一种基于人机交互的半自动目标检测预标注方法与流程
本发明涉及人机交互,具体为一种基于人机交互的半自动目标检测预标注方法。
背景技术:
1、人机交互(human-computer interaction,简称hci)是研究人与计算机之间进行信息交换的技术领域,是指人与计算机之间使用某种对话语言,以一定的交互方式,为完成确定任务的人与计算机之间的信息交换过程。这个领域的研究旨在提升用户与系统之间的交互体验,使用户能够更加便捷、直观地与机器进行沟通。在人机交互领域,目标检测是一项重要任务,用于识别图像或视频中的特定目标或对象。然而,手动标注大量图像数据对于人工来说既耗时又耗力。因此,半自动目标检测预标注被引入以减轻人工负担,这种方法利用自动标注算法初步标注数据,再由人工进行检查和修正,实现了标注效率和准确性的平衡。
2、就比如申请号为202110328124.2的专利文件公开了一种基于人机交互的半自动标注方法及系统,该发明的方法首先将额外点击作为先验信息来对目标进行检测,进而达到半自动标注的预期效果,然后通过对错检目标的惩罚降低误检率,进一步提升检测效果;且该发明的半自动标注模型不仅大幅度提升了原有模型的精度,并对不同的数据集也有很好的迁移效果,可以摆脱人工标注费时费力的弊端,只需要人为提供一个目标所在位置的先验信息,模型就可以主动加强对当前位置附近的检测;此外,加了一个修正部分,对预测结果不理想的目标进行修正使其预测正确;同时对原有结构进行改进,在交互式检测的基础上又加了一个修正操作,使其达到修正目的。
3、但类似于上述申请的现有半自动标注技术依然存在以下不足:
4、当前,尽管引入了半自动目标检测预标注技术,但由于自动标注算法的局限性,其标注结果不可避免的存在误差,因此大部分自动标注的结果都需要人工进行检查和修正,尤其在复杂场景下,自动标注算法更是难以准确识别目标,其标注结果的误差也就越大,这导致现有技术中,人工标注的工作量仍然较大,且影响了标注效率。
5、因此,急需对此缺点进行改进,本发明则是针对现有的技术及不足予以研究改良,提供有一种基于人机交互的半自动目标检测预标注方法。
技术实现思路
1、本发明的目的在于提供一种基于人机交互的半自动目标检测预标注方法,以解决上述背景技术中提出的问题。
2、为实现上述目的,本发明提供如下技术方案:一种基于人机交互的半自动目标检测预标注方法,包括以下步骤:
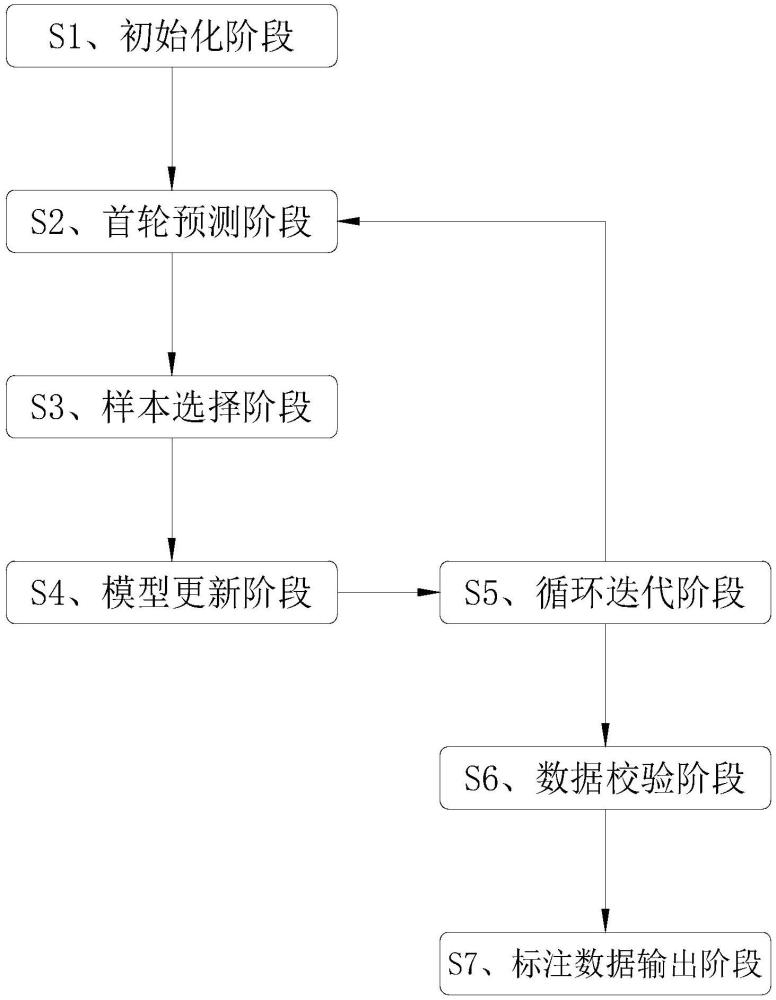
3、s1、初始化阶段:准备未标注的图像数据组成训练数据集,并进行初步的数据清洗和预处理,再基于训练数据集,选择或训练一个初始的目标检测模型;
4、s2、首轮预测阶段:将未标注的数据集输入到初始模型中,进行目标检测的预测,模型会输出每个图像的预测结果,包括预测框的位置、大小和类别等信息;
5、s3、样本选择阶段:利用主动学习技术,根据模型对样本的预测结果和不确定性,选择最有价值的样本进行人工标注,且人工标注的标注内容包括但不限于目标的位置(标注框)、大小(边界框尺寸)和类别(分类标签);
6、s4、模型更新阶段:将人工标注的样本加入训练集,重新训练或微调模型,并随着标注数据的增加和模型性能的提升,逐步降低不确定性阈值或提高代表性阈值,以选择更多有价值的样本进行标注;
7、s5、循环迭代阶段:重复步骤s2~s4,形成一个循环迭代的过程,并持续进行,直至达到预期的标注效果和模型性能;
