确性仍然是主要挑战,检索效率较低,例如噪声信息多,如果知识库中包含大量不相关或错误的信息,系统可能会检索并使用这些错误的信息且容易产生误导,还有信息冗余多,检索过程会返回冗余信息,导致生成的回答缺乏新颖性或重复,无法满足用户的需求。
3、故,提出一种基于大模型知识库的集成式检索对话方法、系统及介质,采用新式dfrag技术,即dual-filter retrieval-augmented generation技术,使用密集检索器双重过滤,对检索结果进行精细调整。
技术实现思路
0、
技术实现要素:
1、本发明所要解决的技术问题在于克服现有技术的不足而提供基于大模型知识库的集成式检索对话方法、系统及介质,采用新式dfrag技术使用密集检索器双重过滤,对检索结果进行精细调整。
2、为解决上述技术问题,本发明采用如下技术方案:
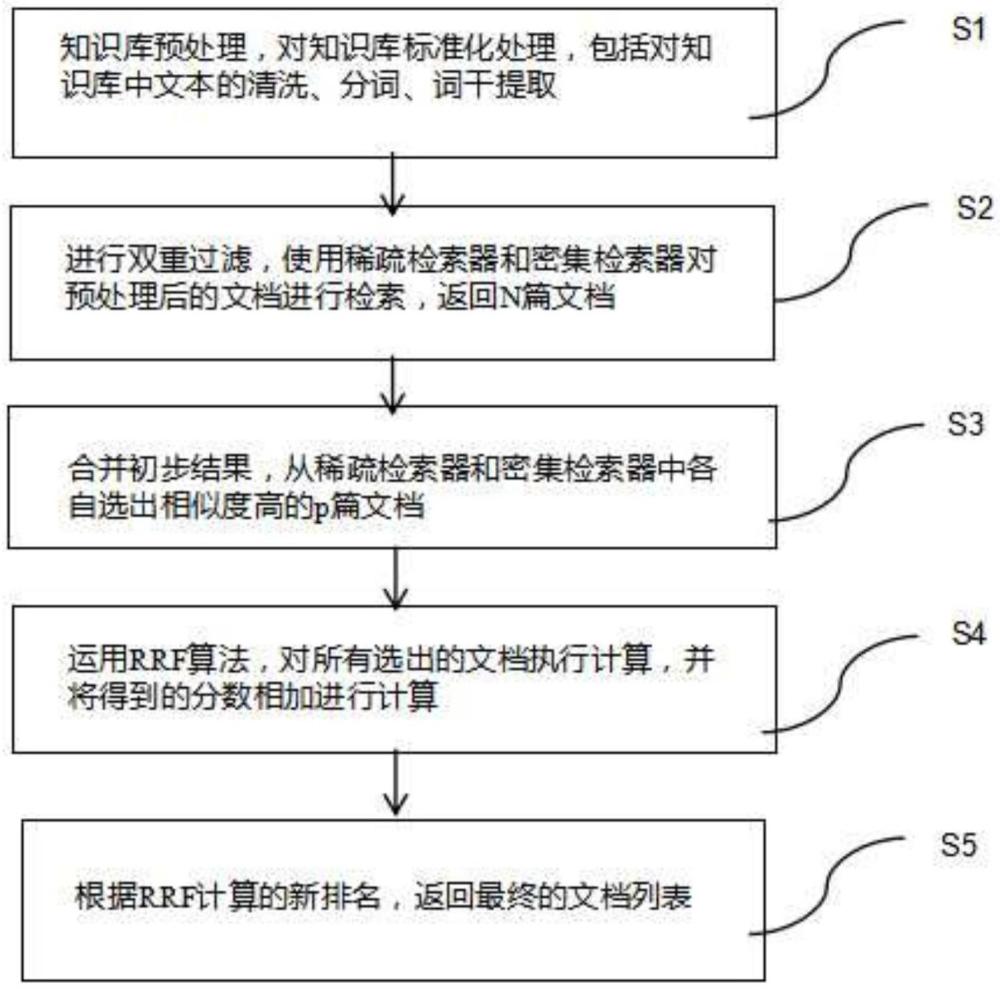
3、基于大模型知识库的集成式检索对话方法,步骤包括
4、s1:知识库预处理,对知识库标准化处理,包括对知识库中文本的清洗、分词、词干提取;
5、s2:进行双重过滤,使用稀疏检索器和密集检索器对预处理后的文档进行检索,返回n篇文档;
6、s3:合并初步结果,从稀疏检索器和密集检索器中各自选出相似度高的p篇文档;
7、s4:运用rrf算法,对所有选出的文档执行计算,并将得到的分数相加进行计算;
8、s5:根据rrf计算的新排名,返回最终的文档列表。
9、作为优选,s41:对于稀疏检索器和密集检索器返回的文档,根据其在原始排名中的位置,使用rrf计算分数,rrf公式为:
10、
11、其中,rank1是稀疏检索器检索出的文档排名,rank2是密集检索器检索出的文档排名,k是常数。
12、作为优选,还包括s6:使用评估器进行评估,根据评估的置信度进行输出,当评估器置信度高时,检索结果输出回答;当评估器置信度不高时,请求用户提供更多信息,输出最终回答。
13、作为优选,s21:先使用稀疏检索器bm25算法,对预处理后的文档进行检索,使用稀疏检索器进行检索,根据词频搜寻提到关键词的文档,返回n篇文档;
14、作为优选,s22:后使用密集检索器bert模型,对预处理后的文档进行检索,使用密集检索器生成查询和文档的嵌入向量,并通过计算向量间的相似度来检索文档。找到与整个查询的语义内容密切相关的文档,返回n篇文档。
15、作为优选,密集检索器bert模型,对获取的训练用的原始样本数据进行自适应预处理,得到训练用的输入样本;
16、通过动态学习率机制和分层自适应调节机制构建bert相似度模型;
17、通过bert相似度模型将训练用的输入样本转换为输入序列;
18、根据训练用的输入样本和输入序列生成对抗输入样本;以及
19、使用对抗输入样本和训练用的输入样本对bert相似度模型进行对抗训练,以得到训练完成的bert相似度模型。
20、作为优选,s221包括:
21、c1、构建embedding层,embedding层由三种embedding求和而成,三种embedding包括:token embeddings、segment embeddings、position embeddings;
22、c2、masked lm,用于训练深度双向的语言表示,具体的:遮盖住原始语料的一部分,之后再预测被遮盖住的部分词或字,随机mask每一个句子中30%的字,用其上下文来做预测,所有原始语料中,70%是采用[mask],20%是随机取一个词来代替mask的词,剩下的10%保持不变;
