一种自然语言威胁情报抽取分析方法及系统与流程
本发明涉及自然语言,具体为一种自然语言威胁情报抽取分析方法及系统。
背景技术:
1、自然语言是指人类日常使用的语言,比如英语、汉语、法语等;与计算机语言不同;利用自然语言进行威胁情报分析;威胁情报分析通常涉及处理大量的文本数据,例如:网络安全事件报告安全博客和论坛文章社交媒体帖子恶意软件代码黑客论坛对话这些数据通常以自然语言形式存在,因此需要借助自然语言处理技术进行分析;自然语言处理(nlp)技术可以帮助我们:提取关键信息:从文本中提取关键信息,例如攻击者的名称、攻击目标、攻击方法、攻击时间等。
2、现有在应对网络安全方面,利用自然语言处理技术完成对网络各个事件或数据进行分析,并抽取出威胁或工具的情报,例如关于黑客攻击事件、关于新闻媒体报道的系统漏洞入侵事件等,针对大量的此类事件通常需要进行快速的文本处理,但在处理时会发生疏漏的情况,考虑到效率问题,一些威胁程度高的部分事件可能被疏漏或忽略,而一些威胁程度低的部分事件反而得到优先处理,这就会导致无法满足对不同威胁程度事件的快速响应式处理,同时系统分析处理时运用到的计算资源也得不到合理分配,从而可能会进一步影响到网络安全防护的效率和准确性。
技术实现思路
1、(一)解决的技术问题
2、针对现有技术的不足,本发明提供了一种自然语言威胁情报抽取分析方法及系统,对高优先级的威胁事件进行深度分析,综合各类参数以计算出威胁程度预估值,不仅能够快速反映出当前高优先级威胁事件的严重程度,还能够为后续预测下一时间周期内存在高密度威胁对应时间段提供优先的关注点,结合预警信号和关注机制,提高了安全团队对威胁事件的响应速度和能力,解决了背景技术中提出的问题。
3、(二)技术方案
4、为实现以上目的,本发明通过以下技术方案予以实现:
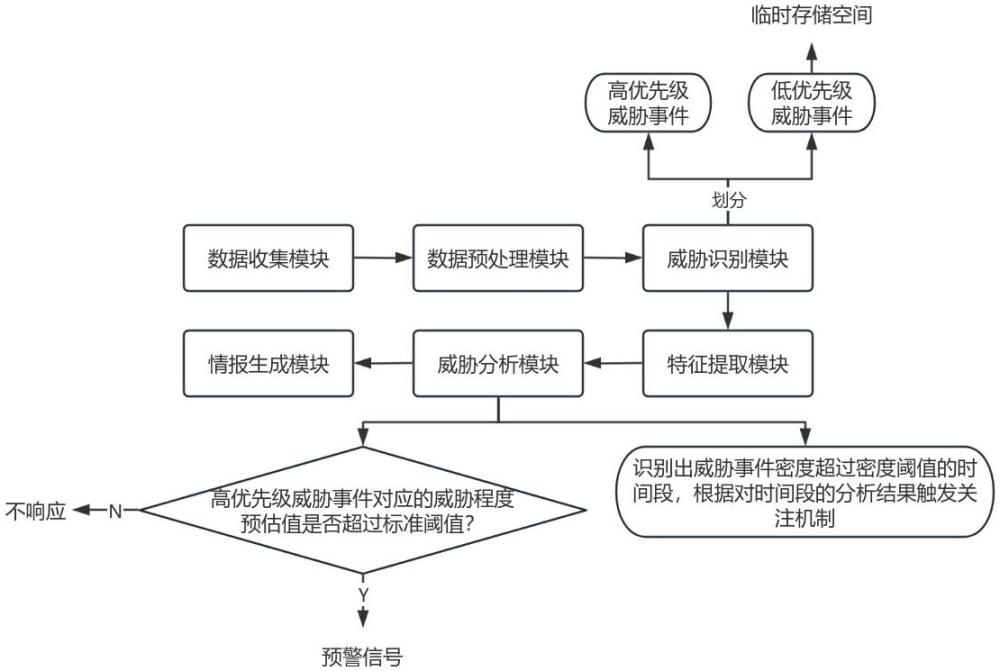
5、一种自然语言威胁情报抽取分析系统,该系统包括:
6、数据收集模块,采用数据采集技术,获取网络安全数据;
7、数据预处理模块,对网络安全数据进行预处理;
8、威胁识别模块,对经过预处理的网络安全数据进行初步威胁识别,利用轻量级nlp模型识别威胁信号,并搭建规则引擎,对威胁信号划分,生成高、低两类优先级对应的威胁事件;
9、特征提取模块,结合nlp技术和命名实体识别技术,从威胁事件中提取特征信息;
10、威胁分析模块,利用机器学习模型,根据若干已知威胁事件的数据进行训练,机器学习模型根据提取的特征,预测威胁类别;对高优先级的威胁事件进行深度分析,依据深度分析结果执行对应策略;对低优先级的威胁事件进行临时存储;
11、情报生成模块,生成可读的威胁情报报告。
12、进一步的,数据采集技术包括爬虫技术、api技术、订阅以及平台共享,网络安全数据的来源包括:安全博客和论坛、黑客论坛、新闻媒体、社交媒体以及漏洞数据库。
13、进一步的,对网络安全数据进行预处理的过程包括:清洗、分词、词性标注、命名实体识别以及语义分析。
14、进一步的,轻量级nlp模型采用关键词匹配技术,使用预先定义的关键词库进行匹配;