8、s6、数据校验阶段:对自动标注和人工标注的数据进行校验,确保标注框数、标注数据量等符合校验规则。
9、进一步的,所述步骤s1中,所述数据清洗具体包括如下操作:
10、数据去重:比较图像的哈希值或特征向量,将相似度高的图像视为重复图像,进行删除,并根据文件名或图像元数据(如时间、地点、拍摄设备等)进行去重;
11、数据过滤:遍历数据集,使用is_image()函数确定每个文件是否为图片文件,将非图片文件删除,并尝试打开每个图片文件,使用image.open()和img.load()方法检测文件是否完好,如果文件无法打开则视为破损图片,进行删除或移动到破损图片目录,以及删除低质量、不标准、不合理的图像,如模糊、扭曲、尺寸过小或过大的图像;
12、数据修复:对于数据中出现的缺失、噪声、伪影问题,使用包括滤波、插值、去噪在内的图像处理技术进行修复。
13、进一步的,所述步骤s1中,数据预处理具体包括如下操作:
14、格式转换:将图像数据转换为深度学习模型更容易处理的格式,如将图像转换为rgb图像或灰度图像;
15、归一化:将图像的像素值缩放到[0,1]或标准化到一定的均值和标准差范围内;
16、数据增强:通过旋转(将图像按一定角度旋转)、平移(在图像平面上沿x或y方向移动图像)、缩放(改变图像的大小)和翻转(水平或垂直翻转图像),增加数据的数量和多样性;
17、数据集分割:将数据集按照比例分割为80%训练集、10%验证集、10%测试集。
18、进一步的,所述步骤s3中,样本选择策略具体包括:
19、不确定性采样:计算模型对每个未标注样本的预测概率或置信度,并选择置信度最低的样本进行标注;所述不确定性采样基于模型对样本的预测置信度来判断,选择模型最不确定的样本进行标注,若模型对某个样本的预测置信度很低,则说明该样本对模型来说很“难”,因此标注这样的样本可为模型提供更多的学习信息;
20、查询难度策略:训练若干不同的模型或使用同一模型的多个版本作为委员会成员,让每个成员对未标注样本进行预测,并选择预测结果差异最大的样本进行标注,通过比较不同模型的预测结果,可以选择出那些模型普遍难以处理的样本,从而提高模型的泛化能力;所述查询难度策略使用多个模型(或称为“委员会”)对未标注样本进行预测,并选择那些委员会成员之间预测差异最大的样本进行标注;
21、代表性采样:使用聚类算法或特征选择方法来确定未标注数据集中的代表性样本,具体操作为,先对未标注样本进行聚类,然后从每个聚类中选择一定数量的样本进行标注,或者根据样本的特征分布来选择具有代表性的样本;所述代表性采样策略旨在选择能够代表未标注数据集整体分布的样本,这意味着选出的样本应该能够覆盖数据集中的各种情况,包括不同类别、不同特征分布等;
22、混合策略:在实际应用中,可将不确定性采样、查询难度策略、代表性采样进行组合使用,形成混合策略;例如,可以先使用不确定性采样选择一部分样本进行标注,然后使用代表性采样策略补充一部分能够覆盖更多数据分布情况的样本。
23、进一步的,所述步骤s5中,在迭代过程中,定期使用验证集评估模型的性能,以调整标注策略和模型参数,具体包括如下流程步骤:
24、设置迭代周期:确定迭代的频率,例如每轮迭代训练模型后都进行一次验证,或者每隔几轮迭代进行一次验证;
25、模型训练:使用训练集对模型进行训练,并根据任务选择损失函数和优化算法,通过多次迭代优化模型参数;
