基于检索增强的程序缺陷自动修复方法、系统、设备及可读存储介质
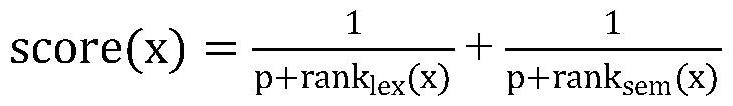
本发明属于计算机软件与人工智能,具体涉及一种基于检索增强的程序缺陷自动修复方法、系统、设备及可读存储介质。
背景技术:
1、程序缺陷自动修复(automated program repair,apr)是一项旨在通过自动化手段检测和修复软件缺陷的技术。随着软件系统的复杂性和规模的增加,手动修复程序缺陷变得越来越耗时且易出错,因此apr在这一领域的应用显得尤为重要。现阶段,apr技术在学术界和工业界均取得了显著进展,主要包括基于预定义规则的修复方法、基于机器翻译的修复方法和基于语言模型的修复方法。
2、基于预定义规则的修复方法利用程序的语义信息进行缺陷修复。此类方法利用符号执行和约束求解技术生成符合语义的补丁,pyter是此类方法的代表。然而,这类方法通常依赖于程序的精确语义信息,应用范围较为受限,且计算复杂度高。
3、基于机器翻译的修复方法通过训练一个翻译模型,将输入的错误代码翻译成正确代码,coconut是此类方法的代表。然而,这些模型需要经过大量数据的训练,它们在面对新类型的错误或未见过的代码片段时,生成正确补丁的能力较差。
4、近年来,基于语言模型的修复方法逐渐成为研究热点。通过训练大规模预训练语言模型,这些方法能够从大量历史修复实例中学习补丁生成的规律,如codex等在代码生成和理解方面展现了强大的能力,为apr技术带来了新的契机。现阶段基于语言模型的修复方法是通过将存在缺陷的程序及其上下文输入到语言模型中,输出修复后的代码,alpharepair是此类方法的代表。然而,语言模型的上下文窗口是有限的,这使得语言模型允许输入的最大代码长度往往小于实际的缺陷程序代码及其上下文的代码长度,导致模型很难充分利用原程序代码文件中与修复缺陷相关的上下文信息,因此在处理长代码片段时存在修复成功率较低的问题。
技术实现思路
1、本发明为解决上述技术问题,提出一种基于检索增强的程序缺陷自动修复方法、系统、设备及可读存储介质。
2、本发明采用如下技术方案:
3、一种基于检索增强的程序缺陷自动修复方法,包括以下步骤:
4、步骤s1、收集修复模板,构建修复模板数据库;
5、步骤s2、从修复模板数据库中检索匹配的修复模板;
6、步骤s3、计算上下文代码行与错误代码行的词法相似度和语义相似度;
7、步骤s4、基于互相关排名融合策略,生成代码行的综合相似度排名列表;采用互相关排名融合策略,将词法相似度和语义相似度相结合,生成综合相似度排名列表;具体计算公式如下:
8、
9、其中,score(x)表示特定代码行x的综合相似度分数,ranklex(x)表示特定代码行x在词法排名列表中的位置,ranksem(x)表示特定代码行x在语义排名列表中的位置;p是常数参数,通常取值为60。
10、步骤s5、基于综合相似度排名列表,从相似代码行中提取候选标识符;
11、步骤s6、构建基于上下文增强的修复提示;并将修复提示输入到语言模型中生成候选补丁;
12、步骤s7、候选补丁验证;对生成的候选补丁进行代码语法检查,移除包含语法错误的候选补丁;对没有语法错误的候选补丁执行测试套件,识别通过测试套件的正确补丁,输出所述补丁,完成修复。
13、进一步地,所述步骤s1具体为:
14、从开源代码仓库中自动收集包含程序缺陷的代码片段及其对应的修复代码片段;
15、从收集到的代码片段中提取修复模板。这些模板通过分析历史修复实例,记录修复模板,并将其组织成修复模板数据库。
16、进一步地,所述的步骤s2具体为:
17、对存在缺陷的代码生成抽象语法树,分析代码结构和错误位置;
18、在修复模板数据库中检索与错误代码匹配的修复模板;通过遍历抽象语法树的所有节点,匹配修复模板数据库中的模板,并根据模板在开源仓库中的实例出现频率进行优先级排序。
19、进一步地,所述的步骤s3具体为:
20、步骤s31:提取包含缺陷代码的程序文件,并将程序文件中的代码以行为单位拆分为代码行,作为基本检索单元;
21、步骤s32:计算词法相似度:采用bm25算法计算错误代码行与其他代码行的词法相似度,具体公式为:
22、
