基于碳智能管理平台异构数据融合接入方法及系统与流程
本发明碳智能管理,具体涉及基于碳智能管理平台异构数据融合接入方法及系统。
背景技术:
1、实现碳中和目标的关键在于建立一套高效、精准的碳排放管理机制,这要求对碳排放数据进行实时监测、精确核算以及科学预测。然而,当前的碳排放管理面临诸多挑战,包括数据来源多样、格式不一,以及数据采集、处理和分析的复杂性。此外,如何确保数据的透明度、可信度以及在多主体间公平交易的实现,也是亟待解决的问题。
2、在此基础上,区块链技术以其独特的去中心化、数据不可篡改、透明度高等特点,为碳排放管理提供了新的解决方案。区块链技术可以构建一个可靠的碳排放数据记录和交易平台,实现碳足迹的准确追踪、碳排放权的公正交易以及碳减排成效的透明认证。通过智能合约,可以自动化执行碳排放交易规则,减少人为干预,提高效率和公信力。
3、然而,当前碳排放数据来源于电源侧、负荷侧、储能侧等多个不同源头,数据类型多样,结构各异,传统集中式处理方式难以满足实时性、隐私保护及数据融合的需求。
技术实现思路
1、为了解决上述技术问题,本发明提供了基于碳智能管理平台异构数据融合接入方法及系统,具体技术方案如下:
2、一种基于碳智能管理平台异构数据融合接入方法,包括以下步骤:
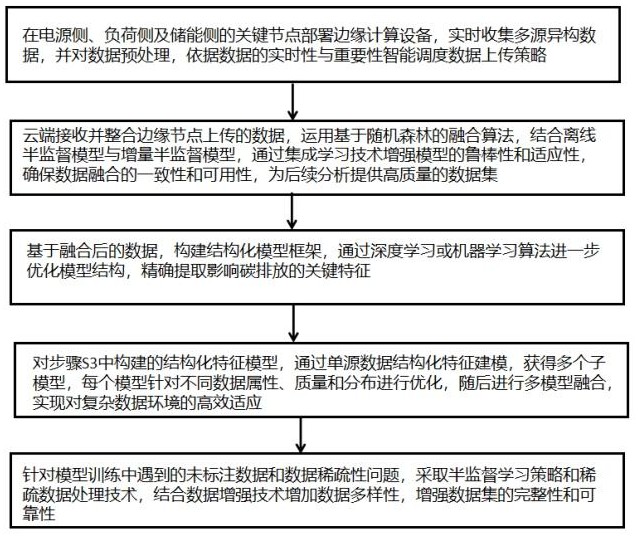
3、s1、在电源侧、负荷侧及储能侧的关键节点部署边缘计算设备,实时收集多源异构数据,并对数据预处理,依据数据的实时性与重要性智能调度数据上传策略;
4、s2、云端接收并整合边缘节点上传的数据,运用基于随机森林的融合算法,结合离线半监督模型与增量半监督模型,通过集成学习技术增强模型的鲁棒性和适应性,确保数据融合的一致性和可用性,为后续分析提供高质量的数据集;
5、s3、基于步骤s2中融合后的数据,构建结构化模型框架,通过深度学习或机器学习算法进一步优化模型结构,精确提取影响碳排放的关键特征;
6、s4、对步骤s3中构建的结构化特征模型,通过单源数据结构化特征建模,获得多个子模型,每个模型针对不同数据属性、质量和分布进行优化,随后进行多模型融合,实现对复杂数据环境的高效适应;
7、s5、针对模型训练中遇到的未标注数据和数据稀疏性问题,采取半监督学习策略和稀疏数据处理技术,结合数据增强技术增加数据多样性,增强数据集的完整性和可靠性。
8、进一步地,所述步骤s1的具体方法为:
9、s11、在电源侧、负荷侧、储能侧的关键位置部署边缘计算节点,这些节点配备必要的硬件模块,如数据采集模块、处理单元和存储设备,能够直接与现场传感器、控制器等设备连接,实现数据的本地接入;
10、s12、边缘节点实时接收来自不同源头的原始数据,通过预设的数据处理算法或脚本,边缘计算设备立即对数据进行初步清洗,去除无效或错误数据,进行必要的数据平滑处理,减少噪声干扰;
11、s13、对不同格式的原始数据进行转换,确保数据格式的一致性;
12、s14、在边缘节点部署轻量级的分析算法或模型,对数据进行即时分析,快速识别数据中的模式和异常;
13、s15、对于需要频繁访问或实时监控的数据,边缘计算节点实施数据缓存策略,存储最近或最重要的数据,同时,基于边缘分析的结果,节点实施本地决策,自动调节设备运行参数,响应异常情况;
