一种改进YOLOv8的小目标人脸检测方法
本发明涉及人脸检测的,尤其涉及一种改进yolov8的小目标人脸检测方法。
背景技术:
1、伴随着现代深度学习模型的不断发展,检测模型主要分为一阶段算法和二阶段算法,都已经能够在大规模数据集中训练并学习人脸的特征表示,实现高准确率的人脸检测。但由于计算资源的有限以及实时性要求,并且随着模型更多的部署在移动设备,计算量较小且速度更快的一阶段算法逐渐成为目标检测领域的研究热点。常用的一阶段算法包括yolo(you only look once)系列、ssd(single shot multibox detector)等。
2、随着计算机视觉和图像处理技术的进步,人脸检测技术被不断地应用到各大场景当中,例如,在安防监控、人机交互、交通道路、智能考勤等方面,人脸检测都发挥着关键作用。同时,很多与人脸检测密切相关的技术都是当下的研究热点,如人脸识别、人脸定位等,这表明一个人脸检测算法的准确性和高效性对于推动这些技术的发展至关重要。然而,这些算法在人脸检测过程中所要考虑的各种因素也随之而来。例如,当光线不足或太强时都会导致图像的质量下降,从而影响人脸特征的清晰度,分辨率低、尺寸小的图像也会丢失掉很多人脸的细节信息,同时,人脸的偏转角度变化以及各种姿态对于提取人的面部特征也会造成困扰,模型常常会因为关注不到这些细小的特征从而忽视这些人脸,导致漏检或误检,更多的因素还有遮挡、背景混乱等等,这导致想要更准确的定位人脸位置仍面临着巨大的挑战。
3、公开号为cn117437407 a的发明专利,基于yolov8的自动驾驶小目标检测模型,包括步骤1:选取soda10m数据集,对其中已经标注的数据进行划分,划分为训练集、验证集、测试集。步骤2:构建改进的yolov8网络结构,其中包括添加注意力机制、改进目标检测层、设计目标检测头,用于特征提取和目标检测。步骤3:在训练集上进行模型训练,采用梯度下降算法和反向传播技术,优化神经网络参数,以最大程度提高小目标检测的准确性。步骤4:利用验证集对训练后的模型进行验证和调优,以确保模型的泛化性能和鲁棒性。步骤5:在测试集上对训练和验证后的模型进行测试,以评估其在自动驾驶场景中对小目标物体的检测性能。但此发明方法模型参数较多且在捕捉更小的细节方面仍存在不足,难以有效的提取到小目标的特征。
技术实现思路
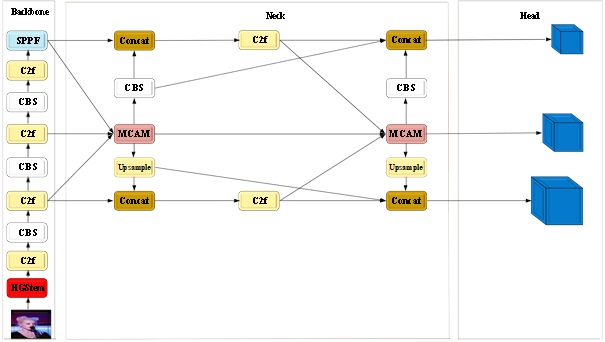
1、针对现有的小目标检测方法对遮挡、复杂背景、小尺寸等原因造成的难以有效的提取到小目标的特征的技术问题,本发明提出了一种改进yolov8的小目标人脸检测方法,提出了一种小目标人脸检测模型yolov8-pha,通过引入高效提取特征模块(hgstem)、多卷积聚合模块(mcam)和新的聚合扩散金字塔网络(adpn),在降低模型参数量的同时,也能够提高复杂场景下小目标人脸检测的准确率。
2、为了达到上述目的,本发明的技术方案是这样实现的:
3、一种改进yolov8的小目标人脸检测方法,包括步骤:
4、s1:选取widerface数据集,得到划分好的训练集和验证集;
5、s2:构建yolov8-pha模型,包括依次连接的骨干网络、颈部网络和头部网络,在骨干网络中引入hgstem模块,在颈部网络中引入结合mcam模块的adpn网络结构;
6、s3:进行小目标人脸样本锚框检测优化;
7、s4:利用训练集对构建的yolov8-pha模型进行训练;在验证集上运行训练后的yolov8-pha模型,并进行参数调整,
8、s5:重复s4直到达到训练要求或者训练轮次,得到训练好的yolov8-pha模型;
9、s6:在widerface数据集的验证集上运行训练好的yolov8-pha模型,得到最终评估检测结果。
10、步骤s3所述的进行小目标人脸样本锚框检测优化的方法为:利用骨干网络对输入图像x进行特征提取,得到三个尺度的输入特征,颈部网络中利用adpn网络结合mcam模块对三个尺度的输入特征进行融合,得到三个尺度的特征输出图,根据特征输出图中的位置信息聚类得到锚框,根据锚框和真实目标框的交集除以二者的并集得到iou值,利用头部网络对三个尺度的特征输出图进行回归和分类操作,预测每个锚框的边界框回归值和目标存在的置信度,利用iou值和置信度计算锚框对齐度量t,利用taskalignedassigner的执行程序将锚框对齐度量t值调整为最适合小目标人脸检测的数值。
11、所述锚框对齐度量t的计算方法为:t=sα×uβ,其中,s表示置信度,u表示为iou值,α和β为控制参数。
12、步骤s4所述的利用训练集对构建的yolov8-pha模型进行训练的过程为:利用骨干网络对输入图像x进行特征提取,得到三个尺度的输入特征,颈部网络中利用adpn网络结合mcam模块对三个尺度的输入特征进行融合,得到三个尺度的特征输出图,头部网络对三个尺度的特征输出图进行最终的回归和分类操作,预测每个锚框的边界框回归值和目标存在的置信度,利用回归预测值对锚框进行调整,生成最终的预测框。