15、关键词库:预先定义包含攻击相关关键词和短语的库;关键攻击关键词:标识强烈的攻击意图,包括但不限于:"exploit","malware","ransomware"以及"botnet";非关键攻击关键词:标识潜在的攻击意图,包括但不限于: "scan","probe","injection"以及"bypass";
16、搭建的规则引擎中,匹配定义如下:
17、高优先级:数据中包含至少2个关键攻击关键词,或者包含1个关键攻击关键词且至少1个非关键攻击关键词;低优先级:数据中包含1个关键攻击关键词且没有非关键攻击关键词,或者仅包含非关键攻击关键词。
18、进一步的,从威胁事件中提取的特征信息包括:时间、地点、攻击者、目标、攻击方法、漏洞以及工具。
19、进一步的,使用机器学习模型进行威胁类型预测的过程如下:
20、数据准备:收集已知威胁事件的数据;将数据进行处理,对文本数据进行分词、词干提取,转化成数字特征;对特征向量进行标准化处理,将数值特征归一化到0到1之间;
21、特征工程:选择特征信息进行特征组合,构建新的特征;
22、通过特征选择方法筛选出所需特征;
23、模型选择:选择支持向量机作为机器学习模型;
24、模型训练:将准备好的数据分成训练集和测试集;使用训练集对所选模型进行训练;
25、模型评估:使用测试集对训练好的模型进行评估,根据评估结果,选择最佳的模型;
26、预测:使用训练好的模型,对新的威胁事件描述进行预测,得到威胁类型。
27、进一步的,对高优先级的威胁事件进行深度分析的过程如下:
28、对每个高优先级的威胁事件进行威胁严重程度评估,获取每个高优先级威胁事件的评估参数数据集,并对评估参数数据进行无量纲化处理,生成每个高优先级威胁事件所对应的威胁程度预估值,对威胁程度预估值超过预设标准阈值的高优先级威胁事件发出预警信号;并按照时间顺序,于预定时间周期t内,在时间线上标记高优先级威胁事件所对应的时间点,而后采用滑动窗口算法结合预设的密度阈值,以识别出威胁事件密度超过密度阈值的时间段,根据对时间段的分析结果触发关注机制。
29、进一步的,评估参数数据集包括关键词数量、威胁复杂度以及威胁事件发生时间与当前时间的差值;威胁复杂度的获取过程为:
30、二次搭建规则引擎,从提取的特征信息中抽取目标、攻击方法以及攻击者,并定义为关键因素,并赋予每个关键因素对应的权重和分值,且权重和分值保持同步;
31、目标:核心系统,赋予权重3>普通系统,赋予权重2>网络,赋予权重1;
32、攻击方法:零日漏洞,赋予权重3>已知漏洞,赋予权重2>端口扫描,赋予权重1;
33、攻击者:已知黑客组织,赋予权重3>未知组织,赋予权重2>个人攻击,赋予权重1;
34、将每个因素的分值乘以其权重,再将所有结果相加,即可得到威胁复杂度;
35、生成每个高优先级威胁事件所对应威胁程度预估值,所依据的公式如下:
36、
37、式中,gw表示威胁程度预估值,s表示关键词数量,tc表示威胁复杂度,表示时间衰减因子,ch表示威胁事件发生时间与当前时间的差值,g表示时间常数。
38、进一步的,识别出威胁事件密度超过密度阈值的时间段的过程如下:
