一种多模态智能知识检索及对话系统及方法与流程
本发明涉及智能交互,具体涉及一种多模态智能知识检索及对话系统及方法。
背景技术:
1、在多个行业和应用领域中,随着客户群体的不断扩大和知识需求的日益多样化,提供准确、高效的知识检索及对话服务对于提升用户体验和提高业务效率非常重要。现有的知识检索及对话系统主要分为基于传统深度学习和基于大语言模型两大类,其中传统深度学习系统以其高准确率和强可解释性著称,但在处理多样化语言和复杂场景时显得力不从心,功能扩展受限。相比之下,大语言模型在语义理解上展现出了巨大潜力,但在特定场景和领域知识的适应性、准确性及可解释性方面仍存在不足,这主要是由于模型在训练过程中缺乏足够的场景化数据造成的。
2、为了弥补现有技术所存在的不足,提升对话系统在通用场景下的表现,需要引入更加灵活和智能的对话生成策略,这些策略应能够基于用户意图的精准识别,动态调整对话流程和内容。同时,考虑到单一模态(如仅文本数据)的交互方式可能无法全面捕捉用户的真实需求和上下文信息,多模态技术的引入成为了必然。
3、多模态技术通过整合来自不同源的信息(如文本、语音、图像、视频等),能够提供更丰富、更立体的用户画像和交互体验。在知识检索及对话系统中,多模态技术可以帮助系统更好地理解用户的复杂需求,如通过语音识别技术捕捉用户的语音指令,同时通过图像识别技术理解用户上传的图像内容。此外,系统还可以利用多模态输出方式(如文本+图表、视频演示等)向用户展示更直观、易懂的信息,提升用户的交互体验和满意度。
技术实现思路
1、(一)解决的技术问题
2、针对现有技术所存在的上述缺点,本发明提供了一种多模态智能知识检索及对话系统及方法,能够有效克服现有技术所存在的无法准确识别用户意图,以及不能向用户更直观地展示对话信息的缺陷。
3、(二)技术方案
4、为实现以上目的,本发明通过以下技术方案予以实现:
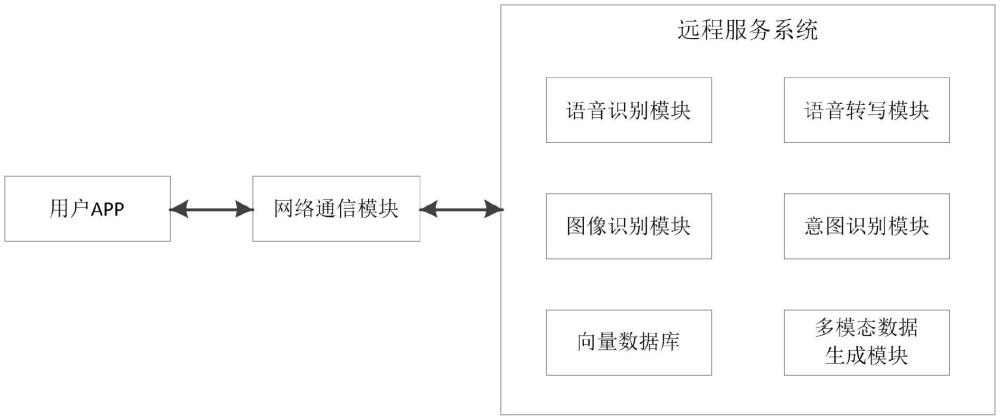
5、一种多模态智能知识检索及对话系统,包括用户app、网络通信模块和远程服务系统,所述远程服务系统通过网络通信模块接收用户app发送的多模态请求,对多模态请求进行意图识别得到多模态意图,根据多模态意图进行多模态知识检索,以生成相应的多模态数据,并通过网络通信模块发送给用户app。
6、优选地,所述远程服务系统包括语音识别模块、语音转写模块、图像识别模块、意图识别模块、向量数据库和多模态数据生成模块;
7、语音识别模块,用于对多模态请求中的语音请求信息进行语音识别;
8、语音转写模块,根据语音识别结果将语音请求信息转写为文本请求信息;
9、图像识别模块,用于对多模态请求中的图像请求信息进行图像识别;
10、意图识别模块,根据文本请求信息和图像识别结果对用户意图信息进行意图识别,得到多模态意图;
11、向量数据库,用于存储向量化后的文本数据和图像数据;
12、多模态数据生成模块,根据多模态意图选择不同的对话生成策略,并在向量数据库中进行多模态知识检索,以生成相应的多模态数据;
13、其中,多模态请求包括文本请求信息、语音请求信息和图像请求信息,多模态数据包括目标文本数据、目标语音数据和目标图像数据。
14、优选地,所述意图识别模块根据文本请求信息和图像识别结果对用户意图信息进行意图识别,得到多模态意图,包括:
15、基于文本请求信息和图像识别结果,利用训练好的意图识别模型对用户意图信息进行意图识别,得到多模态意图;
16、其中,多模态意图包括用户期望对话生成形式,用户期望对话生成形式包括纯文本、语音+文本、图像+文本和语音+图像+文本。
17、优选地,所述意图识别模型的模型训练过程,包括:
18、收集大量行业图像,获取相关领域知识,并进行数据预处理;
19、对行业图像和领域知识进行汇总标注,并按照预设比例划分为训练集、验证集和测试集;
20、利用训练集、验证集和测试集对意图识别模型进行模型训练,得到训练好的意图识别模型。
21、优选地,所述收集大量行业图像,获取相关领域知识,并进行数据预处理,包括:
22、对行业图像和领域知识进行数据清洗,确保数据中没有缺失值、重复值和异常值;
23、对于文本数据,进行分词、去停用词和词干提取处理,并将文本数据转换为向量形式;