14、s16、根据数据处理和分析结果的重要性与紧急程度,边缘计算节点智能决定哪些数据需要实时上传至云端,哪些数据按需或定期上传,哪些数据存储在本地。
15、进一步地,所述步骤s2的具体方法为:
16、 s21、基于采集的数据,对电源侧、负荷侧、储能侧的数据进行分类,针对不同格式的数据,将其统一转化为标准化的数据格式;
17、s22、数据质量检查与清洗:对收集到的数据进行完整性校验,剔除缺失或错误的数据记录,识别数据中的异常值,并根据具体情况选择剔除、修正或保留;
18、s23、从原始数据中提取对碳排放预测有意义的特征,并将非结构化或半结构化数据转换为结构化数据;
19、s24、利用随机森林算法处理异构数据的多样性,构建离线和增量学习模型,针对数据异构性,调整随机森林参数,提高融合效果,采用数据插补技术填补稀疏数据,利用半监督学习算法处理未标注数据,增强模型的泛化能力;
20、s25、数据融合验证与评估:评估融合后数据的质量和模型的预测能力,分析融合数据与单一数据源相比的改善程度,根据评估结果,对融合算法进行调优。
21、进一步地,所述步骤s3的具体方法为:
22、s31、识别与碳排放量关联度高的特征,根据碳排放的特性和数据特点,创建新的衍生特征;
23、s32、对连续数值特征进行归一化或标准化处理,对分类数据采用独热编码、标签编码或序数编码,使模型能够理解并处理此类特征;
24、s33、评估各个特征对模型预测结果的贡献度,剔除无关或冗余特征,定量分析特征与目标变量之间的关系强度;
25、s34、将整合好的特征数据集按比例分为训练集、验证集和测试集,根据碳排放预测的特点,选择合适的机器学习模型进行模型训练,通过调整模型超参数优化模型性能,提高模型预测精度;
26、s35、评估模型在测试集上的表现,对模型输出的特征重要性进行解析,识别对碳排放预测的关键参数。
27、进一步地,所述碳排放量关联度高的特征,包括如时间序列、能源类型、设备类型、环境参数。
28、进一步地,所述步骤s4的具体方法为:
29、s41、子模型构建与验证:针对碳排放的不同维度和影响因素,选择或定制多种模型,每种模型负责特定的预测或分析任务,将整合清洗后的数据按照模型需求划分为训练集、验证集和测试集,独立训练每个子模型,对子模型进行性能验证,根据验证结果调整模型参数,确保每个子模型达到最优状态;
30、s42、采用集成学习方法将多个子模型的预测结果进行综合;
31、s43、根据实时数据量和计算需求,调度模型在边缘端或云端运行,优化资源分配,根据新收集的数据实时调整模型参数,保持模型预测的时效性,并通过反馈机制不断优化模型性能;
32、s43、通过历史数据回测和实时数据跟踪,评估多结构模型协同工作的整体性能,在不同环境和数据条件下测试模型协同工作的稳定性。
33、进一步地,所述步骤s5的具体方法为:
34、s51、在处理未标注数据前,先通过统计方法或机器学习算法识别潜在的异常值,进行过滤或修正;
35、s52、利用特征选择算法去除对模型贡献较小的特征,或采用降维技术减少数据的维度,减少稀疏性。将稀疏数据转换为一组稀疏编码,每个编码对应一个原子,从而揭示数据的潜在结构,增强模型对稀疏数据的表达能力;