39、时间线标记:将高优先级威胁事件按照时间顺序标记在时间线上;
40、滑动窗口算法:采用滑动窗口算法来计算每个时间段内的高优先级威胁事件密度;
41、密度阈值:设定高优先级威胁事件密度的密度阈值,即每小时三个事件;
42、识别高密度时间段:滑动窗口在时间线上移动,计算每个窗口内的高优先级威胁事件数量,并与密度阈值比较,识别出高优先级威胁事件密度超过密度阈值的时间段;
43、若干高密度时间段的处理:当识别出m个高密度时间段时,则对每个时间段内的高优先级威胁事件进行危险程度评估值求平均,得到平均值;
44、根据对时间段的分析结果触发关注机制,当m的取值为1时,则在下一时间周期t内,对该高密度时间段进行关注;当m的取值超过1时,则对比每个高密度时间段对应的平均值,在下一时间周期t内,不同高密度时间段的关注优先级与对应平均值的大小成正相关,对某一平均值最大的对应高密度时间段进行最先关注;
45、依据深度分析结果执行对应策略的过程如下:
46、对威胁程度预估值超过预设标准阈值的高优先级威胁事件发出预警信号时,提醒网络安全工作人员进行应对;在关注的过程中若发现问题或威胁,也立即提醒安全工作人员进行应对。
47、一种自然语言威胁情报抽取分析方法,包括如下步骤:
48、s1、采用数据采集技术,获取网络安全数据;
49、s2、对网络安全数据进行预处理;
50、s3、对经过预处理的网络安全数据进行初步威胁识别,利用轻量级nlp模型识别威胁信号,并搭建规则引擎,对威胁信号划分,生成高、低两类优先级对应的威胁事件;
51、s4、结合nlp技术和命名实体识别技术,从威胁事件中提取特征信息;
52、s5、利用机器学习模型,根据若干已知威胁事件的数据进行训练,机器学习模型根据提取的特征,预测威胁类别;对高优先级的威胁事件进行深度分析,依据深度分析结果执行对应策略;对低优先级的威胁事件进行临时存储;
53、s6、生成可读的威胁情报报告。
54、(三)有益效果
55、本发明提供了一种自然语言威胁情报抽取分析方法及系统,具备以下有益效果:
56、(1)多源数据收集策略确保了网络安全数据的全面性和实时性,为后续的威胁识别和防护提供了丰富的数据支持,轻量级nlp模型和规则引擎的结合,实现了对网络安全数据的快速、准确威胁识别,并能够对威胁信号进行优先级划分,有助于安全团队优先处理高优先级威胁,在一定程度上提高了网络安全防护的效率和准确性;
57、(2)通过机器学习模型的应用,实现了对网络安全数据的自动化、智能化分析,提高了威胁识别的效率和准确性,这有助于安全团队在海量数据中快速筛选出潜在的威胁事件,并进行优先处理;
58、(3)对高优先级的威胁事件进行深度分析,综合各类参数以计算出威胁程度预估值,不仅能够快速反映出当前高优先级威胁事件的严重程度,还能够为后续预测下一时间周期内存在高密度威胁对应时间段提供优先的关注点,结合预警信号和关注机制,提高了安全团队对威胁事件的响应速度和能力,当发现潜在威胁时,安全团队能够迅速采取行动,并有效应对,从而降低了网络安全威胁事件所带来的影响和损失。
- 还没有人留言评论。精彩留言会获得点赞!