23、其中,q是查询,即缺陷代码行;d是程序文档,即程序文件中除去缺陷代码之外的其他代码行;qi是查询中的第i个词;f(qi,d)是词qi在文档d中的出现频率;|d|是文档d的长度;avgdl是所有文档的平均长度;k1和b是调节参数,取k1=1.2,b=0.75;idf(qi)是词qi的逆文档频率,定义为:其中n是文档总数,n(qi)是包含词qi的文档数;利用bm25算法,计算错误代码行与其他代码行的词法相似度,并生成基于词法检索模块的相对排名列表ranklex;
24、步骤s33:计算语义相似度:使用代码语义搜索模型计算错误代码行与其他代码行的语义相似度;
25、步骤s331:对每个代码行通过bert模型编码器生成一个嵌入向量,即vi=ep(ci),其中ep(ci)表示代码行ci的编码向量;
26、步骤s332:对错误代码行通过独立的bert模型网络进行编码,生成查询向量vq;
27、步骤s333:使用向量内积计算查询向量与所有代码行向量之间的语义相似度:其中,vq是错误代码行的查询向量,vp是代码行的嵌入向量;
28、步骤s334:根据语义相似度,检索与错误代码行最相似的代码行,并生成基于语义检索模块的相对排名列表ranksem。
29、进一步地,所述的步骤s5具体为:
30、从综合相似度排名列表中的每行代码中提取标识符;
31、应用静态分析,去除在错误方法上下文中不可访问的标识符,生成一个从代码行中提取的候选代码标识符的排名列表。
32、进一步地,所述的步骤s6具体为:
33、步骤s61:基于步骤s2检索得到的修复模板信息和步骤s5检索得到的候选标识符信息构建修复提示;
34、步骤s611:模板检索信息部分表示在步骤s2检索到的修复模板应用于给定错误代码片段后的结果;占位符<infill>向模型指示根据应用的模板生成新代码的精确位置;
35、步骤s612:上下文检索信息部分,[donor]表示在步骤s5检索到的候选代码标识符;
36、步骤s62:在输入提示的开头添加原始错误代码行作为注释,并将缺陷代码行之前和之后的上下文信息包含在修复提示中;从缺陷代码行开始,并逐步扩展上下文大小,直到模型的最大输入长度;
37、步骤s63:将在步骤s62构建完成的修复提示到语言模型中,使用语言模型的输出内容替换修复提示中的占位符,生成候选补丁。
38、本发明还涉及一种基于检索增强的程序缺陷自动修复方法系统,应用上述的方法。
39、本发明还涉及一种计算机设备,包括存储器和处理器,所述存储器存储有计算机程序,所述处理器执行所述计算机程序时实现上述方法的步骤。
40、本发明还涉及一种计算机可读存储介质,其上存储有计算机程序,所述计算机程序被处理器执行时实现上述方法的步骤。
41、有益效果
42、本发明提供了一种基于检索增强的程序缺陷自动修复方法,在修复程序缺陷方面具有显著的有益效果,与现有技术相比,具有以下优势:
43、1、综合利用修复模板和上下文信息:现有的自动程序修复技术通常依赖于单一的信息来源,而本发明通过检索增强策略,全面利用了开源代码仓库中的修复模板和本地程序文件中的代码上下文,有效地提高了修复提示的准确性和普适性。
44、2、高效的修复模板提取和匹配:通过自动从开源代码仓库中提取修复模板并生成修复模板数据库,本发明避免了手动收集和整理修复模板的繁琐过程。同时,利用抽象语法树进行模板匹配,并根据模板在开源仓库中的实例出现频率进行优先级排序,确保了匹配修复模板的高效性和实用性。
45、3、多维度相似度分析:本发明在检索本地上下文信息阶段结合了词法相似度和语义相似度,通过互相关排名融合策略生成综合相似度排名列表。相较于只使用单一相似度指标的方法,本发明能够从编程语言词法和语义的双重维度更准确地找到与错误代码行相似的代码行,从而提取出更为相关的修复标识符,提高了修复的精确度。
46、4、上下文增强的修复提示生成:本发明生成的修复提示不仅包含从历史修复提交代码检索到的抽象修复模板,还结合了从本地代码文件检索到的具体修复标识符,并且包含错误代码行的前后上下文信息。这种基于上下文增强的修复提示能够更好地引导语言模型生成高质量的修复补丁。
47、综上所述,本发明通过创新性地结合历史修复模板检索和本地相关代码检索,利用多维度相似度分析和静态分析技术,生成上下文增强的修复提示,并通过自动化验证机制确保补丁的有效性。本发明能够自动生成高质量的代码修复补丁,显著提升了程序错误修复的自动化程度和准确性,减少了开发人员的工作量,并提高了软件的可靠性和稳定性。相比现有技术,具有显著的优势和实用价值。
- 还没有人留言评论。精彩留言会获得点赞!