26、验证模型:使用验证集对模型进行评估,计算模型在验证集上的性能指标,如准确率、召回率、精确率、f1值等;
27、分析评估结果:分析验证集的评估结果,找出模型表现不佳的地方;
28、调整标注策略:根据验证集的评估结果,调整标注策略;
29、调整模型参数:根据验证集的评估结果,调整模型的超参数,例如,调整学习率、批次大小、迭代次数等参数来优化模型的性能,或尝试不同的模型结构和算法来改进模型的性能;
30、重复迭代:将调整后的标注数据重新用于模型训练,重复上述步骤,不断迭代和优化模型,直到达到满意的性能为止。
31、进一步的,所述步骤s5中,在迭代过程中,记录每次迭代的训练时间、评估结果、参数调整信息,并使用监控工具或日志系统来跟踪模型的性能变化和参数调整情况。
32、进一步的,所述步骤s6中,校验采用自动化校验方式,具体为:利用包括python、pandas在内的编程语言和数据处理工具,编写脚本来自动检查数据的各项指标是否符合校验规则。
33、进一步的,所述步骤s6中,校验规则具体包括标注框数、标注数据量、数据格式和一致性、逻辑关系、边界值和异常值以及数据分布六个方面的校验,具体如下:
34、校验规则一:标注框数校验
35、图像数据集:确保每个标签的标注框数超过规定数量,例如至少10个标注框,这个规则用于确保模型能够充分学习到目标物体的特征;
36、校验规则二:标注数据量校验
37、文本数据集:
38、数据集中已标注数据量应超过设定阈值,如600条,这确保模型有足够的标注数据来训练;
39、每个标注标签的数据量应达到设定数量,如超过50条,这有助于模型更好地学习每个类别的特征;
40、未标注数据的数据量必须满足设定要求,如超过600条,这些数据可以用于后续的模型训练和评估;
41、校验规则三:数据格式和一致性校验
42、校验数据是否遵循统一的格式和标注标准,如标注框的坐标格式、标签的命名规则等;
43、确保数据的一致性,例如检查相同目标在不同图像中的标注是否一致;
44、校验规则四:逻辑关系校验
45、对于标注数据中的逻辑关系进行校验,例如句子中的主谓宾关系、词语之间的关联等;
46、校验规则五:边界值和异常值校验
47、检查标注数据中的边界值是否合理,如数字的大小范围、时间的合法性等;
48、检测并处理异常值,如异常的文本内容、异常的图像等;
49、校验规则六:数据分布校验
50、对于数值型数据,校验其分布是否合理,以避免标注数据的不平衡问题。
51、进一步的,还包括步骤:
52、s7、标注数据输出阶段:将通过校验的最终标注数据保存为标准的文件格式,如voc、coco等,或者根据具体需求使用json、xml等数据结构,并输出文件至指定位置。
53、进一步的,所述步骤s7中,输出文件的内容组成包括:图像文件的路径、图像大小、目标类别id、边界框坐标。
54、本发明提供了一种基于人机交互的半自动目标检测预标注方法,具备以下有益效果:
55、本发明通过引入主动学习技术,能够根据模型对样本的预测结果和不确定性选择出最有价值的样本,即最需要进行人工检查的样本,来进行人工标注,从而降低了人工标注的工作量,有利于降低标注成本、提升数据利用效率,并基于样本选择结果进行模型的循环迭代,直至达到预期的标注效果和模型性能,配合严密的校验规则以及自动校验方式,有助于进一步提升目标检测预标注的自动化程度和准确性。
- 还没有人留言评论。精彩留言会获得点赞!