24、对于图像数据,进行标准化、归一化处理,并将图像数据转换为向量形式;
25、其中,将文本数据、图像数据转换为向量形式后存储至向量数据库中,采用tf-idf、word2vec、bert中的一种方法将文本数据转换为向量形式。
26、优选地,所述向量数据库存储向量化后的文本数据和图像数据,包括:
27、将向量化后的文本数据、图像数据分别输入训练好的意图识别模型,得到对应的输出向量结果;
28、采用faiss算法对输出向量结果创建向量索引,并根据数据规模、数据分布和查询需求调整索引参数,提升索引性能;
29、其中,faiss算法中的索引参数包括索引的簇数量和训练样本比例。
30、优选地,所述多模态数据生成模块根据多模态意图选择不同的对话生成策略,并在向量数据库中进行多模态知识检索,以生成相应的多模态数据,包括:
31、若用户期望对话生成形式中包括文本数据,则根据多模态意图利用向量索引在向量数据库中对文本知识库进行知识检索,以获取目标文本数据;
32、若用户期望对话生成形式中包括语音数据,则根据多模态意图利用向量索引在向量数据库中对文本知识库进行知识检索,以获取目标文本数据,并将目标文本数据转换为目标语音数据;
33、若用户期望对话生成形式中包括图像数据,则根据多模态意图利用向量索引在向量数据库中对图像向量库进行知识检索,以获取目标图像数据。
34、优选地,根据多模态意图利用向量索引在向量数据库中进行知识检索,包括:
35、根据多模态意图确定查询向量,对查询向量进行预处理,使得查询向量与索引中的向量保持格式一致;
36、利用向量索引在向量数据库中进行近邻搜索,返回搜索结果;
37、根据相似度对搜索结果进行排序,并根据业务需求进行过滤,以获取目标数据;
38、其中,对于大规模知识检索,使用多线程或分布式计算进行并行化批量知识检索,将多个知识检索合并为一个批次进行处理,以减少向量索引搜索次数,提高知识检索效率;
39、对于常用搜索结果进行缓存,减少重复搜索时间,同时定期根据新增向量和搜索情况更新或重新构建向量索引,以提高知识检索效率。
40、优选地,该系统还包括一个包含多模态信息的状态机,系统通过状态机跟踪实时对话的上下文和历史交互记录,通过智能引导与反馈机制,主动引导用户提供必要的信息,或根据用户的反馈及时调整对话生成策略,保证对话顺利进行。
41、一种多模态智能知识检索及对话方法,包括以下步骤:
42、s1、用户app通过网络通信模块向远程服务系统发送多模态请求;
43、s2、远程服务系统对多模态请求中的语音请求信息进行语音识别,并根据语音识别结果将语音请求信息转写为文本请求信息;
44、s3、远程服务系统对多模态请求中的图像请求信息进行图像识别;
45、s4、远程服务系统根据文本请求信息和图像识别结果对用户意图信息进行意图识别,得到多模态意图;
46、s5、远程服务系统根据多模态意图选择不同的对话生成策略,并在向量数据库中进行多模态知识检索,以生成相应的多模态数据;
47、s6、远程服务系统通过网络通信模块将多模态数据发送给用户app;
48、s7、用户app接收多模态数据,并对多模态数据进行多模态结果显示;
49、其中,多模态请求包括文本请求信息、语音请求信息和图像请求信息,多模态数据包括目标文本数据、目标语音数据和目标图像数据。
50、(三)有益效果
51、与现有技术相比,本发明所提供的一种多模态智能知识检索及对话系统及方法,具有以下有益效果:
52、1)语音识别模块对多模态请求中的语音请求信息进行语音识别,语音转写模块根据语音识别结果将语音请求信息转写为文本请求信息,图像识别模块对多模态请求中的图像请求信息进行图像识别,意图识别模块根据文本请求信息和图像识别结果对用户意图信息进行意图识别,得到多模态意图,支持用户进行多模态输入,帮助系统建立更丰富、更立体的用户画像,使得系统能够准确识别用户意图,更好地理解用户的复杂需求;
53、2)多模态数据生成模块根据多模态意图选择不同的对话生成策略,并在向量数据库中进行多模态知识检索,以生成相应的多模态数据,丰富了对话信息的展示形式,能够根据用户意图采用相应的对话生成形式,有效提升用户的交互体验和满意度。
- 还没有人留言评论。精彩留言会获得点赞!