13、所述的利用骨干网络对输入数据进行特征提取的方法为:输入图像x首先经过起始层hgstem模块提取特征信息,将特征信息传递给c2f模块,通过cbs卷积层使用卷积操作将输入图像x的尺寸减半,接着依次经过多个c2f模块+cbs卷积层的操作,经过最后一个c2f模块,最后经过sppf层的特征提取、池化和融合操作,最终输出小尺寸特征信息x3、中尺寸特征信息x4和大尺寸特征信息x5。
14、所述hgstem模块的计算过程为:输入图像x通过conv1卷积层,得到特征图hg1,使用fpad函数对特征图hg1进行边缘填充,得到边缘填充后的特征图hg2,再经过conv2a卷积层和边缘填充后,进入到conv2b卷积层,得到特征图hg3;边缘填充后的特征图hg2经过最大池化层pool,得到特征图hg4;最后特征图hg3和特征图hg4进行通道维度上的拼接,并经过conv3卷积层和conv4卷积层将特征信息输出。
15、利用adpn网络结合mcam模块对三个尺度的输入特征进行融合的方法为:adpn网络分为前后两部分,在第一部分中,小尺寸特征信息x3、中尺寸特征信息x4和大尺寸特征信息x5被输入进颈部网络中的第一个mcam模块中提取到特征p,随后分为两个步骤,第一个步骤为:通过对特征p进行一个卷积操作后得到特征z5,特征z5与大尺寸特征信息x5的进行聚合,聚合后的特征a经过c2f模块a得到特征y5;第二个步骤为:对特征p进行下采样操作后得到特征z3,特征z3与小尺寸特征信息x3的进行聚合,聚合后的特征b同样经过c2f模块b得到特征y3;
16、在第二部分中,特征y3、特征p和特征y5被输入进颈部网络中的第二个mcam模块中提取到特征p2,随后分为两个步骤:第一个步骤为对特征p2进行一个卷积操作后得到特征c5,特征c5、特征y5和特征z5进行聚合,聚合后的特征c经过c2f模块c得到大尺寸的特征输出图h5,第二个步骤为对特征p进行下采样操作后得到特征c3,特征c3、特征y3和特征z3进行聚合,聚合后的特征d同样经过c2f模块d得到小尺寸的特征输出图h3;特征y5、特征y3和特征p经过第二个mcam模块得到中尺寸的特征输出图h4。
17、所述第一个mcam模块的计算过程为:输入的小尺寸特征信息x3、中尺寸特征信息x4和大尺寸特征信息x5分别经过不同的卷积操作,捕获三个尺度上的局部信息,将三个尺度上的局部信息进行合并操作,得到局部特征l,局部特征l经过一个恒等映射和m个并行的深度卷积获取到m个尺度的上下文特征z(m)和恒等映射后的局部特征l,再经过一个卷积操作整合m个尺度的上下文特征z(m)和恒等映射后的局部特征l,最后将整合后的特征与局部特征l进行聚合得到最终的输出特征p。
18、所述局部特征l的计算过程为:
19、l=convx5+convx4+adownx3
20、其中conv为卷积操作,adown为下采样操作;
21、所述经过m个并行的深度卷积获取到m个尺度的上下文特征的方法为:
22、
23、其中,z(m)为每个尺度的上下文特征,dwconv指的是深度卷积操作,k(m)表示卷积核大小;
24、所述最终的输出特征p的获取过程为:
25、
26、在验证集上运行训练后的yolov8-pha模型的具体方法为:输入验证集,运行训练后的yolov8-pha模型,将yolov8-pha模型得到预测框与真实目标框进行比较,通过计算预测框与真实目标框之间的重叠程度,确定预测框的真假,然后基于预测框的真假,计算精确率-召回率曲线的面积。
27、本发明的有益效果:
28、本发明首先,提出小目标人脸样本锚框检测优化,旨在引入更多高质量的人脸锚框来增大对小目标人脸样本的检测力度;其次,引入了高效提取特征模块(hgstem),利用残差结构以及最大池化层的优势减少了模型训练初期对困难人脸样本特征信息的丢失,同时提高特征图的质量和多样性;再者,设计了一种多卷积聚合模块(mcam),采用三个输入尺度来更好的聚合不同尺寸大小的特征信息,并利用一组并行深度卷积来捕获丰富的跨多个尺度的信息;最后,在多卷积聚合模块(mcam)的基础上提出了一种新的聚合扩散金字塔网络(adpn),其较强的灵活性和适应性能够更好的处理不同尺寸的人脸图像。
29、实验结果表明,改进后的yolov8-pha模型在wider face数据集的easy、medium、hard三个级别下的检测精度分别达到94.77%、93.53%和83.71%,检测结果均优于原始网络。yolov8-pha模型可以满足复杂环境下对小目标人脸检测的要求。在widerface数据集的实验结果显示改进方法提高了检测精度,减少了网络的参数,展现了本发明yolov8-pha模型具有较好的先进性和稳健性。
- 还没有人留言评论。精彩留言会获得点赞!