23、c3、基于自注意力机制构建双向transformer层结构。
24、基于大模型知识库的集成式检索对话系统,系统采用基于大模型知识库的集成式检索对话方法,系统包括知识库预处理模块,用于对知识库标准化处理,包括对知识库中文本的清洗、分词、词干提取;
25、双重过滤模块,用于使用稀疏检索器和密集检索器对预处理后的文档进行检索,返回n篇文档;
26、合并模块,用于在稀疏检索器和密集检索器中各自选出相似度高的p篇文档;
27、rrf算法模块,用于对所有选出的文档执行计算,并将得到的分数相加进行计算;
28、新排名模块,用于根据计算返回最终的文档列表;
29、还包括评估模块,用于根据评估置信度进行输出。
30、一种计算机可读存储介质包括存储的程序,其中,在程序运行时控制计算机可读存储介质所在设备执行如上述的基于大模型知识库的集成式检索对话方法。
31、一种处理器用于运行程序,其中,程序运行时执行如上述的基于大模型知识库的集成式检索对话方法。
32、采用本发明的有益效果:
33、1.本实施例中集成式对话的双重过滤机制,也称为dfrag技术,该机制通过结合bm25稀疏检索器和bert密集检索器的优势,实现了对查询文档领域或者招投标领域相关文档的高效检索和精确筛选。首先,bm25检索器利用其强大的关键词匹配能力,从海量文档中快速检索出与招投标相关的初步候选文档。随后,bert检索器进一步对这些候选文档进行语义层面的评估,确保检索结果不仅在字面上匹配,而且在语义上与查询文档领域或者招投标领域的专业知识相契合。
34、在双重过滤的过程中,dfrag技术特别强调了对检索结果的精细调整。通过选取两种检索器排名靠前的文档的前20%,dfrag确保了最终输入到大型语言模型的信息是经过严格筛选的,从而减少了误导性幻觉的产生,并提高了信息的时效性和准确性。
35、此外,dfrag技术还引入了一个轻量级的评估器,如t5模型,它在将检索到的文档输入到大型语言模型之前,对文档进行预处理和评估。这一步骤不仅提高了处理效率,还确保了输入信息的适宜性和相关性,进一步增强了模型在查询文档领域或者招投标领域的专业洞察力。
36、总的来说,dfrag技术通过结合稀疏检索和密集检索的方法,以及使用轻量级评估器来预处理数据,旨在提高生成模型的性能和效率。这种方法能够更有效地利用相关信息,同时减少不相关或低质量数据对模型性能的影响。
37、2.减少误导:通过双重过滤机制确保输入的信息经过严格筛选,从而降低误导性输出的风险。
38、3.提高信息时效性:通过实时检索最新文档,确保模型能够访问和利用最新的查询文档领域或者招投标领域信息。
39、4.提升处理特定知识效率:在处理特定领域,如招投标系统的知识时,大型语言模型可能效率不高,通过专门设计的检索和过滤机制,提高了模型处理特定领域知识的效率。
40、5.增强专业领域的深度洞察:通过结合领域特定的检索和评估器,增强了模型对招投标系统等专业领域的深度洞察。
41、6.优化信息输入质量:为了提高生成内容的准确性和相关性,通过轻量级评估器对检索到的文档进行预处理和评估,确保输入到大型语言模型的信息质量。
42、本发明的这些特点和优点将会在下面的具体实施方式、附图中详细的揭露。
- 还没有人留言评论。精彩留言会获得点赞!