一种SaaS软件服务请求负载均衡方法、介质、设备
本发明涉及软件服务,尤其涉及一种saas软件服务请求负载均衡方法、介质、设备。
背景技术:
1、saas(software as a service,软件即服务)软件提供商将多租户请求合理地分配给现有虚拟资源并快速达到负载均衡状态的智能化服务决策调度,以及衡量saas软件服务器集群达到负载均衡状态的评价指标,都是现阶段saas软件研究的关键问题。目前,saas软件负载均衡相关技术大致分为以下三类:
2、(1)传统算法。常用的传统负载均衡策略主要包括最小最小、最大最小、轮询、最短作业优先,两阶段等调度算法。传统的云服务负载均衡策略一般归类于静态负载均衡技术,通常无法检测到所连接的服务器,没有考虑系统的当前状态,从而导致资源分布不均匀,无法解决saas软件动态变化的服务请求问题。
3、(2)启发式算法。启发式负载均衡算法主要指的是一些受自然现象启发的负载均衡技术,如遗传算法、人工蜂群算法、蚁群算法和粒子群算法。但这些算法及其采用的云服务负载均衡的相关评价指标是否适用于saas软件负载均衡场景,尚没有过多研究。
4、(3)深度强化学习算法。深度强化学习算法主要包括强化学习算法和深度强化学习算法。强化学习算法主要指基于值函数、基于策略、基于值函数和策略混合的强化学习算法。首先,深度强化学习策略是否适合saas软件负载均衡场景且在此场景下效果是否优于传统调度算法,何种深度强化学习算法在对saas软件运行负载合理分配的过程中更能满足用户深度强化学习协议,在现阶段都没有过多研究。其次,使用dqn算法进行云服务调度过程中,智能体在进行q值更新时往往出现“高估”问题;使用ddqn算法虽然巧妙解决了上述问题,但是该算法很容易陷入局部最优,并且一旦陷入局部最优则需要大量的数据进行纠正,甚至导致假最佳动作价值函数的出现。
技术实现思路
1、本发明的目的在于:为了解决现有技术无法很好地进行saas软件负载均衡场景的问题,提出一种saas软件服务请求负载均衡方法,包括以下步骤:
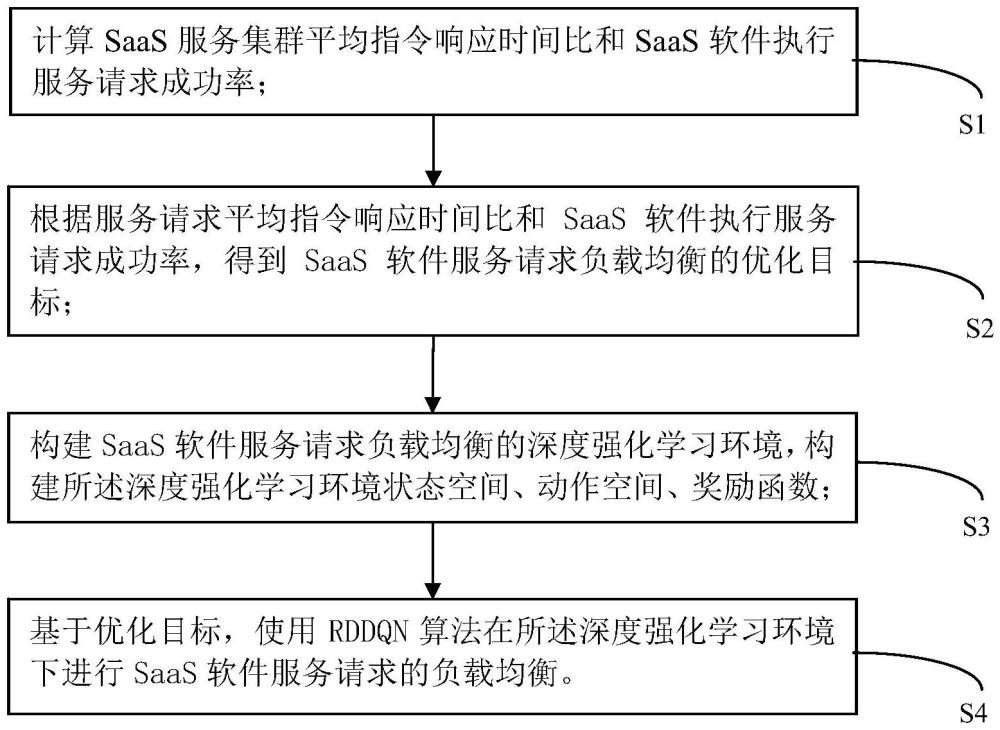
2、s1、计算saas服务集群平均指令响应时间比和saas软件执行服务请求成功率;
3、s2、根据服务请求平均指令响应时间比和saas软件执行服务请求成功率,得到saas软件服务请求负载均衡的优化目标;
4、s3、构建saas软件服务请求负载均衡的深度强化学习环境,构建所述深度强化学习环境状态空间、动作空间、奖励函数;
5、s4、基于优化目标,使用rddqn算法在所述深度强化学习环境下进行saas软件服务请求的负载均衡。
6、进一步地,计算saas服务集群平均指令响应时间比具体为:
7、计算服务请求基于虚拟资源的指令响应时间比:
8、
9、其中,vtij表示第i个服务请求基于第j个虚拟资源的指令响应时间比,servicesizei表示第i个服务请求的数据大小;表示第i个服务请求被第j个虚拟资源响应的持续时间;
10、计算虚拟资源的平均指令响应时间比:
11、
12、其中,avgvtj表示第j个虚拟资源的平均指令响应时间比,i表示第j个虚拟资源的服务请求数量;
13、计算saas服务集群平均指令响应时间比:
14、
15、其中,avgvt表示saas服务集群平均指令响应时间比,j表示虚拟资源数量。
16、进一步地,saas软件执行服务请求成功率表示为:
17、
18、其中,successij表示saas软件第j个虚拟资源执行第i个服务请求的成功率,表示第i个服务请求被第j个虚拟资源响应的持续时间,deadtimei表示第i个服务请求在saas软件中最长的持续时间。
19、进一步地,所述优化目标为:
20、
21、优化目标的约束条件为:
22、
23、其中,π代表负载均衡算法,α、β表示权重系数,j表示虚拟资源数量,i表示第j个虚拟资源的服务请求数量,successii表示saas软件第j个虚拟资源执行第i个服务请求的成功率。
24、进一步地,状态空间定义为:
25、
26、其中,stateij表示深度强化学习环境的第i个服务请求基于第j个虚拟资源的状态,servicesizei表示第i个服务请求的数据大小,deadtimei表示第i个服务请求在saas软件中最长的持续时间,分别表示第i个服务请求选择第1,2,...,j个虚拟资源要等待的时间。
27、进一步地,动作空间定义为:
28、
29、其中,actionij表示表示深度强化学习环境的第i个服务请求基于第j个虚拟资源的动作,vm1,vm2,…,vmj,…,vmj分别表示第1,2,...,j,...,j个虚拟资源。
30、进一步地,奖励函数定义为:
31、
32、其中,rewardij表示深度强化学习环境的第i个服务请求基于第j个虚拟资源的奖励函数,α表示超参数,avgvt表示saas服务集群平均指令响应时间比,successij表示saas软件第j个虚拟资源执行第i个服务请求的成功率。
33、进一步地,s4具体为:
34、s41、初始化rddqn算法和所述深度强化学习环境的参数;
35、s42、获取智能体迭代回合中迭代步数,当前状态st,使用ε-greedy贪心策略获取当前动作at;
36、s43、通过动作at与环境进行交互得到对应奖励rt以及下一个状态st+1;判断迭代步数是否为1,迭代步数为1的话返回步骤s41,迭代步数不为1的话将四元组(st,at,rt,st+1)存入回放内存中;
37、s44、训练并更新评估网络和目标网络,判断智能体是否需要学习,需要学习的话继续判断是否需要将评估网络q的参数θ复制给目标网络q’的参数θ′,需要参数复制的话在回放内存中随机抽取小批量抽样δ大小的四元组(st,at,rt,st+1),并使用δ大小的四元组交替使用q值计算yt来拟合评估网络q值,并通过损失函数计算梯度,使用反向传播方式对当前评估网络进行参数θ更新,不需要参数复制或不需要学习的话返回步骤s43,一回合结束;
38、计算yt的表达式为:
39、
40、其中,yt表示目标q值;rt表示t时间步获得的即时奖励;γ表示折扣因子;q(st+1,argmaxaq′(st+1,θ′),θ)表示评估网络q在状态为st+1,动作为argmaxaq′(st+1,θ′),参数为θ时的输出;q′(st+1,θ′)表示目标网络q’在状态为st+1,参数为θ′时的输出;
41、通过损失函数计算梯度,其中的损失函数表达式为:
42、loss=(yt-q(st,a,θ))2
43、其中,loss表示损失函数,q(st,a,θ)表示评估网络q在状态为st,动作为a,参数为θ时的输出。
44、s45、循环迭代n个回合后结束整个过程。
45、本发明还提出一种计算机可读存储介质,所述计算机可读存储介质存储有计算机程序,所述计算机程序被处理器执行时实现上述的saas软件服务请求负载均衡方法。
46、本发明还提出一种电子设备,包括处理器和存储器,所述处理器与所述存储器相互连接,其中,所述存储器用于存储计算机程序,所述计算机程序包括计算机可读指令,所述处理器被配置用于调用所述计算机可读指令,执行上述的saas软件服务请求负载均衡方法。
47、本发明提供的技术方案带来的有益效果是:
48、本发明通过构建saas软件服务请求负载均衡的深度强化学习环境,构建环境的状态空间、动作空间、奖励函数;基于负载均衡的优化目标,使用rddqn算法在深度强化学习环境下进行saas软件服务请求的负载均衡。rddqn引入双网络结构,交替使用评估网络q与目标网络q’计算下一个实际q值,对q值迭代更新关联性进行弱化处理,使得评估网络q与目标网络q'的变化趋势异步,避免了智能体与环境交互过程中q值出现的“高估”问题,弱化在某一步中智能体陷入局部最优的趋势。rddqn引入经验回放机制,在智能体学习过程中,将与环境交互得到的数据先存到回放记忆单元中,在离线训练时,利用随机采样的方法从回放记忆单元中选取数据,有效地减小了数据之间的相关性,加速算法训练时的收敛速度。
- 还没有人留言评论。精彩留言会获得点赞!