36、s53、定期进行数据清洗,移除重复项、纠正错误值,同时对数据进行完整性校验,确保数据的准确性和完整性;
37、s54、效果评估与迭代优化:评估处理后数据集在模型训练中的表现,包括预测精度、模型稳定性和训练效率,根据评估结果对数据处理策略进行调整。
38、进一步地,所述步骤s53还包括对于特定类型的未标注数据,采用数据合成技术增加数据多样性,所述数据合成技术包括噪声注入、旋转、平移中的一种或多种结合。
39、本发明还公开了基于碳智能管理平台异构数据融合接入系统,包括:边缘集中式数据采集模块、多源异构数据融合模块、结构化特征建模模块、多结构模型协同模块、未标注数据与稀疏数据处理模块;
40、所述边缘集中式数据采集模块用于在电源侧、负荷侧及储能侧的关键节点部署边缘计算设备,实时收集多源异构数据,并对数据预处理,依据数据的实时性与重要性智能调度数据上传策略;
41、所述多源异构数据融合模块用于云端接收并整合边缘节点上传的数据,运用基于随机森林的融合算法,结合离线半监督模型与增量半监督模型,通过集成学习技术增强模型的鲁棒性和适应性,确保数据融合的一致性和可用性,为后续分析提供高质量的数据集;
42、所述结构化特征建模模块用于基于融合后的数据,构建结构化模型框架,通过深度学习或机器学习算法进一步优化模型结构,精确提取影响碳排放的关键特征;
43、所述多结构模型协同模块用于构建的结构化特征模型,通过单源数据结构化特征建模,获得多个子模型,每个模型针对不同数据属性、质量和分布进行优化,随后进行多模型融合,实现对复杂数据环境的高效适应;
44、所述未标注数据与稀疏数据处理模块用于针对模型训练中遇到的未标注数据和数据稀疏性问题,采取半监督学习策略和稀疏数据处理技术,结合数据增强技术增加数据多样性,增强数据集的完整性和可靠性。
45、与现有技术相比,本发明的有益效果为:1、本发明通过在边缘节点部署数据处理能力,实现了数据的即时收集与初步分析,显著缩短了数据处理周期,降低了传统云端处理的延时。这种近端处理模式使得碳排放的监测与响应速度大幅提升,对于实时调控能源消耗、及时发现并应对异常排放情况至关重要,极大增强了碳管理的实时性和效率。
46、2、通过边缘计算的运用有效减轻了云端服务器的负担,避免了海量数据的集中传输,减少了网络拥堵和数据传输成本。通过在边缘进行数据预处理和筛选,仅将关键数据传输至云端,显著节约了网络资源和云端计算资源,实现了数据处理的分布式优化,提升了整体系统的能效比。
47、采用基于随机森林的多源异构数据融合方法,有效地解决了数据格式多样、质量参差不齐的挑战,通过融合离线与增量学习模型,不仅提高了数据的一致性和可用性,还通过集成学习提升了模型的预测精度和稳定性。这种融合技术能够从多维度、多层次深入分析碳排放数据,为碳排放的精确预测和管理提供了强有力的技术支持。
48、3、通过边缘计算的本地化数据处理,减少了数据在网络中的传输距离和次数,降低了数据泄露的风险。结合区块链等技术,可以进一步提升数据的透明度和不可篡改性,确保碳排放数据的完整性和真实性,为碳交易、碳足迹追溯等提供了可靠的数据基础,增强了参与方的信任度。
- 还没有人留言评论。精彩留言会获得点赞!